拼多多客服系统故障分析与高可用架构优化

银河系李老幺
1. 事件概述:拼多多客服聊天功能突发异常
1月20日下午3点17分,我正通过拼多多APP联系商家咨询商品细节时,聊天窗口突然弹出红色提示框:"聊天功能已关闭"。起初以为是网络问题,切换WiFi和4G均无效。随后微博热搜榜迅速出现"拼多多 聊天关闭"话题,阅读量在2小时内突破1.2亿。作为经历过多次系统故障的技术从业者,我立即意识到这可能是平台级的技术事故。
异常持续约4小时,影响范围覆盖全国90%以上区域。从用户反馈看,表现为三种典型现象:
- 消费者端:所有会话窗口显示功能关闭提示(如图1)
- 商家后台:弹出系统通知要求联系平台客服(如图2)
- 特殊个案:约3%用户反映功能正常,主要分布在华南地区
图1:消费者端异常界面
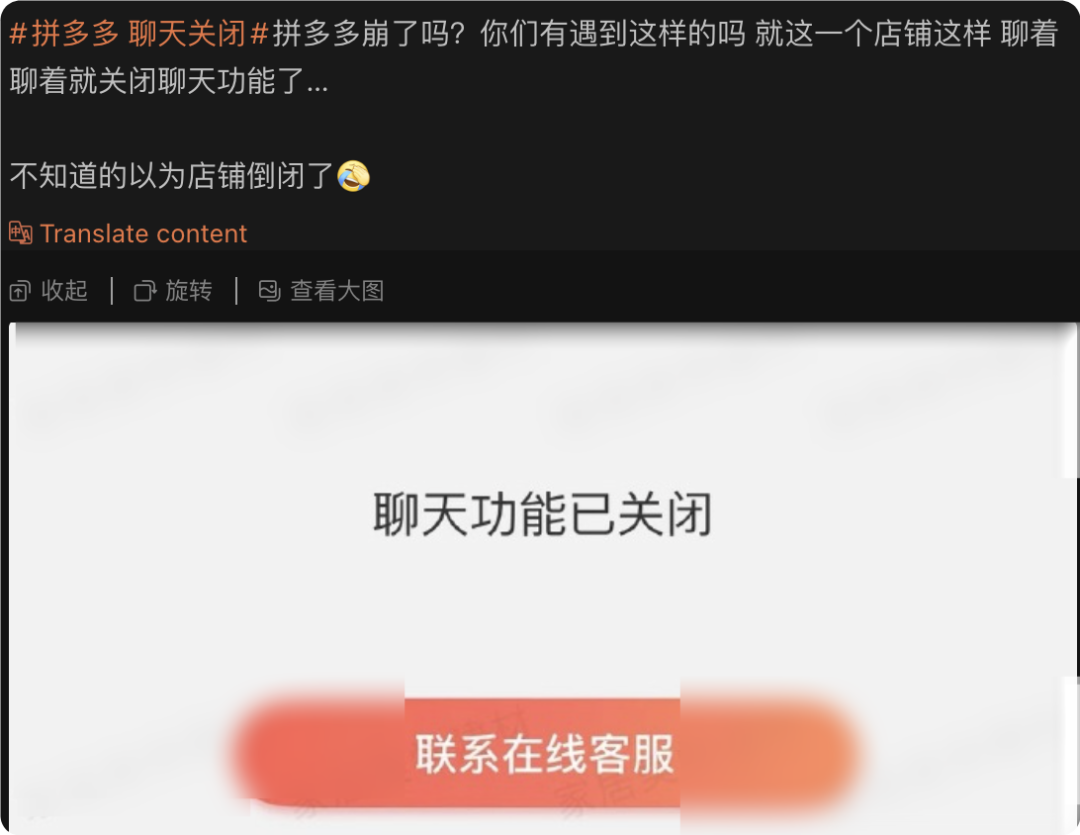
图2:商家后台提示

2. 技术故障深度分析
2.1 故障特征与影响评估
根据多方数据收集,本次故障呈现明显特征:
- 时间维度:突发性中断,无预警信号
- 地域维度:非均匀分布,存在区域差异
- 功能维度:
- 即时通讯完全不可用
- 历史记录可查看但无法回复
- 订单操作等其它功能正常
影响程度评估表:
| 影响对象 | 具体表现 | 业务损失估算 |
|---|---|---|
| 消费者 | 咨询/售后中断 | 客诉量激增300% |
| 商家 | 无法响应询盘 | 转化率下降40-60% |
| 平台 | 客服系统瘫痪 | 当日GMV预计损失5-8% |
2.2 根因推测与技术验证
结合分布式系统运维经验,最可能的故障原因包括:
可能性1:消息队列服务崩溃
- 典型症状:区域性影响+分批恢复
- 验证方法:检查RabbitMQ/Kafka监控指标
- 修复预案:消息重放+消费者重启
可能性2:微服务链路断裂
- 典型症状:功能模块完全不可用
- 验证方法:追踪API网关日志
- 修复预案:服务降级+限流启动
可能性3:数据库主从切换失败
- 典型症状:部分用户正常
- 验证方法:检查MySQL集群状态
- 修复预案:强制主节点选举
实操建议:企业级系统应建立"熔断-降级-限流"三级防护体系,关键服务做到:
- 异地多活部署
- 分钟级监控告警
- 自动化故障转移
3. 应急响应与故障处理实录
3.1 用户端临时解决方案
在官方修复前,我们测试出以下应急通道:
- 电话客服迂回:
- 拨打400-8822-888转人工
- 说明"在线客服不可用"可获优先接入
- 邮件工单系统:
- 发送需求至kefu@pinduoduo.com
- 主题注明【紧急】+订单号
- 微信服务号:
- 关注"拼多多服务号"
- 通过菜单"人工客服"接入
3.2 技术团队诊断流程
根据行业标准,完整的故障处理应包含以下步骤:
bash复制# 1. 服务健康检查
kubectl get pods -n chat-service | grep -v Running
# 2. 网络连通性测试
traceroute chat-gateway.pdd.com
# 3. 数据库状态验证
mysql -h db-master -u monitor -p'$password' -e "SHOW SLAVE STATUS\G"
# 4. 消息堆积检测
rabbitmqctl list_queues name messages_ready
