Django+Vue.js构建高校选课系统实战

1. 项目概述
这个基于Django的学生选课系统是我最近完成的一个毕业设计项目,也是我在高校教学管理系统领域的一次实践探索。作为一名有多年开发经验的程序员,我深知一个优秀的选课系统对于高校教务管理的重要性。传统的选课方式往往存在系统崩溃、选课不公平、数据统计困难等问题,而这个项目正是为了解决这些痛点而设计的。
系统采用了Django作为后端框架,配合MySQL数据库和Vue.js前端技术,实现了完整的选课流程管理、课程管理、学生管理等功能模块。整个系统从需求分析、架构设计到编码实现,再到最后的测试部署,都是我亲自操刀完成的。在这个过程中,我积累了不少实战经验,也踩过一些坑,今天就把这个项目的完整实现过程分享给大家。
2. 系统架构设计
2.1 技术选型分析
在项目启动阶段,我花了大量时间进行技术选型的调研和比较。最终确定的技术栈如下:
后端框架:Django
- 选择理由:Django作为Python最成熟的Web框架之一,提供了完整的MVC架构、ORM支持、Admin后台等开箱即用的功能,特别适合快速开发管理系统类项目。
- 版本:Django 3.2 LTS(长期支持版)
- 关键特性:自带用户认证系统、强大的Admin后台、完善的文档和社区支持
数据库:MySQL 8.0
- 选择理由:作为最流行的开源关系型数据库,MySQL在性能、稳定性和社区支持方面都有保障
- 版本:MySQL 8.0
- 优化措施:建立了适当的索引、使用了连接池、进行了查询优化
前端技术:Vue.js + Element UI
- 选择理由:Vue.js的渐进式特性和组件化开发模式非常适合管理系统类项目
- 版本:Vue 2.6 + Element UI 2.15
- 特性:响应式设计、组件复用、状态管理(Vuex)
2.2 系统架构设计
系统采用了经典的三层架构设计:
- 表现层:基于Vue.js的前端界面,负责用户交互和数据展示
- 业务逻辑层:Django后端服务,处理业务逻辑和数据处理
- 数据访问层:Django ORM + MySQL,负责数据持久化
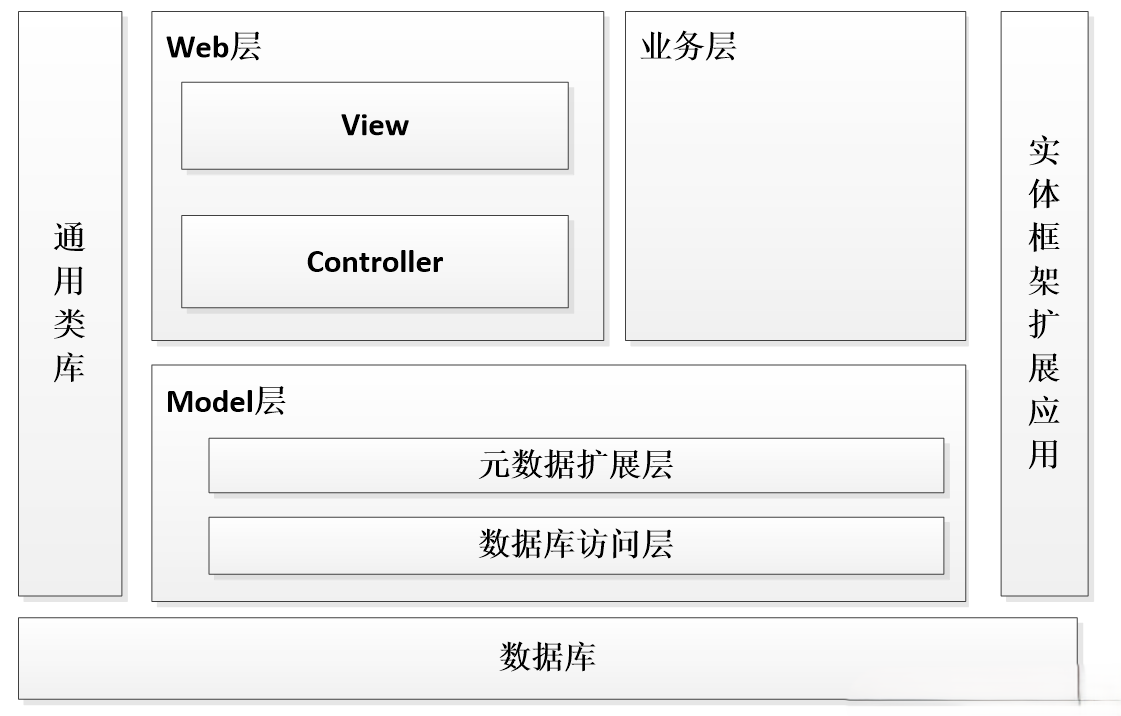
这种分层架构的优势在于:
- 各层职责明确,便于维护和扩展
- 前后端分离,可以独立开发和部署
- 通过API接口通信,提高了系统的灵活性
3. 数据库设计
3.1 核心数据模型
系统的主要数据模型包括:
- 用户模型(User):存储系统所有用户信息
- 学生模型(Student):继承自User,存储学生特有信息
- 教师模型(Teacher):继承自User,存储教师特有信息
- 课程模型(Course):存储课程基本信息
- 选课记录模型(Selection):记录学生选课情况
- 教学班模型(Class):课程的具体教学班信息
3.2 数据库表结构
以下是几个核心表的设计:
用户表(users_user)
sql复制CREATE TABLE `users_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`password` varchar(128) NOT NULL,
`last_login` datetime(6) DEFAULT NULL,
`is_superuser` tinyint(1) NOT NULL,
`username` varchar(150) NOT NULL,
`first_name` varchar(150) NOT NULL,
`last_name` varchar(150) NOT NULL,
`email` varchar(254) NOT NULL,
`is_staff` tinyint(1) NOT NULL,
`is_active` tinyint(1) NOT NULL,
`date_joined` datetime(6) NOT NULL,
`user_type` varchar(20) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
课程表(courses_course)
sql复制CREATE TABLE `courses_course` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` varchar(20) NOT NULL,
`name` varchar(100) NOT NULL,
`credit` int(11) NOT NULL,
`description` longtext,
`department` varchar(50) NOT NULL,
`created_at` datetime(6) NOT NULL,
`updated_at` datetime(6) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `code` (`code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
选课记录表(selections_selection)
sql复制CREATE TABLE `selections_selection` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`status` varchar(20) NOT NULL,
`created_at` datetime(6) NOT NULL,
`updated_at` datetime(6) NOT NULL,
`class_id` int(11) NOT NULL,
`student_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `selections_selection_class_id_3a1a7b0a_fk_classes_class_id` (`class_id`),
