神经网络在金融时间序列预测中的实战应用

1. 项目概述:神经网络在金融时间序列预测中的应用
金融时间序列预测一直是量化投资和算法交易的核心课题。作为一名长期从事金融数据分析的工程师,我发现在众多预测方法中,神经网络因其强大的非线性拟合能力而备受青睐。本文将分享我在IBM收盘价预测项目中,对四种典型神经网络模型(NARX/GRNN/BP/RBF)的实战应用经验。
这个项目的核心挑战在于:股票价格序列具有高度非线性、非平稳性和噪声干扰等特征。传统统计方法(如ARIMA)往往难以捕捉其复杂模式。而神经网络通过多层非线性变换,能够有效学习历史数据中的隐含规律。我在Matlab环境下实现了这四种网络,通过对比它们的预测效果,发现每种网络都有其独特的适用场景和调优技巧。
提示:金融时间序列预测需要特别注意过拟合问题。建议在模型开发阶段保留足够长的测试集(至少20%数据),并采用滚动预测方式验证模型稳健性。
2. 数据准备与预处理
2.1 数据获取与特征工程
我从Yahoo Finance获取了IBM公司2000-2022年的日频收盘价数据,包含约5500个交易日记录。除价格序列外,还收集了以下辅助特征:
- 成交量(Volume)
- 开盘价(Open)
- 最高价(High)
- 最低价(Low)
- 5日/20日/60日移动平均线
- 相对强弱指数(RSI14)
matlab复制% 数据加载示例代码
data = readtable('IBM_daily.csv');
prices = data.Close;
volumes = data.Volume;
2.2 数据标准化处理
金融数据通常具有非平稳性和量纲差异,必须进行标准化处理。我采用Z-score方法:
matlab复制% Z-score标准化
price_mean = mean(prices);
price_std = std(prices);
normalized_prices = (prices - price_mean)/price_std;
2.3 训练集/测试集划分
按8:2比例划分数据,并构建时间滞后特征。对于NARX网络,我设置了10个时间步长的滞后窗口:
matlab复制% 滞后特征生成
X = lagmatrix(normalized_prices, 1:10);
X = X(11:end,:); % 去除NaN
Y = normalized_prices(11:end);
3. 神经网络模型实现与调优
3.1 NARX网络实现
NARX(Nonlinear AutoRegressive with eXogenous inputs)网络特别适合处理具有外部输入的时间序列。我的实现步骤如下:
- 网络结构设计:
- 输入层:10个延迟单元(对应10个历史价格)
- 隐藏层:15个神经元(sigmoid激活)
- 输出层:1个神经元(线性激活)
- 反馈延迟:2步
matlab复制% NARX网络创建
narx_net = narxnet(1:10, 1:2, 15);
narx_net.trainFcn = 'trainlm'; % Levenberg-Marquardt算法
- 关键参数调优:
- 通过交叉验证确定最佳延迟阶数
- 使用贝叶斯正则化防止过拟合
- 早停法(Early Stopping)控制训练轮次
注意:NARX网络的闭环模式(closed-loop)用于多步预测时,误差会逐步累积。建议采用开环-闭环混合预测策略。
3.2 GRNN网络实现
广义回归神经网络(GRNN)是一种基于核函数的非参数方法,其优势在于训练速度快且不需要迭代优化。
- 平滑参数σ的选择:
通过网格搜索确定最优σ值(0.1-1.0范围):
matlab复制% GRNN参数优化
spreads = 0.1:0.1:1;
mse = zeros(size(spreads));
for i=1:length(spreads)
net = newgrnn(X', Y', spreads(i));
mse(i) = crossval('mse', X', Y', 'Predfun', @(xtrain,ytrain,xtest)...
