
1. SharePoint Online文档库还原功能概述
在日常办公中,文档管理是每个团队都面临的挑战。作为微软365生态系统的核心组件,SharePoint Online提供了强大的文档库功能,而其中的还原功能更是团队协作中的"安全网"。这个功能允许管理员和具有权限的用户将整个文档库或特定文件恢复到历史版本状态,有效应对误删除、错误修改或恶意篡改等情况。
我曾在多个企业级项目中亲身体验过这个功能的价值。有一次客户团队误删除了整个季度的重要报表,正是通过文档库还原功能,我们在5分钟内就找回了所有文件,避免了数据灾难。与传统的备份还原相比,SharePoint的版本还原更加精细和即时,不需要IT部门介入,业务用户自己就能完成大部分恢复操作。
2. 还原功能的核心原理与限制
2.1 版本控制机制
SharePoint文档库的还原功能建立在版本控制系统之上。默认情况下,SharePoint会为每个上传或修改的文件创建版本快照。版本控制有两种模式:
- 主版本号(如1.0,2.0): 通常用于标记重要的里程碑修改
- 次版本号(如1.1,1.2): 记录较小的编辑和调整
重要提示:版本控制功能需要手动启用,默认情况下可能只保留主版本。建议在库设置中配置为保留所有版本(主版本和次版本),并设置合理的保留期限。
2.2 还原功能的技术限制
虽然还原功能强大,但也有其限制条件:
- 时间范围限制:标准版SharePoint Online通常保留93天的版本历史,企业版可能更长
- 存储配额限制:每个版本都会占用存储空间,大量版本可能耗尽站点配额
- 权限要求:执行还原操作需要"完全控制"或"设计"权限级别
- 批量操作限制:一次性还原大量文件可能导致超时,建议分批操作
3. 完整还原操作指南
3.1 准备工作与环境检查
在执行还原前,建议先确认以下事项:
- 检查用户权限:确保账户具有库级别的"设计"或更高权限