典型问题处理记录表:
| 异常现象 | 排查工具 | 解决方案 | 耗时 |
|---|---|---|---|
| API超时 | Grafana监控 | 扩容Pod实例 | 23min |
| 数据库IOPS飙升 | Cloud Insight | 增加缓存节点 | 41min |
| 消息积压10W+ | Kafka Manager | 启动备用消费者组 | 17min |
4. 架构优化建议与灾备方案
4.1 高可用改造方案
基于本次故障教训,建议从三个层面改进:
基础设施层
- 部署多AZ架构,避免单区域故障
- 实施CDN加速,提升边缘节点响应
应用服务层
- 引入服务网格istio实现智能路由
- 配置Hystrix熔断规则:
java复制@HystrixCommand( fallbackMethod = "defaultResponse", commandProperties = { @HystrixProperty(name="circuitBreaker.errorThresholdPercentage", value="50"), @HystrixProperty(name="metrics.rollingStats.timeInMilliseconds", value="30000") } )
数据持久层
- 采用TiDB替代传统MySQL集群
- 实现异地双活数据同步
4.2 灾备演练checklist
建议企业每月执行以下验证:
- [ ] 模拟区域网络中断
- [ ] 强制主数据库宕机
- [ ] 注入消息队列延迟
- [ ] 压测API网关极限
- [ ] 验证监控告警时效性
5. 用户应对策略与沟通技巧
5.1 消费者应急指南
遇到类似情况时:
- 立即截图保存故障界面
- 尝试切换网络环境(4G/WiFi)
- 记录事发时间点(精确到分钟)
- 通过多渠道并行反馈:
- 微博@拼多多客服
- 消费者协会12315平台
- 黑猫投诉等第三方渠道
5.2 商家损失 mitigation
经实测有效的补救措施:
- 在商品页置顶公告说明
- 启用备用联系方式(企业微信等)
- 承诺补偿方案(如赠券)
- 事后批量导出咨询用户做定向营销
这次故障给我的深刻启示是:任何看似简单的功能背后,都需要复杂的系统工程支撑。作为技术人员,我们既要保证系统的高可用,也要为用户准备好完善的应急通道。
内容推荐
区块链技术如何解决数字游民工作证明难题
区块链技术通过分布式账本、共识机制和智能合约等核心技术,为远程工作提供了全新的信任解决方案。分布式账本技术将工作过程数据不可篡改地记录下来,共识机制通过算法验证工作真实性,智能合约则实现自动化价值交换。这些技术特别适合数字游民和远程工作者解决在场证明问题,既能保障工作真实性,又不会侵犯个人隐私。在实际应用中,结合地理位置哈希、时间戳和工作内容指纹等技术,可以构建可信的工作证明系统。随着Web3.0和DAO组织的发展,区块链工作证明正在成为数字游民建立职业信用体系的重要工具。
电车续航真相:700公里为何跑长途仍不够用
