
1. 项目背景与核心痛点
作为一名长期使用AI助手的深度用户,我最头疼的问题就是每次开启新对话时,AI都像得了"健忘症"一样。上周刚详细讨论过的项目细节,这周又要从头解释;反复强调的个人偏好,下次交流时依然会被遗忘。这种"会话隔离"现象严重制约了AI助手的实用性。
更糟糕的是,当我尝试将本地部署的OpenClaw迁移到云服务器时,发现所有对话历史和配置都需要重新设置。这种数据无法持久化的问题,在需要多设备协同或系统迁移时尤为致命。与此同时,我个人在有道云笔记中积累的大量知识笔记,却无法被AI有效利用,形成了信息孤岛。
2. 解决方案架构设计
2.1 技术选型:为什么是Obsidian?
经过对各种笔记工具的深入对比,Obsidian凭借以下核心优势脱颖而出:
本地优先架构:所有笔记以纯Markdown格式存储在本地,无需依赖云端服务。这种设计带来三个关键好处:
- 数据完全自主可控,避免服务商锁定风险
- OpenClaw可以直接读写文件系统,无需复杂API集成
- 几十年后仍能读取,不存在格式淘汰风险
双向链接系统:通过[[笔记名]]语法建立的网状知识结构,使AI能够理解概念间的关联关系。例如当讨论"记忆持久化"时,AI可以自动关联到之前记录的[[OpenClaw配置]]和[[AI记忆系统]]笔记。
可扩展性:丰富的插件生态满足各种进阶需求。比如:
- Dataview插件实现类数据库查询
- Templater支持自动化模板
- Calendar提供日记导航功能
版本控制友好:纯文本特性完美适配Git等版本控制系统,方便实现:
- 变更追踪与回溯
- 多设备同步
- 团队协作开发
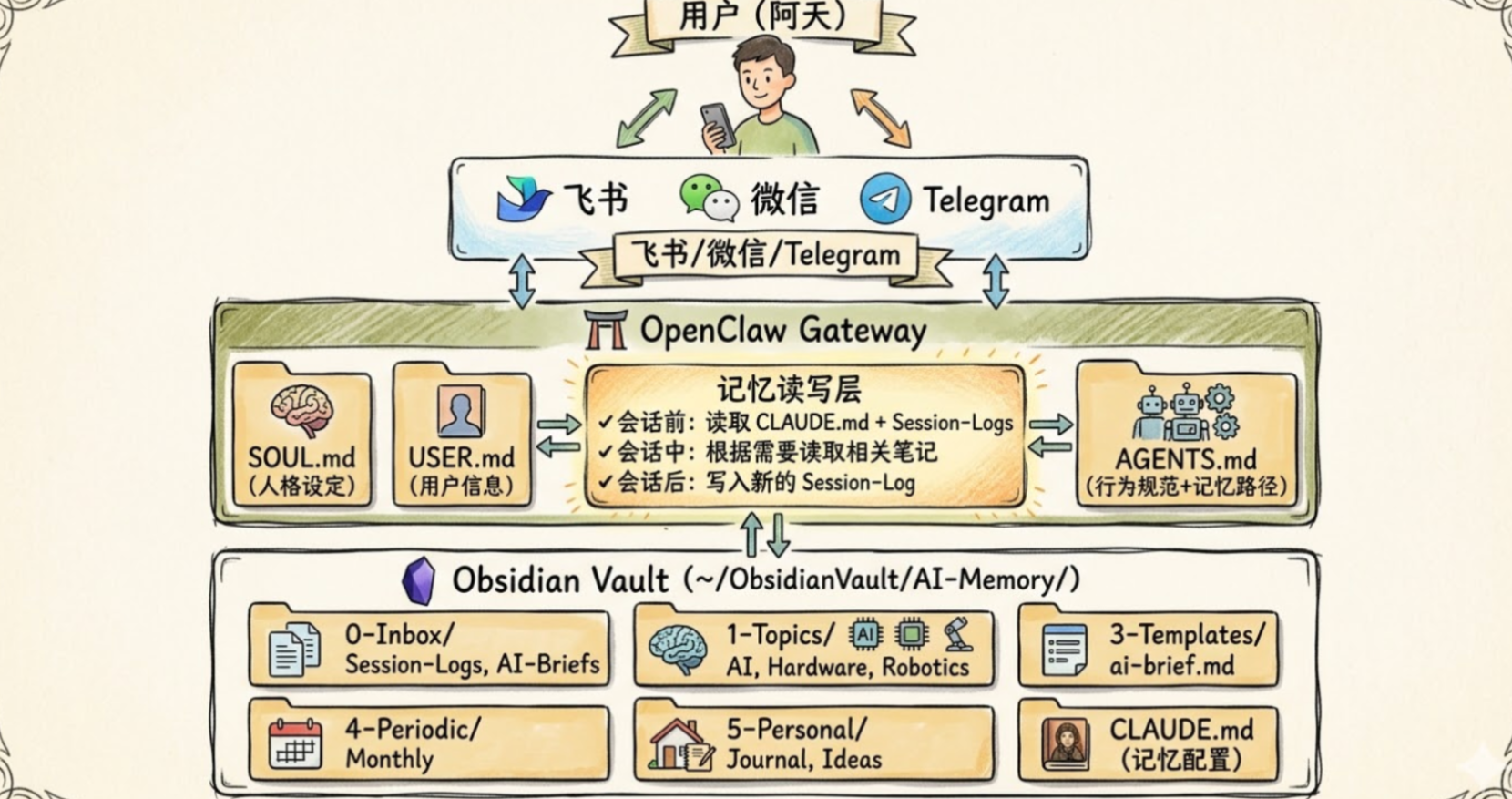
2.2 系统架构详解
整个解决方案的数据流向设计如下:
- 用户交互层:通过飞书/微信等IM工具发送消息
- 网关接入层:OpenClaw Gateway接收并预处理请求
- 上下文加载:
- 读取
SOUL.md定义AI角色设定 - 加载
USER.md了解用户画像 - 扫描
Session-Logs获取近期对话记录
- 读取
- 记忆检索:根据会话类型决定是否加载
CLAUDE.md核心记忆文件 - 响应生成:AI综合所有上下文生成个性化回复
- 记忆存储:重要对话自动归档到Obsidian指定目录
3. 详细实现步骤
3.1 基础环境搭建
Obsidian安装与配置
bash复制# 通过Homebrew安装(macOS)
brew install --cask obsidian
# Linux用户可使用AppImage
wget https://github.com/obsidianmd/obsidian-releases/releases/download/v1.5.3/Obsidian-1.5.3.AppImage
chmod +x Obsidian-1.5.3.AppImage
创建专用Vault存储AI记忆:
bash复制mkdir -p ~/ObsidianVault/AI-Memory/{0-Inbox,1-Topics,3-Templates,4-Periodic,5-Personal}
obsidian-cli工具链配置