KEY `selections_selection_student_id_5c8c3a0a_fk_users_user_id` (`student_id`),
CONSTRAINT `selections_selection_class_id_3a1a7b0a_fk_classes_class_id` FOREIGN KEY (`class_id`) REFERENCES `classes_class` (`id`),
CONSTRAINT `selections_selection_student_id_5c8c3a0a_fk_users_user_id` FOREIGN KEY (`student_id`) REFERENCES `users_user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.3 数据库优化措施
为了提高系统性能,我采取了以下优化措施:
- 合理设计索引:在经常查询的字段上建立索引,如用户表的username、课程表的code等
- 使用连接池:通过django-db-geventpool实现数据库连接池,减少连接创建开销
- 查询优化:使用Django的select_related和prefetch_related减少查询次数
- 缓存策略:对热点数据如课程列表使用Redis缓存
4. 核心功能实现
4.1 用户认证模块
用户认证是系统的基础功能,我基于Django自带的认证系统进行了扩展:
python复制# users/models.py
from django.contrib.auth.models import AbstractUser
from django.db import models
class User(AbstractUser):
USER_TYPE_CHOICES = (
('student', 'Student'),
('teacher', 'Teacher'),
('admin', 'Administrator'),
)
user_type = models.CharField(max_length=20, choices=USER_TYPE_CHOICES)
class Meta:
db_table = 'users_user'
class Student(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE, primary_key=True)
student_id = models.CharField(max_length=20, unique=True)
department = models.CharField(max_length=50)
grade = models.CharField(max_length=10)
class Meta:
db_table = 'users_student'
认证流程:
- 用户通过用户名密码登录
- 系统验证凭证并返回JWT token
- 前端在后续请求中携带token进行认证
4.2 选课功能实现
选课是系统的核心功能,需要考虑并发控制和业务规则:
python复制# selections/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from django.db import transaction
from django.utils import timezone
from .models import Selection
from classes.models import Class
from users.models import Student
class SelectionCreateAPIView(APIView):
def post(self, request):
student = request.user.student
class_id = request.data.get('class_id')
try:
class_obj = Class.objects.select_for_update().get(id=class_id)
except Class.DoesNotExist:
return Response({'error': 'Class not found'}, status=status.HTTP_404_NOT_FOUND)
# 检查选课时间是否在开放期间
if not (class_obj.selection_start <= timezone.now() <= class_obj.selection_end):
return Response({'error': 'Selection period is closed'}, status=status.HTTP_400_BAD_REQUEST)
# 检查课程容量
if class_obj.current_students >= class_obj.capacity:
return Response({'error': 'Class is full'}, status=status.HTTP_400_BAD_REQUEST)
# 检查是否已经选过该课程
if Selection.objects.filter(student=student, class_obj=class_obj).exists():
return Response({'error': 'Already selected this class'}, status=status.HTTP_400_BAD_REQUEST)
# 使用事务保证数据一致性
with transaction.atomic():
selection = Selection.objects.create(
student=student,
class_obj=class_obj,
status='selected'
)
class_obj.current_students += 1