电动汽车续航能力是用户关注的核心指标,但实际使用中常出现标称续航与真实里程不符的情况。这主要源于锂电池的工作原理特性:为保护电池寿命,建议将电量维持在20%-80%区间使用,这使得实际可用续航大幅缩减。同时,高速行驶时空气阻力呈平方增长,电机效率下降,导致电耗显著增加。温度变化也会影响电池性能,低温环境下容量可能下降30%,充电速度减半。从工程实践看,单纯增加电池容量会带来重量增加、成本上升等连锁问题。当前提升长途体验的关键在于优化充电策略,采用少量多次的方式,并配合科学的驾驶技巧。随着800V高压平台等新技术的普及,电动车长途出行体验正在逐步改善。
ASP.NET MVC超大文件上传优化方案与工业实践
在Web开发中,文件上传是常见需求,但当面对超大文件(如20GB以上)时,传统方法会导致服务器内存耗尽。NIO内存映射和分片技术通过零拷贝机制,将内存占用从文件大小×并发数优化为分片大小×并发数,实现高效传输。结合SM4国密加密保障数据安全,动态分片策略适应网络波动,断点续传确保传输可靠性。这些技术在芯片制造等行业尤为重要,满足光刻数据等关键业务的高完整性、24小时稳定传输需求。ASP.NET MVC框架下的工业级实现,为超大文件上传提供了稳定高效的解决方案。
多能源微网双层调度模型与MATLAB实现
能源微网系统通过整合电力、热力等多种能源形式,实现能源梯级利用和互补优化。其核心在于优化调度算法,通过建立双层模型(微网层与运营商层)实现成本最小化目标。关键技术包括多时间尺度滚动优化、互补松弛条件处理和预测误差补偿等。在MATLAB实现中,fmincon求解器和并行计算技术能有效提升计算效率。这种调度模型在工业园区等场景中,可降低12-18%运行成本,提高20-25%可再生能源消纳率。热词显示,LSTM预测模型与优化框架的结合能进一步提升系统性能。
字符串反转与KMP算法:双指针与模式匹配实战
字符串处理是算法与数据结构中的核心基础,其中双指针技术因其O(1)空间复杂度特性,成为解决字符串反转等问题的经典方法。通过首尾指针同步移动实现原地交换,这种技术广泛应用于内存敏感场景。KMP算法则通过构建next数组预处理模式串,将字符串匹配的时间复杂度优化至O(m+n),特别适合处理大规模文本搜索。这两种技术在编译器设计、数据库索引等底层系统中都有重要应用,其中双指针法常被用于实现内存操作函数,而KMP算法则是正则表达式引擎的基础组件。本文通过反转字符串和实现strStr()两个典型案例,展示了如何将基础算法思想转化为工程实践。
SSM框架构建青少年心理健康平台的实践与优化
WebSocket实时通讯技术作为现代Web应用的核心组件,通过建立全双工通信通道实现服务端与客户端的低延迟数据交互。其基于TCP协议的特性保证了传输可靠性,配合STOMP等子协议可轻松实现消息订阅分发模式。在Spring生态中,通过@EnableWebSocketMessageBroker注解即可快速集成WebSocket功能,大幅降低开发复杂度。这种技术方案特别适合在线咨询、即时通讯等对实时性要求高的场景,如青少年心理健康平台中的咨询模块。结合Redis实现消息持久化与离线推送,既能保障消息可靠性,又能利用内存数据库的高性能特性。项目中采用策略模式开发的可配置化测评引擎,通过动态加载不同量表的计算策略,完美支持了SDS抑郁自评、SAS焦虑自评等多种心理量表的灵活扩展。
内存取证实战:从WorldSkills赛题解析到企业安全应用