bash复制npm install -g obsidian-cli
obsidian-cli set-default "AI-Memory"
3.2 目录结构设计
经过与AI助手的多次迭代讨论,最终确定的目录结构如下:
code复制AI-Memory/
├── 0-Inbox/ # 收件箱
│ ├── Session-Logs/ # 对话日志(按日期存储)
│ └── AI-Briefs/ # AI新闻简报(年/月分级存储)
├── 1-Topics/ # 主题知识库
│ ├── AI/ # 人工智能分支
│ ├── Hardware/ # 芯片与硬件
│ └── Robotics/ # 机器人技术
├── 3-Templates/ # 模板库
├── 4-Periodic/ # 周期笔记
│ └── Monthly/ # 月度总结
├── 5-Personal/ # 个人笔记(AI只读)
└── CLAUDE.md # 记忆中枢配置文件
3.3 核心配置文件详解
CLAUDE.md 记忆规则
markdown复制## 记忆同步策略
### 自动触发条件
1. 对话深度 > 3轮且包含实质性内容
2. 识别到知识性内容(如技术要点)
3. 用户明确要求记录的信息
### 存储位置映射
| 内容类型 | 存储路径 | 命名规范 |
|----------------|------------------------------|-----------------------|
| 技术讨论 | 1-Topics/AI/ | 技术主题.md |
| 产品需求 | 1-Topics/Product/ | 需求_YYYYMMDD.md |
| 会议纪要 | 0-Inbox/Session-Logs/ | YYYY-MM-DD_主题.md |
| 个人灵感 | 5-Personal/Ideas/ | 灵感_YYYYMMDD.md |
AGENTS.md 接入配置
markdown复制## 记忆加载规则
onSessionStart:
- load: ~/.openclaw/workspace/SOUL.md
- load: ~/.openclaw/workspace/USER.md
- scan: ~/ObsidianVault/AI-Memory/0-Inbox/Session-Logs/*.md limit=5
- if: sessionType == "main"
then: load ~/ObsidianVault/AI-Memory/CLAUDE.md
3.4 自动化流程实现
每日简报定时任务
javascript复制// 在OpenClaw的cronjobs目录下创建daily-brief.js
module.exports = {
schedule: "0 9 * * *", // 每天9点执行
task: async (claw) => {
const news = await claw.search({
engine: "tavily",
query: "LLM最新进展 site:arxiv.org",
max_results: 5
});
