
1. Android显示系统核心架构解析
在Android系统中,SurfaceFlinger(简称SF)作为显示系统的核心服务,承担着管理屏幕内容合成的关键职责。它本质上是一个系统级服务进程,运行在独立的surfaceflinger线程中,通过Binder机制与应用程序交互。理解SF的工作原理,对于优化Android应用的UI性能、解决显示相关问题具有重要意义。
现代Android显示系统采用分层架构设计,主要包含以下几个关键组件:
- 应用层:通过Surface与SF交互
- 框架层:包含libgui、libui等核心库
- 系统服务层:SurfaceFlinger服务本身
- 硬件抽象层:HWC(硬件合成器)和Gralloc内存分配器
这种分层设计使得Android能够灵活适配不同硬件设备,同时为应用开发者提供统一的显示接口。
2. SurfaceFlinger的核心职责剖析
2.1 显存管理机制
SF通过Gralloc模块管理图形缓冲区的生命周期,包括:
- 缓冲区的分配与释放
- 缓冲区的共享与传递
- 缓冲区的同步控制
Gralloc作为HAL层模块,具体实现由设备厂商提供。标准的Gralloc实现会通过以下方式管理内存:
- 通过ION或DMABUF机制分配物理连续内存
- 建立内存映射供CPU和GPU访问
- 维护缓冲区的元数据(格式、尺寸等)
cpp复制// 典型的内存分配流程
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
allocator.allocate(width, height, format, usage, &handle, &stride);
2.2 Vsync信号处理模型
SF通过监听硬件Vsync信号来协调UI渲染节奏,其信号处理流程如下:
- HWC产生Vsync事件
- SF接收并处理Vsync信号
- 通过EventThread分发给感兴趣的客户端
- 应用在收到信号后开始新一帧的渲染
这种机制确保了所有UI更新都能以显示设备的刷新率为基准,避免画面撕裂和卡顿。
2.3 图层合成策略
SF采用智能的图层合成策略来决定如何处理多个应用的显示内容:
- 客户端合成:应用自行合成内容后提交最终结果
- 设备合成:由HWC硬件完成合成(更高效)
- 混合合成:部分图层由GPU合成,其余由HWC处理
合成决策基于以下因素动态调整:
- 图层数量
- 图层属性(透明度、变换等)
- 硬件能力支持
3. 关键数据结构深度解析
3.1 BufferQueue工作机制
BufferQueue是Android图形架构中的核心IPC机制,其工作流程如下:
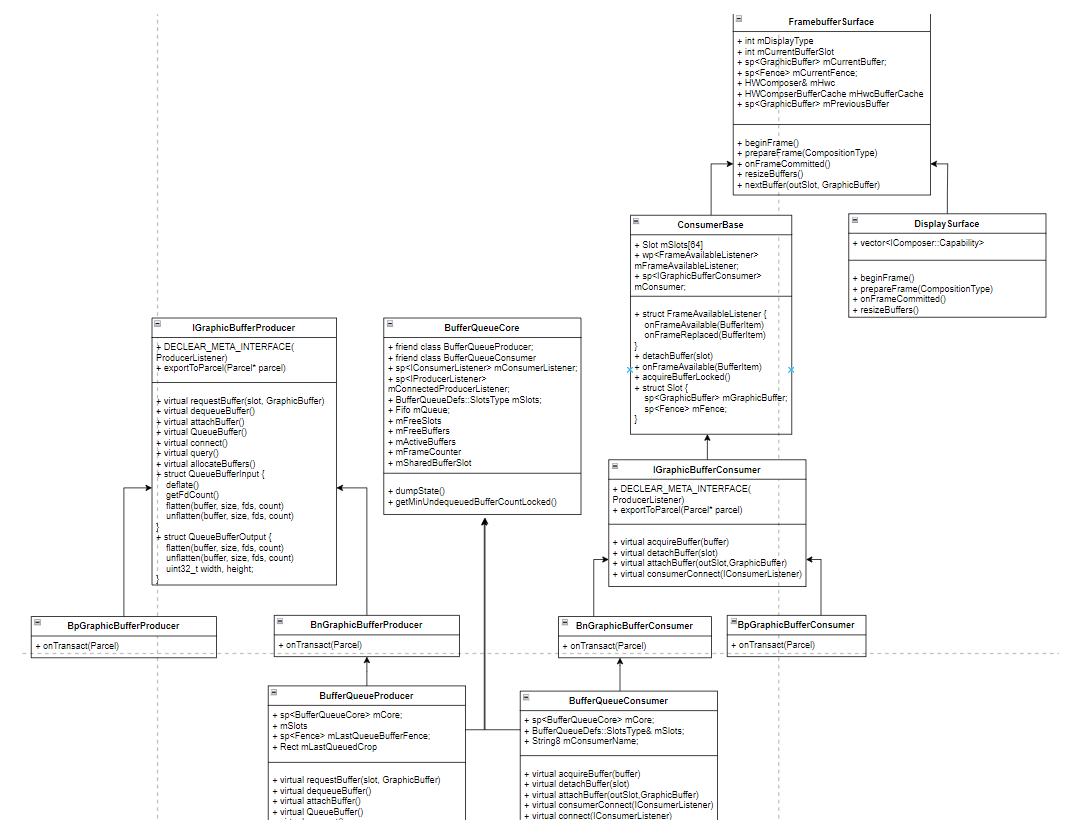
关键组件说明:
- Producer:生产者接口,典型实现是Surface
- Consumer:消费者接口,典型实现是Layer
- Slot数组:管理缓冲区的循环队列
BufferQueue通过三种状态管理缓冲区:
- FREE:空闲可用
- DEQUEUED:被生产者获取
- QUEUED:已提交待消费
3.2 Layer层级管理
SF通过Layer对象管理每个显示层,其关键属性包括:
cpp复制class Layer {