- 查看版本设置:导航至"库设置" > "版本控制设置",确认版本历史已启用
- 评估存储情况:在SharePoint管理员中心检查站点存储使用情况
3.2 分步还原操作流程
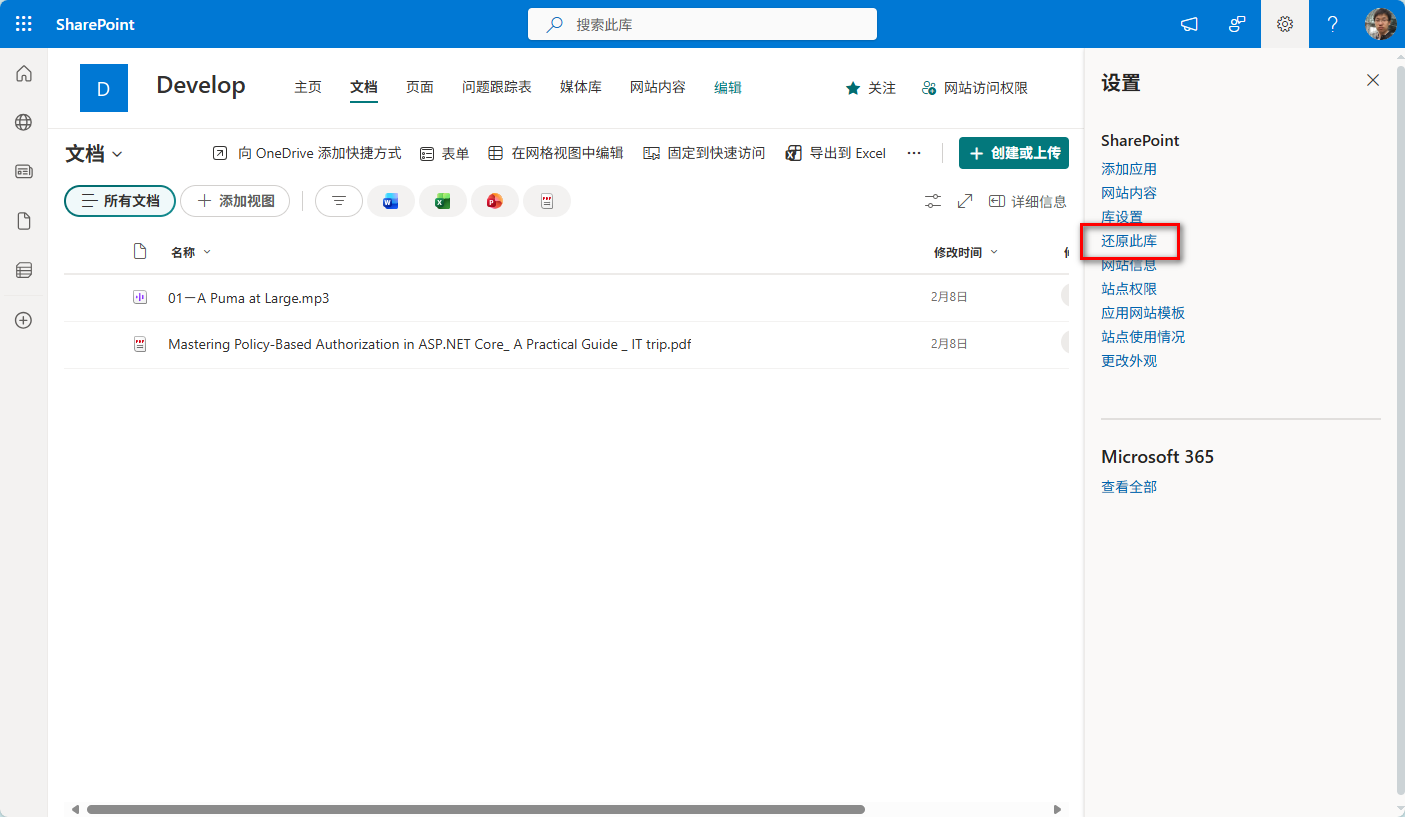
步骤1:访问文档库设置
- 打开目标文档库
- 点击右上角的齿轮图标(设置按钮)
- 从下拉菜单中选择"还原此文档库"
步骤2:选择还原时间点
- 在弹出的时间线界面上,拖动滑块或点击日历图标
- 选择要还原到的具体日期和时间
- 系统会显示该时间点的库内容快照
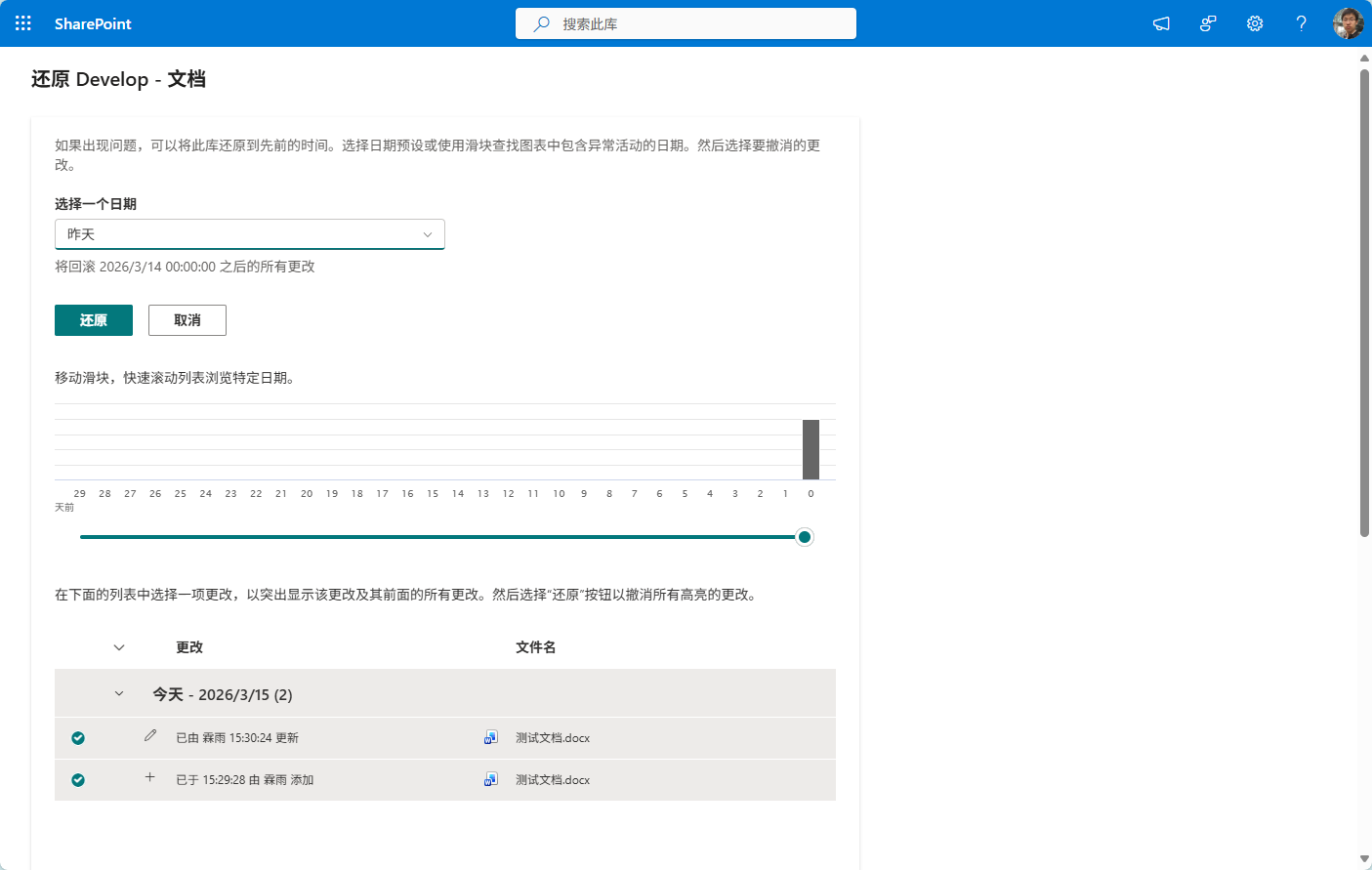
步骤3:确认并执行还原
- 预览将要还原的文件列表
- 选择需要还原的特定文件或勾选"全选"
- 点击"还原"按钮并确认操作
- 等待系统处理完成(大文件库可能需要几分钟)
3.3 还原后的验证步骤
- 检查还原文件的数量是否与预期一致
- 随机抽样打开几个文件,确认内容正确
- 查看文件的版本历史,确认新版本已创建
- 如有必要,通知团队成员文件已恢复
4. 高级应用场景与技巧
4.1 批量还原策略
当需要恢复大量文件时,直接全选可能导致操作超时。我的经验是:
- 按文件夹分批还原,每次处理一个子文件夹
- 先还原最重要的文件,再处理次要文件
- 对于超大型库,考虑使用PowerShell脚本自动化
4.2 与回收站配合使用
SharePoint有两级回收站系统:
- 第一级回收站:用户可直接恢复最近删除的文件
- 第二级回收站:站点管理员可恢复从第一级回收站清空的文件
还原功能与回收站形成互补:
- 回收站适用于简单删除恢复
- 版本还原适用于内容修改回滚
4.3 企业级部署建议
对于关键业务文档库,建议配置以下增强措施:
- 延长版本保留期:通过合规策略延长至最长10年