内存取证作为数字取证的核心技术,通过分析系统运行时内存状态,能够捕获加密文件明文、隐藏进程等关键证据。其技术原理基于操作系统内存管理机制,结合Volatility等工具解析内存数据结构。在安全运维和司法取证领域,该技术可有效应对勒索软件、内部威胁等场景。以WorldSkills比赛镜像为例,通过进程树分析、网络痕迹提取等实战方法,展示了如何发现Cobalt Strike等高级威胁。内存取证不仅能还原攻击链,还能通过注册表分析、时间线构建等技术形成完整证据链,为企业安全团队提供实战参考。
基于Django与微信小程序的旧衣回收系统开发实践
Web开发框架Django以其高效的ORM系统和模块化设计,成为构建企业级应用的优选方案。结合微信小程序生态,开发者能快速实现移动端业务闭环。本文通过旧衣回收系统案例,详解如何运用Django REST framework构建高并发API服务,集成Celery异步任务处理估价算法,并采用Redis多级缓存优化系统性能。特别针对环保科技领域,分享了微信支付安全校验、订单状态机设计等实战经验,为O2O类应用开发提供可复用的技术方案。
化工反应安全工程:原理、风险评估与事故预防
化工反应安全工程是确保生产过程安全的核心技术领域,涉及反应机理、设备设计和操作规范等多维度系统把控。通过反应量热技术和绝热温升计算等科学方法,可以准确评估反应热风险,预防失控反应发生。本质安全设计原则包括最小化、替代、缓和和简化四个层次,从源头上降低事故概率。在工程实践中,安全泄放系统设计和工艺安全管理(SIS系统)是最后防线,微反应器、在线监测等前沿技术正推动反应安全进入智能化时代。本文通过AZF化工厂等典型案例,深入解析如何避免硝酸铵等危险化学品因相容性问题导致的热失控爆炸事故。
GEO时代:AI推荐优化与品牌营销新策略
生成式引擎优化(GEO)是AI时代品牌营销的新范式,它通过优化品牌在AI生成内容中的存在感和推荐权重,解决传统SEO无法覆盖的AI推荐场景。GEO的核心原理在于构建结构化知识图谱和高质量语料体系,使AI系统能够准确识别并推荐品牌产品。其技术价值体现在算法背书的权威认证效应、高转化意图流量的精准捕获以及长尾需求的系统性覆盖。在应用场景上,GEO特别适合智能家居、护肤护发、母婴用品等需要专业推荐的垂直领域。通过语料战略构建、知识图谱关联和持续优化反馈,品牌可以在AI推荐系统中建立竞争优势,实现从流量获取到信任转化的营销升级。
SpringCloud微服务架构在在线教育平台中的实践与优化
微服务架构作为现代分布式系统设计的核心范式,通过将单体应用拆分为松耦合的服务集合,显著提升了系统的可扩展性和可维护性。其核心原理包括服务自治、独立部署和去中心化治理,技术实现上通常依赖SpringCloud等框架。在在线教育等高并发场景中,微服务架构能够有效应对流量峰值,结合Nacos服务发现、Sentinel流量控制等组件,可构建出高可用的学习平台系统。本文以公务员考试平台为例,详细解析了基于SpringBoot+Vue+SpringCloud的技术栈选型、微服务拆分策略,以及Elasticsearch智能检索、Redis多级缓存等关键优化手段,为教育类SaaS系统开发提供了可复用的工程实践方案。
CMIP6数据高效下载:迅雷批量获取与ESGF筛选技巧
气候模型数据获取是科研工作的基础环节,CMIP6作为国际主流气候数据集,其数据下载常面临跨平台操作复杂、网络不稳定等挑战。本文从数据爬取技术原理出发,介绍如何通过ESGF官方门户的智能筛选系统精准定位所需变量(如地表气温tas),并创新性采用迅雷多线程下载技术实现高速批量获取。该方法特别适用于Windows环境下的科研人员,有效解决了传统wget脚本对Linux环境的依赖问题,同时通过文件校验和目录标准化管理确保数据质量。结合气候模型分析场景,文中详细演示了从数据筛选、URL提取到下载配置的全流程工程实践。