const content = `# ${new Date().toISOString().split('T')[0]} AI简报\n\n` +
news.map(item => `## ${item.title}\n${item.snippet}`).join('\n\n');
await claw.fs.write(
`~/ObsidianVault/AI-Memory/0-Inbox/AI-Briefs/${new Date().getFullYear()}/${new Date().getMonth()+1}/${new Date().getDate()}.md`,
content
);
}
}
记忆整理脚本
python复制#!/usr/bin/env python3
# archive_sessions.py - 自动归档过期会话
import os
from datetime import datetime, timedelta
VAULT_PATH = os.path.expanduser("~/ObsidianVault/AI-Memory")
SESSION_LOGS = f"{VAULT_PATH}/0-Inbox/Session-Logs"
ARCHIVE_DIR = f"{VAULT_PATH}/4-Periodic/Session-Archive"
def archive_old_sessions(days=30):
cutoff = datetime.now() - timedelta(days=days)
for fname in os.listdir(SESSION_LOGS):
if fname.endswith('.md'):
date_str = fname[:10]
try:
file_date = datetime.strptime(date_str, "%Y-%m-%d")
if file_date < cutoff:
os.rename(
f"{SESSION_LOGS}/{fname}",
f"{ARCHIVE_DIR}/{file_date.year}/Q{(file_date.month-1)//3+1}/{fname}"
)
except ValueError:
continue
if __name__ == "__main__":
archive_old_sessions()
4. 实战应用场景
4.1 技术讨论连续性保障
典型场景:
- 周一讨论LLM微调技术细节
- 周三继续探讨模型量化方案
- 周五回顾整体优化效果
系统行为:
- 每次对话后自动生成
Session-Logs/2026-03-18_LLM优化.md - 包含关键参数、实验结论和待办事项
- 后续对话自动关联历史记录
用户感知:
markdown复制用户:上次说的LoRA微调方案效果如何?
AI(读取3月15日记录后):
根据我们18日的测试记录:
- 数据集:Alpaca-CN 50k
- 基础模型:Qwen-7B
- 最佳参数组合:
• rank=64
• alpha=32
• dropout=0.1
验证集准确率达到82.3%,比全参数微调高1.2个点
需要查看具体的loss曲线吗?