sp<IGraphicBufferProducer> mProducer; // 生产者接口
sp<IGraphicBufferConsumer> mConsumer; // 消费者接口
uint32_t mZ; // Z轴顺序
Rect mBounds; // 显示区域
bool mVisible; // 可见性
};
Layer的典型类型包括:
- BufferLayer:常规应用层
- ColorLayer:纯色背景层
- ContainerLayer:容器层(如SurfaceView)
3.3 Surface与ANativeWindow关系
Surface作为ANativeWindow的实现,提供了本地窗口能力:
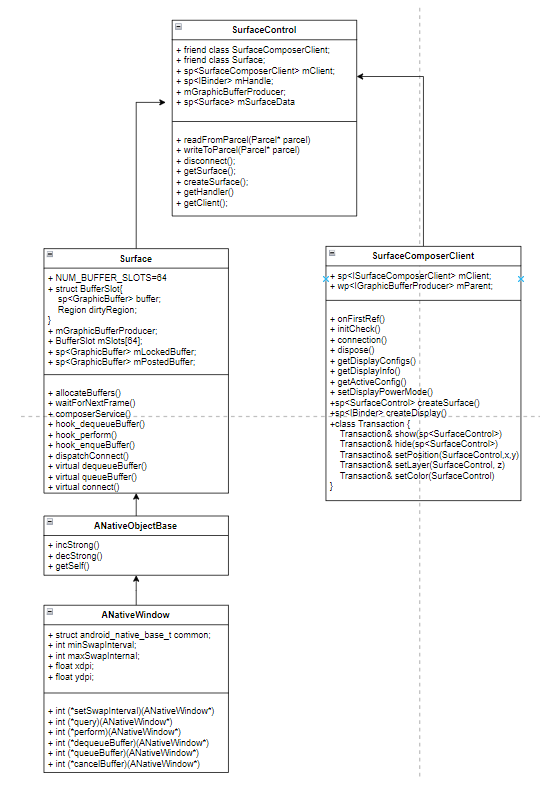
关键方法实现:
cpp复制static int hook_dequeueBuffer(ANativeWindow* window, ANativeWindowBuffer** buffer) {
Surface* surface = static_cast<Surface*>(window);
return surface->dequeueBuffer(buffer);
}
4. 客户端与服务端交互全流程
4.1 应用创建Surface流程
- 创建SurfaceComposerClient
- 通过Client创建SurfaceControl
- 从SurfaceControl获取Surface对象
cpp复制sp<SurfaceComposerClient> client = new SurfaceComposerClient();
sp<SurfaceControl> ctrl = client->createSurface(String8("Test"));
sp<Surface> surface = ctrl->getSurface();
4.2 缓冲区申请与提交机制
锁定缓冲区流程:
- 通过Surface连接到BufferQueue
- 调用dequeueBuffer获取空闲槽位
- 通过requestBuffer获取GraphicBuffer
- 锁定缓冲区获取CPU可访问地址
提交缓冲区流程:
- 解锁缓冲区
- 调用queueBuffer提交到BufferQueue
- SF通过onFrameAvailable回调通知更新
- 触发合成流程
4.3 服务端初始化过程
SF服务启动流程关键步骤:
cpp复制int main() {
sp<SurfaceFlinger> flinger = new SurfaceFlinger();
flinger->init(); // 初始化显示设备
startDisplayService(); // 启动Binder服务
flinger->run(); // 进入主循环
}
5. 显示设备与内存管理
5.1 DisplayDevice工作原理
DisplayDevice代表物理显示设备,主要职责包括:
- 管理显示属性(分辨率、DPI等)
- 处理显示热插拔事件
- 协调缓冲区交换时序
cpp复制void DisplayDevice::setDisplaySize(int width, int height) {