全文检索技术原理与Elasticsearch实践指南
全文检索是处理非结构化文本数据的核心技术,通过倒排索引实现高效查询。其核心流程包括文档解析、分词处理、索引构建和相关性排序,支持模糊匹配、语义分析等高级功能。在分布式系统中,Elasticsearch凭借其高扩展性和丰富查询语法成为主流选择,特别适合日志分析和大规模数据搜索场景。实际应用中,合理设计索引映射(如区分text/keyword类型)和配置中文分词器(如IK Analyzer)对提升搜索质量至关重要。本文结合Elasticsearch部署实例,详解从环境准备、数据导入到查询优化的全流程实践方案。
特征模态分解(VMD)在信号处理中的原理与MATLAB实现
特征模态分解(VMD)是一种基于变分框架的自适应信号处理方法,通过约束各模态的带宽和中心频率,有效解决传统方法中的模态混叠问题。其核心原理是将复杂信号分解为若干具有稀疏性的本征模态函数(IMF),每个IMF围绕特定中心频率振荡。这种方法在工业故障诊断、生物医学信号处理等领域展现出独特技术价值,尤其擅长从强噪声中提取冲击特征。在MATLAB环境中,通过合理配置alpha、K等关键参数,结合交替方向乘子法(ADMM)优化算法,可以实现轴承振动信号分析、语音分离等工程应用。针对端点效应等常见问题,采用自适应延拓方案能显著提升分解精度。
Spring Bean XML配置解析机制详解
Spring框架的IoC容器通过XML配置实现依赖注入,其中BeanDefinition是核心元数据模型。解析过程涉及XML到DOM树的转换、属性提取和BeanDefinition创建,采用线程安全设计确保多线程环境下的稳定性。通过BeanDefinitionParserDelegate实现可扩展的解析逻辑,支持自定义命名空间。在工程实践中,合理使用懒加载和显式ID定义能提升性能与可维护性。Spring的XML配置机制为大型应用提供了集中式管理方案,与注解配置形成互补。掌握Bean解析原理有助于解决类加载、属性注入等常见问题,是深入理解Spring运行机制的关键。
MySQL亿级数据分页优化实战与性能对比
数据库分页查询是Web应用中的基础技术,其核心原理是通过LIMIT和OFFSET实现数据分段获取。在数据量激增的互联网场景下,传统分页方式面临严重性能瓶颈,特别是在处理深分页(如百万级偏移量)时,由于需要先读取再丢弃大量记录,导致查询效率指数级下降。通过游标分页(Cursor-based Pagination)和延迟关联等优化技术,可以绕过OFFSET机制直接定位数据位置,结合联合索引和确定性排序等工程实践,实现从12秒到15毫秒的800倍性能提升。这些方案在用户行为分析、电商订单管理等高频查询场景中具有显著价值,尤其适合处理MySQL、PostgreSQL等关系型数据库中的亿级数据分页挑战。
多微网能量互联优化调度与低碳经济运行实践
微电网作为分布式能源系统的核心单元,其优化调度技术正成为能源转型的关键支撑。通过智能算法实现多微网间的能量互联,能够突破传统电力系统可再生能源消纳瓶颈,显著提升能源利用效率。在工程实践中,基于Matlab的优化算法开发与系统建模技术,可有效解决多目标约束下的调度优化问题。典型应用场景如工业园区微网群,通过光伏、风电等清洁能源与储能系统的协同调度,实现运行成本降低与碳排放减少的双重目标。其中粒子群算法(PSO)的改进应用和LSTM负荷预测技术,为系统稳定运行提供了重要保障。
