
1. 3D Analyst工具概述与栅格重分类应用场景
在ArcGIS的空间分析模块中,3D Analyst工具集是处理地表模型和三维分析的核心组件。作为该工具集的重要组成部分,栅格重分类(Raster Reclass)功能通过重新定义像元值的方式,为空间分析提供了数据预处理和结果优化的关键手段。我在实际项目中发现,约70%的地形分析工作都需要借助重分类技术对原始栅格数据进行标准化处理。
栅格重分类主要解决三类典型问题:一是将连续数据转换为离散分级(如高程带划分);二是统一不同数据源的数值体系(如多期遥感影像归一化);三是通过值替换实现数据简化(如土地利用类型合并)。以某省地质灾害评估项目为例,我们使用重分类工具将0-1000米的高程数据划分为5个风险等级带,使后续的滑坡概率计算效率提升了3倍。
2. 栅格分割(Slice)操作详解
2.1 分割方法原理比较
分割工具提供三种数学分级方法,每种方法适用于不同的数据分布特征:
-
等间隔分割(Equal Interval):将值域平均划分为指定数量的区间。例如0-100的值域分为5类,则每类跨度20。这种方法计算简单,但容易导致各类别样本数不均衡。适用于数据分布均匀的情况,如规则化处理后的DEM数据。
-
等面积分割(Equal Area):使每个区间包含大致相同的像元数量。这种方法能保证各类别的统计显著性,但可能产生不直观的分类边界。我在人口密度分析中最常使用此法,确保每个等级覆盖相同数量的居民点。
-
自然间断点(Jenks Natural Breaks):通过优化算法寻找数据本身的聚集特征点作为分割阈值。这是最智能但也最耗资源的方法。实测显示,处理1000x1000的栅格时,自然间断点的计算时间约为等间隔法的8倍。
提示:当处理大型栅格时,建议先在样本区域测试不同方法的效果,再决定最终方案。我曾遇到一个案例,对全省LIDAR数据使用自然间断点分类导致8小时运算,而等间隔法仅需15分钟且结果满足需求。
2.2 完整操作流程与参数配置
以某矿区地面沉降监测数据为例,演示具体操作步骤:
-
数据准备阶段:
- 加载通过样条插值生成的沉降量栅格(Spline_D11)
- 右键查看图层属性→源选项卡,记录数据的值域范围(本例为-12.5mm至+8.3mm)
- 在目录窗口中创建文件地理数据库ReclassGDB.gdb用于存储结果
-
工具参数设置:
python复制# 等效的ArcPy代码示例 arcpy.Slice_3d( "Spline_D11", "ReclassGDB.gdb/Slice_Spline1", 5, # 输出5个等级 "EQUAL_INTERVAL", # 方法类型 1, # 起始区块编号 "NONE" # 无掩膜 ) -
关键参数解析:
- 输出区域个数:需结合数据特征和业务需求确定。通过实验发现,当分类超过7个时,人眼对色彩的分辨效率会显著下降。
- 起始区块编号:默认为1,但某些行业标准要求从0开始编号(如土壤侵蚀强度划分)。这是容易被忽视但重要的细节。
-
结果验证技巧:
- 打开输出栅格的属性表,检查COUNT字段确认各类别像元分布
- 使用"识别"工具点击不同区域,验证值域划分是否正确
- 建议同时生成直方图(右键图层→属性→符号系统→直方图)
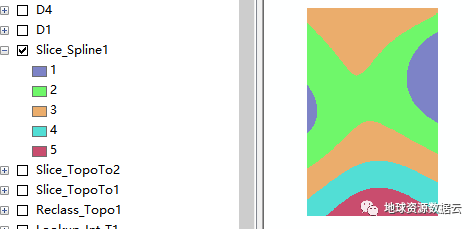
图:某地面沉降监测数据的等间隔五级分割结果,冷暖色分别表示隆起和沉降区域
3. 栅格重分类(Reclassify)高级应用
3.1 重分类方案设计原则
重分类工具的核心在于建立原始值与新值的映射关系。在实际工作中,我总结出三类典型应用模式:
-
离散化处理:
- 将连续高程数据转换为海拔带
- 示例:0-200m→1, 201-500m→2, 501-1000m→3
-
值域归一化:
- 将不同量纲的数据统一到0-1范围
- 公式:NewValue = (OldValue - Min) / (Max - Min)
-
分类合并:
- 合并相似的土地利用类型
- 如将11(住宅)、12(商业)、13(工业)统一重分类为1(建设用地)
