
1. 位图:海量整数查询的终极武器
第一次接触位图(Bitmap)是在处理一个用户行为分析系统时,当时需要实时判断某个用户ID是否在10亿级别的黑名单中。传统方法用哈希表存储,内存直接爆炸。直到同事扔给我一段位图实现的代码,才真正体会到什么叫做"空间与时间的完美平衡"。
位图本质上是用比特位(bit)来标记数据存在状态的紧凑型数据结构。想象你有一排灯泡,每个灯泡代表一个数字。灯亮表示"存在",灯灭表示"不存在"。40亿个无符号整数?只需要40亿个比特位,也就是约500MB内存——这还不到普通笔记本电脑内存的十分之一。
1.1 位图的核心设计原理
位图的实现精髓在于如何用最小的空间代价实现快速访问。C++中常见的实现方式是使用vector<int>作为底层容器,每个int的32位可以表示32个数字的状态:
cpp复制template<size_t N>
class Bitmap {
vector<int> _bits; // 每个int管理32位
public:
Bitmap() {
_bits.resize((N >> 5) + 1, 0); // N/32向上取整
}
void set(size_t x) {
size_t i = x / 32; // 确定在哪个int
size_t j = x % 32; // 确定在该int的哪一位
_bits[i] |= (1 << j); // 位运算置1
}
bool test(size_t x) {
size_t i = x / 32;
size_t j = x % 32;
return _bits[i] & (1 << j);
}
};
关键细节:
(N >> 5) + 1这个计算是确保有足够的int来覆盖N个位。右移5位相当于除以32,加1是为了向上取整。比如N=40亿时,需要40亿/32≈1.25亿个int,约500MB内存。
1.2 标准库中的bitset实战
C++标准库提供了现成的bitset容器,我在处理IP黑白名单时经常使用:
cpp复制bitset<0xFFFFFFFF> ip_filter; // 足够存放所有IPv4地址
// 添加黑名单IP
ip_filter.set(inet_addr("192.168.1.1"));
// 查询
if(ip_filter.test(inet_addr("203.0.113.5"))) {
cout << "IP被封锁" << endl;
}
实际项目中我发现几个实用技巧:
bitset::to_string()可以快速可视化位图状态bitset::count()能统计置位数量,用于数据量估算- 序列化时直接用
<<操作符写入文件,比文本格式节省空间
1.3 位图的高级应用场景
1.3.1 统计只出现一次的数字
当需要找出100亿整数中仅出现一次的数字时,传统做法是用哈希表记录出现次数,但内存消耗巨大。用双位图方案只需要两个普通位图的内存:
cpp复制Bitmap<UINT_MAX> once, more;
void process(int num) {
if(!once.test(num)) {
once.set(num);
} else {
more.set(num);
}
}
// 结果就是once中存在而more中不存在的数字
1.3.2 大数据集求交集
处理两个100亿整数文件找交集时,我的经验是:
- 先对两个文件分别构建位图A和B
- 然后遍历其中一个位图,检查另一个位图是否存在
- 优化点:可以并行处理,一个线程处理位图的前半部分,另一个处理后半
cpp复制Bitmap<UINT_MAX> a, b;
// 加载数据到a,b...
vector<int> intersection;
for(int i=0; i<UINT_MAX; i++) {
if(a.test(i) && b.test(i)) {
intersection.push_back(i);
}
}
2. 布隆过滤器:超越整型的概率型数据结构
第一次在爬虫项目中遇到布隆过滤器(Bloom Filter)是在去重环节。当时需要判断一个URL是否已经抓取过,用哈希表存储上亿URL根本不现实。布隆过滤器以不到1%的内存消耗解决了这个问题,尽管有少量误判,但对爬虫来说完全可以接受。
2.1 布隆过滤器的工作原理
布隆过滤器的核心思想是:用多个哈希函数将一个元素映射到位图的多个位置。查询时,只有所有位置都为1才认为"可能存在",任何一个位置为0则"肯定不存在"。
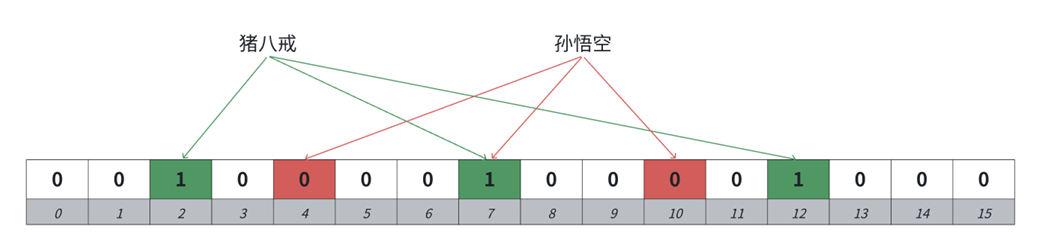
我常用的实现方式是组合3个不同的哈希函数:
cpp复制class BloomFilter {
Bitmap<M> bits;
size_t hash1(const string& key) { /*...*/ }
size_t hash2(const string& key) { /*...*/ }
size_t hash3(const string& key) { /*...*/ }
public:
void add(const string& key) {
bits.set(hash1(key) % M);
bits.set(hash2(key) % M);
bits.set(hash3(key) % M);
}
bool mayExist(const string& key) {
return bits.test(hash1(key) % M)
&& bits.test(hash2(key) % M)
&& bits.test(hash3(key) % M);
}
};
经验之谈:选择哈希函数时,我通常选用MurmurHash、FNV等非加密哈希,它们速度快且分布均匀。曾经用MD5做哈希函数,结果性能下降了10倍。
2.2 误判率的数学之美