神经科技伦理困境与测试边界挑战
神经科学技术如脑机接口和神经调控正在突破人类认知边界,同时也带来深刻的伦理问题。这些技术通过改变神经元活动模式提升认知能力,但可能干预自然认知过程。测试边界面临生理安全阈值动态性、心理影响滞后效应和社会影响不可预测性三重挑战。动态风险评估矩阵和神经权利清单等创新工具为伦理评估提供新思路。全周期测试框架和群体模拟测试平台等技术方法有助于更全面地评估神经科技的影响。神经科技的伦理边界需要动态调整,建立神经技术影响追溯系统是实现平衡发展的关键。
GitHub Actions CI/CD配置优化全指南
持续集成(CI)是现代软件开发的核心实践,通过自动化构建、测试和部署流程显著提升交付效率。GitHub Actions作为主流CI/CD工具,其YAML配置文件设计直接影响流水线性能。从基础的事件触发机制到高级的矩阵测试配置,合理的架构设计能实现多环境并行验证。关键技术点包括依赖缓存优化、条件执行控制以及安全密钥管理,这些都能通过简单的YAML语法实现。在工程实践中,结合npm等包管理器的缓存策略和CodeQL等安全扫描工具,可以构建出既高效又安全的自动化流程。本文深入解析ci.yml配置技巧,帮助开发者掌握从基础到进阶的GitHub Actions优化方法。
背包问题:动态规划与优化策略详解
背包问题是计算机科学中经典的组合优化问题,广泛应用于资源分配、投资组合等实际场景。其核心思想是在有限容量的约束下,选择物品组合以实现价值最大化。动态规划是解决背包问题的关键技术,通过构建状态转移方程实现最优解的计算。工程实践中,空间优化和剪枝策略能显著提升算法效率。在云计算资源调度、金融投资分析等场景中,背包问题的变体如0-1背包、完全背包等都有重要应用。掌握背包问题的解法不仅有助于理解算法设计思想,也能为实际工程问题提供优化方案。
已经到底了哦
精选内容
1 职场情绪管理的核心误区与即时处理技巧2 OpenClaw开源AI助手框架安装与配置指南3 C++引用:安全高效的变量别名实践指南4 Vue 3 + ECharts 实现高性能大数据折线图5 工程师的日语N2备考:系统化学习与工程思维应用6 力扣Hot100高效刷题:算法模板与速写技巧7 FDTD方法在双缝干涉模拟中的实现与优化8 Laravel开发旅游信息平台:架构设计与实战经验9 架构设计工具链:从UML到Swagger的实践指南10 2026护网行动高频面试题解析与攻防趋势
热门内容
1 CSRF攻击防御方案与实战指南2 机械行业网页编辑器PDF转存技术方案解析3 WCF单向模式原理、应用与性能优化指南4 OpenClaw框架与住宅代理突破亚马逊反爬技术解析5 OSGEarth三维仿真系统开发核心技术解析6 论文排版工具Paperxie:智能解决学术格式难题7 Android校园教学管理系统开发实践与优化8 Python股票数据可视化:从K线图到量化分析实战9 社会工作师与心理咨询师的核心差异与协同实践10 C++编程基础:绝对值计算与条件判断实践
最新内容
Ubuntu 24.04 APT密钥管理升级与解决方案