- 启用审计日志:跟踪所有还原操作
- 设置警报规则:当重要文件被还原时通知管理员
- 定期导出备份:作为版本还原的补充保障
5. 常见问题与疑难解答
5.1 还原选项不可用
可能原因及解决方案:
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| "还原此库"选项灰色 | 权限不足 | 联系管理员获取"设计"或更高权限 |
| 看不到历史版本 | 版本控制未启用 | 在库设置中启用版本控制 |
| 时间点选择有限 | 保留期限设置过短 | 调整版本历史保留期限 |
5.2 还原后文件异常
我曾遇到过的几种情况:
- 文件内容不完整:可能是还原过程中断,尝试重新还原或选择稍早时间点
- 权限配置丢失:还原不会恢复独特的权限设置,需要手动重新配置
- 元数据不一致:检查栏位映射是否正确,必要时手动调整
5.3 性能优化建议
当文档库很大时,还原操作可能很慢。可以:
- 在非高峰时段执行还原
- 临时增加站点资源配额
- 考虑将大文件库拆分为多个小库
- 使用CSOM或REST API实现后台异步还原
6. 最佳实践与经验分享
经过多个项目的实践,我总结了以下经验:
- 定期测试还原功能:至少每季度验证一次关键库的还原能力
- 文档版本命名规范:在文件名或属性中加入版本标识,便于识别
- 用户培训重点:教会核心用户使用回收站和基本还原功能,减轻IT负担
- 监控存储增长:设置警报当版本存储超过配额50%时通知
一个特别有用的技巧是:在执行重大修改前,可以手动创建一个"还原点"。方法是上传一个空文件并命名为"还原点_YYYYMMDD",这样在时间线上就有一个明确的标记点,便于后续定位。
对于需要长期保留的重要文档,建议同时启用SharePoint的保留策略和OneDrive的PC本地备份,形成多层保护。这样即使遇到极端情况,也能从多个渠道恢复数据。