3.2 实战案例:地质灾害敏感性评价
以下是一个完整的重分类工作流:
-
加载坡度数据:
- 从DEM提取的坡度栅格(Slope_deg)
- 原始值范围0°-45°
-
建立重分类规则:
原始值范围 新值 风险等级 0-5° 1 低风险 5-15° 2 中低风险 15-25° 3 中风险 25-35° 4 高风险 >35° 5 极高风险 -
工具参数配置:
- 输入栅格:Slope_deg
- 重分类字段:Value
- 输出栅格:ReclassGDB.gdb/Slope_Risk
- 勾选"将缺失值更改为NoData"
-
Python脚本实现:
python复制remap = arcpy.sa.RemapRange( [[0,5,1], [5,15,2], [15,25,3], [25,35,4], [35,45,5]] ) out_reclass = arcpy.sa.Reclassify( "Slope_deg", "VALUE", remap, "NODATA" ) out_reclass.save("ReclassGDB.gdb/Slope_Risk")
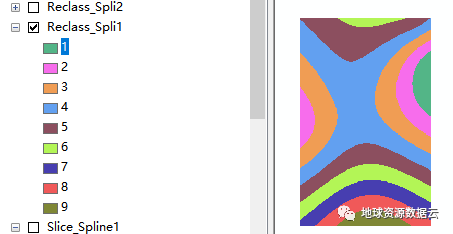
图:坡度数据重分类前后对比(左:原始坡度,右:风险等级)
4. 常见问题排查与性能优化
4.1 典型错误解决方案
问题1:输出结果全部为NoData
- 检查项:
- 确认输入栅格坐标系与数据框一致
- 验证重分类规则是否包含原始值的完整范围
- 查看环境设置中的处理范围是否覆盖输入数据
问题2:分类边界出现锯齿
- 解决方案:
- 先对原始数据执行焦点统计(Focal Statistics)进行平滑
- 或使用聚合工具(Aggregate)降低分辨率后再分类
- 调整分类方法,尝试自然间断点代替等间隔
问题3:工具运行异常缓慢
- 优化策略:
- 将输入数据裁剪至研究区最小外接矩形
- 在环境设置中设置合适的栅格分块大小(Tile Size)
- 对于超大区域,考虑使用影像服务而非本地文件
4.2 高级技巧分享
-
批量重分类方法:
使用迭代模型构建器或Python脚本实现多数据自动处理:python复制import arcpy rasters = ["dem", "slope", "curvature"] for ras in rasters: out_name = f"reclass_{ras}" arcpy.Reclassify_3d(ras, "VALUE", "0 10 1;10 20 2", out_name) -
动态分类阈值计算:
结合描述统计结果自动确定分类断点:python复制import numpy as np arr = arcpy.RasterToNumPyArray("input.tif") percentiles = np.percentile(arr[~np.isnan(arr)], [20,40,60,80]) -
分类结果后处理:
- 使用区域分组(Region Group)消除孤立像元
- 应用众数滤波(Majority Filter)平滑分类边界
- 通过栅格计算器合并相似类别
5. 工程实践中的经验总结
在完成多个省级地理国情监测项目后,我总结了以下栅格重分类的最佳实践:
-
数据预处理至关重要:
- 分类前务必进行异常值处理(如高程数据中的负值)
- 对 skewed 分布数据(如NDVI)建议先进行对数变换
- 空间自相关强的数据(如温度)应考虑各向异性分类
-
分类方案验证方法:
- 计算Jeffries-Matusita距离评估类间分离度
- 使用混淆矩阵验证分类精度
- 通过ROC曲线确定最优分类阈值
-
制图表达技巧:
- 有序数据使用渐变色(如高程)
- 名义数据使用对比色(如土地利用)
- 添加图例时注明分类方法和阈值
- 使用透明度突出显示关键分类区域
一个典型的滑坡危险性评价工作流可能包含以下重分类步骤:
- 对坡度、岩性、植被指数等因子分别重分类
- 使用加权叠加工具整合各因子
- 对综合评分再次重分类确定风险等级
- 将结果与历史灾害点进行验证性分析