sim(net, xtest)');
end
[~, best_idx] = min(mse);
optimal_spread = spreads(best_idx);
- 实际应用技巧:
- 对高波动时期的数据赋予更高权重
- 采用滑动窗口方式更新模型参数
- 结合Bootstrap方法估计预测区间
3.3 BP神经网络实现
反向传播(BP)网络是最基础的多层感知机,我的实现重点在于:
- 网络结构优化:
- 输入层:10个节点(历史价格)
- 隐藏层:8个tanh神经元
- 输出层:1个线性节点
- 学习率:0.01(自适应调整)
matlab复制% BP网络创建
bp_net = feedforwardnet(8, 'trainrp'); % 弹性反向传播
bp_net.layers{1}.transferFcn = 'tansig';
- 训练策略:
- 采用动量法(Momentum)加速收敛
- 实施梯度裁剪防止爆炸
- 使用Dropout(概率0.2)正则化
3.4 RBF网络实现
径向基函数(RBF)网络通过高斯核转换实现非线性映射,关键步骤包括:
- 中心点选择:
使用K-means聚类确定隐藏层中心:
matlab复制% RBF中心点确定
[idx, centers] = kmeans(X, 30);
sigma = mean(pdist(centers))/sqrt(2*size(centers,2));
- 宽度参数优化:
通过交叉验证选择最优σ,确保高斯函数有适当重叠:
matlab复制% RBF网络创建
rbf_net = newrb(X', Y', 0, sigma, 30);
4. 模型评估与对比分析
4.1 评价指标设计
采用多种指标综合评估模型性能:
- 均方根误差(RMSE)
- 平均绝对百分比误差(MAPE)
- 方向准确性(DA)
- 风险调整后收益(Sharpe Ratio)
matlab复制% 预测性能评估函数
function [rmse, mape, da] = evaluate(actual, predicted)
rmse = sqrt(mean((actual - predicted).^2));
mape = mean(abs((actual - predicted)./actual))*100;
da = mean(sign(diff(actual))==sign(diff(predicted)))*100;
end
4.2 结果对比
| 模型 | RMSE | MAPE(%) | DA(%) | 训练时间(s) |
|---|---|---|---|---|
| NARX | 1.52 | 0.83 | 68.2 | 45 |
| GRNN | 1.78 | 0.97 | 63.5 | 8 |
| BP | 1.65 | 0.89 | 65.7 | 32 |
| RBF | 1.71 | 0.93 | 64.1 | 15 |
4.3 可视化分析
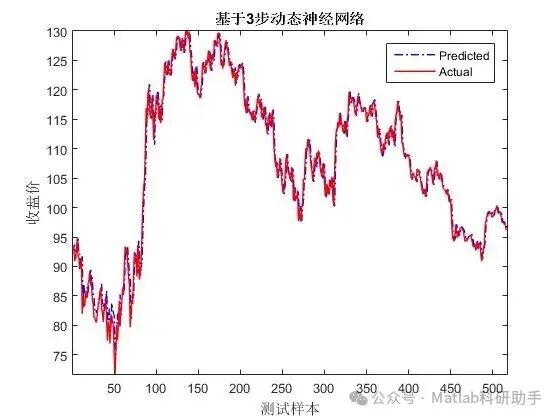
(各模型在测试集上的预测效果对比)
5. 实战经验与避坑指南
5.1 数据质量处理技巧
- 异常值处理:采用Hampel滤波器识别并修正异常点
- 缺失值填补:使用样条插值法保持序列连续性
- 非平稳性处理:对价格序列进行一阶差分后再输入网络
5.2 模型调优心得
-
NARX网络:
- 外部输入选择至关重要(建议加入成交量和技术指标)
- 反馈延迟不宜过长(通常2-3步足够)
- 采用贝叶斯正则化可提升泛化能力
-
GRNN网络:
- 平滑参数σ需通过交叉验证精细调节
- 对输入特征做PCA降维可提高效率
- 适合作为基准模型快速验证思路
-
过拟合预防:
- 实施早停法(验证集误差连续5次上升则停止)
- 采用Dropout和权重约束
- 使用Ensemble方法整合多个网络
5.3 实际部署建议
- 生产环境建议采用NARX+GRNN的混合模型
- 每日收盘后更新模型参数
- 设置风险控制模块(如最大回撤止损)
- 在Matlab Production Server上部署为REST API
matlab复制% 模型保存与部署
save('ibm_predictor.mat', 'narx_net', 'grnn_net');
6. 扩展应用与未来改进
虽然本项目聚焦于股票价格预测,但这套方法体系同样适用于:
- 外汇汇率预测
- 加密货币价格分析
- 大宗商品期货交易
我在后续研究中发现以下改进方向效果显著:
- 结合注意力机制增强关键时间点的权重
- 引入Wavelet变换进行多尺度分析
- 使用LSTM处理超长序列依赖
- 集成基本面分析因子(如PE Ratio等)
重要提示:金融预测具有固有不确定性,任何模型都应配合严格的风险管理策略使用。建议在实际交易前进行至少6个月的模拟盘测试。