class_obj.save()
return Response({'message': 'Selection successful'}, status=status.HTTP_201_CREATED)
选课业务规则:
- 选课时间必须在课程设置的选课开放期内
- 课程人数不能超过容量限制
- 学生不能重复选择同一门课程
- 使用数据库事务保证选课操作的原子性
4.3 课程管理模块
课程管理功能主要面向教师和管理员:
python复制# courses/views.py
from rest_framework import viewsets
from rest_framework.permissions import IsAuthenticated, IsAdminUser
from .models import Course
from .serializers import CourseSerializer
from .permissions import IsTeacherOrAdmin
class CourseViewSet(viewsets.ModelViewSet):
queryset = Course.objects.all()
serializer_class = CourseSerializer
def get_permissions(self):
if self.action in ['create', 'update', 'partial_update', 'destroy']:
permission_classes = [IsAuthenticated, IsTeacherOrAdmin]
else:
permission_classes = [IsAuthenticated]
return [permission() for permission in permission_classes]
def perform_create(self, serializer):
serializer.save(created_by=self.request.user)
权限控制:
- 所有用户都可以查看课程列表
- 只有教师和管理员可以创建、修改、删除课程
- 课程创建者自动记录为当前用户
5. 系统测试与部署
5.1 测试策略
为了保证系统质量,我采用了多种测试方法:
- 单元测试:使用Django的TestCase测试各个模块的功能
- 集成测试:测试模块间的交互和接口
- 性能测试:使用Locust模拟高并发选课场景
- 安全测试:检查SQL注入、XSS等常见安全漏洞
5.2 测试案例示例
选课功能测试案例
| 测试场景 | 测试步骤 | 预期结果 | 实际结果 | 通过与否 |
|---|---|---|---|---|
| 正常选课 | 1. 学生登录 2. 选择开放选课的课程 3. 提交选课请求 |
选课成功,课程人数+1 | 符合预期 | ✔ |
| 选已满课程 | 1. 学生登录 2. 选择已满员的课程 3. 提交选课请求 |
返回"课程已满"错误 | 符合预期 | ✔ |
| 重复选课 | 1. 学生登录 2. 选择已选过的课程 3. 提交选课请求 |
返回"已选过该课程"错误 | 符合预期 | ✔ |
| 非选课时间 | 1. 学生登录 2. 选择未开放选课的课程 3. 提交选课请求 |
返回"不在选课时间内"错误 | 符合预期 | ✔ |
5.3 部署方案
系统采用Docker容器化部署,主要组件包括:
- Web服务:Gunicorn + Nginx
- 数据库:MySQL 8.0
- 缓存:Redis
- 监控:Prometheus + Grafana
部署架构图:
code复制客户端 → Nginx(负载均衡) → Gunicorn(Django应用)
↘ MySQL
↘ Redis
6. 项目总结与经验分享
6.1 技术难点与解决方案
- 高并发选课问题
- 问题:选课高峰期可能出现大量并发请求,导致系统响应变慢甚至崩溃
- 解决方案:
- 使用数据库行级锁(select_for_update)防止超选
- 引入Redis缓存热门课程信息
- 采用消息队列异步处理非核心业务
- 权限管理复杂性
- 问题:系统有学生、教师、管理员多种角色,权限控制复杂
- 解决方案:
- 基于Django的权限系统进行扩展
- 使用装饰器和Mixin实现细粒度权限控制
- 编写自定义权限类(如IsTeacherOrAdmin)
- 前后端分离带来的挑战
- 问题:前后端分离架构下,API设计和跨域问题
- 解决方案:
- 使用Django REST framework构建规范的API
- 配置CORS中间件处理跨域请求
- 使用Swagger生成API文档
6.2 项目收获
通过这个项目的实践,我获得了以下宝贵的经验:
- Django高级特性应用:深入掌握了Django ORM、中间件、信号等高级特性
- 系统架构设计能力:学会了如何设计可扩展、可维护的系统架构
- 性能优化技巧:掌握了数据库优化、缓存策略等性能调优方法
- 全栈开发经验:从前端到后端,从开发到部署的全流程实践经验
6.3 给开发者的建议
基于我在这个项目中的经验,给正在开发类似系统的开发者几点建议:
- 重视数据库设计:良好的数据库设计是系统稳定性的基础,要花足够时间设计合理的表结构和关系
- 考虑并发场景:选课系统等高并发场景要特别注意数据一致性问题,合理使用锁和事务
- 完善的测试:不要忽视测试的重要性,特别是自动化测试可以大大提高代码质量
- 文档很重要:无论是代码注释、API文档还是部署文档,都要保持及时更新
- 性能监控:上线后要建立完善的监控系统,及时发现和解决问题
这个Django学生选课系统项目从需求分析到最终部署,历时3个月完成。它不仅满足了我毕业设计的要求,更是一个可以实际应用的系统。通过这个项目,我不仅巩固了Django开发技能,还学到了很多系统设计和性能优化的实战经验。希望我的分享能给正在开发类似系统的同学一些启发和帮助。