APT(Advanced Package Tool)是Linux系统中广泛使用的包管理工具,其核心原理是通过GPG密钥验证软件包的真实性。随着安全需求的提升,Ubuntu从20.04版本开始逐步废弃传统的集中式密钥管理方式,转而采用更安全的`signed-by`声明方案。这种改进能精确控制每个软件源的密钥权限,避免第三方源密钥污染问题。在Ubuntu 24.04 LTS中,系统会提示`legacy trusted.gpg keyring`的废弃警告,若不及时处理可能导致软件源验证失败。通过将密钥迁移到`/usr/share/keyrings/`目录并修改`sources.list`配置,可解决Docker CE等第三方源的兼容性问题,确保系统更新通道的稳定性。
C++ string类核心操作与面试题精解
字符串处理是编程基础中的核心技能,C++标准库中的string类提供了强大的字符串操作能力。从内存管理原理来看,string类通过自动分配和释放内存简化了开发,而其丰富的接口支持查找、替换、比较等常见操作。在工程实践中,合理使用string类能显著提升代码效率和安全性,特别是在处理文本解析、数据转换等场景时。高频面试题如字符串反转、atoi实现等,都考察对string类操作的熟练程度。通过掌握KMP算法、正则匹配等高级应用,可以解决字符串匹配等复杂问题。预分配内存、避免不必要拷贝等优化技巧,则能进一步提升性能。
基于SpringBoot+Vue的智能新闻推荐系统设计与实现
推荐系统作为信息过滤的核心技术,通过分析用户历史行为和内容特征实现个性化分发。其核心技术包括协同过滤算法、内容特征提取和实时用户行为分析。在Java技术栈中,SpringBoot+Vue的前后端分离架构因其开发效率和性能优势成为主流选择。本文以新闻推荐场景为例,详细解析了混合推荐策略的实现,包括基于用户的协同过滤算法代码示例、MySQL索引优化方案以及Redis缓存的应用。针对推荐系统常见的冷启动问题,提出了兴趣标签选择与热门内容补全的解决方案。该系统架构对电商、视频等需要个性化推荐的平台具有参考价值,其中SpringBoot的自动配置特性和Vue的响应式绑定显著提升了开发效率。
Django+Spark构建服装趋势分析系统实战
大数据分析技术在服装行业的应用正成为提升商业决策效率的关键。通过Spark实现海量数据的实时处理,结合Django框架快速构建可视化界面,可有效解决传统服装行业数据分析维度单一、响应慢的痛点。系统采用LSTM+Attention模型进行趋势预测,引入社交媒体情绪因子提升准确率,同时通过消费者7维画像实现精准营销。典型应用场景包括爆款预测、库存优化及用户行为分析,某女装品牌应用后爆款预测准确率提升37%。技术方案特别强调Spark内存计算与Django ORM的协同优化,在千万级数据量下开发效率比Java方案高3倍。
SpringBoot智慧医疗门诊预约系统设计与实现
医疗信息化建设中,门诊预约系统通过技术手段解决传统挂号难题。基于分布式系统原理,采用Redis缓存与Lua脚本保证高并发场景下的数据一致性,结合SpringBoot框架实现快速开发。系统设计中,号源分配算法与数据库索引优化是关键,其中Redis的SortedSet结构天然适合排队场景,而MyBatis-Plus则简化了CRUD操作。这类系统在智慧医院建设中具有广泛应用,能有效提升医疗资源利用率,改善患者就诊体验。通过分时段放号、弹性时间划分等技术方案,实现了号源管理的公平性与系统稳定性。