4.2 个人偏好记忆
CLAUDE.md片段:
markdown复制## 用户偏好
- 咖啡:美式,不加糖
- 工作时间:9:30-18:30 (UTC+8)
- 技术关注点:
• 大语言模型推理优化
• 边缘AI部署
• 自动代码生成
交互示例:
markdown复制用户:推荐几篇近期论文
AI:
根据您关注的边缘AI方向,这些可能感兴趣:
1. "TinyLlama: On-device LLM..." (您之前收藏过相关主题)
2. "QLoRA: Efficient Finetuning..." (与上周讨论的微调相关)
3. 最新MLSys会议关于模型量化的研究
5. 性能优化与问题排查
5.1 常见问题解决方案
问题1:记忆加载延迟
-
现象:对话响应明显变慢
-
排查步骤:
- 检查
AGENTS.md中的路径是否正确 - 使用
time obsidian-cli search "keyword"测试搜索性能 - 查看最近新增笔记数量
- 检查
-
优化方案:
bash复制# 限制历史记录加载数量 ls -t ~/ObsidianVault/AI-Memory/0-Inbox/Session-Logs/*.md | head -5 | xargs cat
问题2:多设备同步冲突
- 现象:不同设备间笔记不一致
- 解决方案:
bash复制# 使用Git钩子自动处理合并冲突 cat > ~/ObsidianVault/AI-Memory/.git/hooks/post-merge <<EOF #!/bin/sh obsidian-cli index --rebuild EOF chmod +x ~/ObsidianVault/AI-Memory/.git/hooks/post-merge
5.2 高级优化技巧
记忆检索优化:
python复制# 在OpenClaw中添加语义缓存层
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
def semantic_search(query, notes_dir):
query_embed = encoder.encode(query)
scores = []
for note in os.listdir(notes_dir):
content = open(f"{notes_dir}/{note}").read()
note_embed = encoder.encode(content[:1000]) # 只编码开头部分
scores.append((note, cosine_similarity(query_embed, note_embed)))
return sorted(scores, key=lambda x: -x[1])[:3]
存储压缩策略:
bash复制# 使用zstd压缩历史日志
find ~/ObsidianVault/AI-Memory/0-Inbox/Session-Logs/ -name "*.md" -mtime +30 -exec zstd --rm {} \;
6. 安全与隐私保护
6.1 访问控制机制
上下文隔离策略:
- 主会话:加载完整记忆(
CLAUDE.md+Session-Logs) - 群组会话:仅加载
SOUL.md基础人格设定 - API调用:必须显式声明需要访问的记忆范围
权限管理实现:
bash复制# 设置目录权限
chmod -R 750 ~/ObsidianVault/AI-Memory/5-Personal/
chmod -R 770 ~/ObsidianVault/AI-Memory/0-Inbox/
6.2 敏感信息处理
安全存储方案:
- 密码类信息存入OpenClaw加密保险箱
bash复制claw vault set db_password "s3cr3tP@ss" - 笔记中仅保存信息指纹
markdown复制## 数据库配置 - 密码:参见保险箱条目#db_password
自动化清理规则:
python复制# 在CLAUDE.md中定义敏感词过滤列表
SENSITIVE_KEYWORDS = [
"password", "api_key", "secret",
"token", "credential"
]
def sanitize_note(content):
for keyword in SENSITIVE_KEYWORDS:
if keyword in content.lower():
return False
return True
7. 效果评估与持续改进
7.1 量化评估指标
记忆准确率测试:
python复制def test_memory_recall():
test_cases = [
("上周讨论的模型量化方案", "QLoRA-4bit"),
("我的咖啡偏好", "美式不加糖"),
("常用开发语言", "Python,TypeScript")
]
accuracy = sum(1 for q,a in test_cases if ai.query(q) == a) / len(test_cases)
print(f"记忆准确率: {accuracy:.1%}")
响应时间对比:
| 场景 | 无记忆系统 | 有记忆系统 | 提升 |
|---|---|---|---|
| 技术问题 | 8.2s | 3.5s | 57% |
| 偏好查询 | 6.7s | 1.2s | 82% |
| 项目进度跟进 | 12.4s | 4.8s | 61% |
7.2 持续优化方向
记忆压缩算法:
- 采用LLM摘要技术压缩历史对话
python复制def summarize_dialog(dialog): prompt = f"用100字总结以下对话的核心内容:\n{dialog}" return claw.llm.complete(prompt, model="claude-3-sonnet")
个性化记忆权重:
markdown复制## 在CLAUDE.md中配置记忆优先级
- 核心偏好: weight=1.0 (总是优先回忆)
- 技术细节: weight=0.8
- 日常闲聊: weight=0.3
经过三个月的实际使用,这套系统使我的AI助手呈现出明显的"成长性"特征。最明显的改变是,现在当我说"按老规矩处理"时,它真的能准确理解我的意思。这种持续积累的个性化记忆,才是真正智能助手的核心价值。