mDisplaySurface->resizeBuffers(width, height);
mSurface->setNativeWindow(mNativeWindow.get());
}
5.2 Gralloc内存分配细节
Gralloc模块通过以下步骤分配图形内存:
- 确定内存需求(大小、格式、用途)
- 选择合适的内存类型(ION/DMABUF)
- 建立CPU/GPU映射关系
- 返回缓冲区句柄
关键参数说明:
GRALLOC_USAGE_HW_FB:帧缓冲区用途GRALLOC_USAGE_SW_READ:CPU读取用途GRALLOC_USAGE_HW_TEXTURE:GPU纹理用途
6. Fence同步机制详解
6.1 Fence核心概念
Fence机制解决了以下同步问题:
- 生产者与消费者之间的缓冲区状态同步
- 跨处理器(CPU/GPU/DPU)操作顺序控制
- 异步操作完成通知
Fence的两种基本状态:
- 未触发:表示相关操作未完成
- 已触发:表示操作已完成
6.2 Fence实现架构
Android Fence实现分为三层:
- 框架层:Fence/FenceTime类
- 库层:libsync同步库
- 驱动层:内核sync/sw_sync驱动
cpp复制// 创建时间轴
int timeline_fd = sw_sync_timeline_create();
// 创建Fence
int fence_fd = sw_sync_fence_create(timeline_fd, "test_fence", 1);
// 等待Fence
sync_wait(fence_fd, 1000);
6.3 Fence与VSync的区别
| 特性 | Fence | VSync |
|---|---|---|
| 本质 | 硬件同步原语 | 定时信号 |
| 作用 | 保证操作顺序 | 协调渲染节奏 |
| 触发方式 | 操作完成时触发 | 固定时间间隔触发 |
| 使用场景 | 缓冲区状态管理 | 帧率同步 |
7. 性能优化实践建议
7.1 应用层优化技巧
- 减少Surface数量:合并多个Surface为一个
- 合理设置缓冲区数量:通常3-4个为宜
- 使用硬件图层:避免不必要的GPU合成
- 优化渲染时序:在VSync信号后立即开始渲染
7.2 系统级调优方向
- 调整合成策略:最大化HWC使用率
- 优化内存访问:减少CPU-GPU数据传输
- 合理设置VSync偏移:平衡各阶段负载
- 监控Fence等待时间:识别性能瓶颈
8. 常见问题排查指南
8.1 画面卡顿分析步骤
- 检查VSync信号是否正常
- 分析Fence等待时间
- 确认是否有过度合成
- 检查内存带宽使用情况
8.2 画面撕裂解决方案
- 确保正确使用VSync同步
- 检查缓冲区交换时序
- 验证Fence信号是否正确
- 调整显示刷新率设置
8.3 内存泄漏排查方法
- 监控GraphicBuffer引用计数
- 检查BufferQueue状态
- 分析Gralloc内存分配记录
- 验证Layer生命周期管理
在实际开发中,理解SurfaceFlinger的内部机制可以帮助开发者更好地优化应用性能,解决复杂的显示问题。建议结合具体使用场景,有针对性地应用这些原理知识。