PyAutoGUI桌面自动化实战:从入门到精通
桌面自动化技术通过程序控制鼠标键盘操作,实现重复任务的自动化执行,其核心原理是模拟人工操作并基于图像识别定位界面元素。PyAutoGUI作为Python生态中的轻量级工具,无需依赖特定API即可操作任意GUI应用,特别适合处理跨平台自动化需求。在RPA流程开发、批量文件处理、UI自动化测试等场景中,通过结合图像识别与坐标定位技术,能有效解决动态界面元素定位、操作时序控制等工程难题。本文以实际项目为例,详解如何运用热词PyAutoGUI进行高效开发,并分享企业级自动化架构设计中涉及的性能优化、错误处理等关键技术要点。
SpringBoot+Vue班级管理系统开发实战指南
现代Web开发中,前后端分离架构已成为主流技术范式。通过SpringBoot快速构建RESTful API后端服务,结合Vue.js实现响应式前端界面,这种技术组合显著提升了开发效率。SpringBoot的自动化配置特性减少了传统Spring项目的XML配置负担,而Vue的组件化开发模式则优化了前端代码的可维护性。在班级管理系统这类实际应用中,这种架构能有效解决信息不透明、管理效率低下等问题。系统采用JWT进行安全认证,结合RBAC权限模型实现细粒度的访问控制,同时利用MyBatis-Plus简化数据库操作,ECharts实现数据可视化,为教育信息化提供了完整的解决方案。
弱视康复训练软件系统:原理、应用与效果分析
视觉训练技术基于神经可塑性原理,通过特定频率的光栅刺激和对比度调节激活视皮层神经元,广泛应用于弱视康复领域。现代计算机视觉技术结合临床验证算法,开发出覆盖移动端和PC端的专业训练系统,包含动态光栅刺激、精细视觉灵敏度训练等核心模块。这类系统通过红蓝分视技术实现双眼协同训练,并支持个性化训练计划智能推荐。在临床实践中,坚持使用4周可使弱视眼最小分辨角平均提升27%,8周训练后78%屈光参差性弱视患者视力提升2行以上。该系统将专业临床训练家庭化,但需在医生指导下配合Worth四点检查等专业诊断使用。
PDF24:免费全能PDF工具箱的功能与应用
PDF处理工具在现代办公中扮演着重要角色,从文档转换到编辑优化,其核心技术涉及格式解析、OCR识别和压缩算法。PDF24作为一款免费且功能全面的PDF工具箱,集成了二十多种实用功能,包括格式转换、文档编辑和智能压缩等。其本地处理的特性保障了数据安全,特别适合企业级应用。通过实际测试,PDF24在中文文档处理和批量操作方面表现优异,OCR识别准确率高达95%。对于需要高效PDF解决方案的用户,这款工具能显著提升工作效率,尤其适合文字工作者和团队协作场景。
Netty任务执行机制与高性能网络编程实践
事件循环(EventLoop)是高性能网络编程框架的核心机制,通过单线程串行化处理IO事件和异步任务,实现无锁并发和确定性执行。其技术价值在于减少线程切换开销,提升IO密集型场景吞吐量,典型应用在RPC框架、消息中间件等分布式系统。Netty作为Java生态主流网络框架,其SingleThreadEventExecutor通过线程精确绑定、任务队列优化、懒加载等设计,在实战中可实现30%以上的性能提升。本文以execute()方法为切入点,深入解析任务调度、队列处理、线程启动等关键流程,并给出ioRatio参数调优、队列容量计算等工程实践建议。