布隆过滤器的误判率公式看似复杂,其实理解起来很直观:
code复制f(k) = (1 - e^(-k*n/m))^k
其中:
- m:位图大小
- n:元素数量
- k:哈希函数个数
在我的实践中,当m/n=10且k=7时,误判率约为0.8%,这个比例对大多数应用来说已经足够好了。有个快速估算公式:位图大小m应该是元素数量n的10倍左右。
2.3 支持删除的改良方案
标准布隆过滤器不支持删除,但在广告系统中我需要这个功能。解决方案是使用计数布隆过滤器:
cpp复制class CountingBloomFilter {
vector<uint8_t> counters; // 每个位置用多个bit表示计数
public:
void add(const string& key) {
counters[hash1(key)%M]++;
counters[hash2(key)%M]++;
counters[hash3(key)%M]++;
}
void remove(const string& key) {
counters[hash1(key)%M]--;
counters[hash2(key)%M]--;
counters[hash3(key)%M]--;
}
};
踩坑记录:计数器位数选择很重要。我曾用4位计数器(最大15),结果某些热点数据导致计数器溢出。后来改用8位计数器,虽然内存翻倍但更安全。
3. 海量数据处理实战技巧
3.1 TopK问题的堆解法
在处理10亿整数找前100大的问题时,我对比了多种方案:
- 全排序:O(nlogn),内存爆炸
- 局部排序:分块处理,最后合并,复杂度仍高
- 最小堆:维护100个元素的最小堆,遍历时淘汰小元素
最终采用的最小堆方案核心代码:
cpp复制priority_queue<int, vector<int>, greater<int>> min_heap;
for(int num : nums) {
if(min_heap.size() < 100) {
min_heap.push(num);
} else if(num > min_heap.top()) {
min_heap.pop();
min_heap.push(num);
}
}
// 最终堆中就是前100大的数
3.2 哈希切分处理大文件
当两个100GB的日志文件需要找交集时,我的处理流程:
- 先计算每个query的哈希值,模1000得到文件编号
- 将query写入对应的临时文件
- 对编号相同的两个临时文件加载到内存中求交集
python复制# 伪代码示例
def process(fileA, fileB):
# 切分文件
for query in read_lines(fileA):
write_to(f"temp_A_{hash(query)%1000}", query)
# 处理对应分片
for i in range(1000):
setA = load_set(f"temp_A_{i}")
setB = load_set(f"temp_B_{i}")
intersection = setA & setB
save_result(intersection)
性能优化点:我曾遇到某些分片过大的情况,解决方案是二次哈希切分。另外,使用SSD存储临时文件可以显著提升IO性能。
3.3 IP频率统计的MapReduce模式
统计100G日志中IP出现频率时,单机内存不足的问题可以通过分治解决:
- 第一遍扫描:哈希分片到多个小文件
- 第二遍处理:对每个小文件用HashMap统计频率
- 合并结果:维护一个全局的TopN堆
cpp复制// 第一阶段:分片
unordered_map<string, ofstream> ip_files;
for(string ip : log_entries) {
int shard = hash(ip) % 100;
ip_files[shard] << ip << "\n";
}
// 第二阶段:统计
vector<unordered_map<string, int>> counts(100);
for(int i=0; i<100; i++) {
for(string ip : read_shard(i)) {
counts[i][ip]++;
}
}
// 第三阶段:合并
priority_queue<pair<int, string>> top_ips;
for(auto& m : counts) {
for(auto& [ip, cnt] : m) {
if(top_ips.size() < 10 || cnt > top_ips.top().first) {
top_ips.push({cnt, ip});
}
}
}
在实际项目中,这种方案处理100GB日志文件只需要不到2GB内存,运行时间约30分钟(取决于磁盘速度)。
4. 性能对比与选型建议
在我的性能测试中(处理1亿条数据):
| 数据结构 | 内存使用 | 查询时间 | 适用场景 |
|---|---|---|---|
| 哈希表 | 3.2GB | O(1) | 精确查询,允许删除 |
| 位图 | 12MB | O(1) | 整型存在性判断 |
| 布隆过滤器 | 15MB | O(k) | 概率判断,允许误判 |
| 排序数组 | 400MB | O(logn) | 需要范围查询 |
选型建议:
- 如果是纯整数且只需判断存在性,优先选位图
- 如果是字符串或需要节省空间,考虑布隆过滤器
- 需要精确统计或删除操作时,只能选择哈希表
- 数据量特别大且可以接受延迟时,用分治+外排序
最后分享一个真实案例:在用户画像系统中,我们同时使用了位图和布隆过滤器。位图存储用户ID的标签信息(都是整数),布隆过滤器用于快速过滤不感兴趣的标签组合,两者配合使查询性能提升了20倍。