
1. 事件趋势图的核心价值与应用场景
在工业物联网和智能制造领域,设备产生的时序数据量正呈指数级增长。我曾参与过一个风电场的智能监测项目,单台风机每天就能产生超过200万条数据记录。面对如此海量的数据,传统的数据可视化方式往往难以直观呈现关键事件与数据指标的关联性。这正是TDengine IDMP事件趋势图的价值所在——它通过时间轴上的多维数据叠加和智能高亮,让运维人员一眼就能发现异常事件与数据波动的因果关系。
事件趋势图的核心功能可以概括为三个关键点:
- 时间维度关联:将离散的事件标记与连续的指标曲线在统一时间轴上叠加展示
- 智能交互高亮:通过事件触发自动关联相关指标,并支持交互式聚焦查看
- 多维度对比:支持按事件开始时间对齐的多段数据对比分析
提示:在实际项目中,事件趋势图特别适合用于故障根因分析。比如当某台设备发生温度报警时,可以快速关联查看同一时间段内的振动、电流等关键指标的变化情况。
2. 数据源配置与关联逻辑
2.1 数据源类型详解
在TDengine IDMP平台中,事件趋势图支持三类数据源的添加:
-
属性数据:
- 直接来自设备或传感器的原始测量值(如温度、压力、转速等)
- 采样频率可以从毫秒级到小时级不等
- 配置示例:
添加属性 → 选择设备节点 → 勾选"电机温度"属性
-
事件数据:
- 系统定义的阈值触发事件(如超温报警)
- 机器学习模型检测到的异常事件
- 人工标记的重要操作事件
- 添加事件时会自动关联该事件触发依赖的所有属性指标
-
分析结果:
- 基于SQL或AI模型的计算指标(如设备健康度评分)
- 复合事件(满足多条件组合触发的事件)
- 添加分析时会自动包含分析中引用的所有属性和生成的事件
2.2 数据关联的底层逻辑
当用户添加一个"轴承温度过高"事件时,系统会执行以下自动关联:
- 在元数据管理中查找该事件的定义
- 确定触发该事件的依赖属性(如:轴承温度、环境温度)
- 检索这些属性在事件时间范围内的历史数据
- 将这些属性曲线与事件时间范围标记一起呈现在趋势图中
sql复制-- 类似TDengine内部执行的关联查询逻辑
SELECT ts, temperature
FROM device_sensors
WHERE device_id = 'motor_01'
AND ts BETWEEN event_start_time AND event_end_time
3. 高级分析功能深度解析
3.1 多泳道视图的工程实践
多泳道模式是事件趋势图的默认视图,其设计考量包括:
- 视觉隔离原则:每个指标独占一个水平泳道,避免不同量纲指标的Y轴刻度冲突
- 同步缩放:所有泳道共享同一时间轴,缩放操作会同步影响所有泳道
- 工程应用案例:
- 在光伏电站监控中,将每块光伏板的输出电压、电流、温度分别显示在不同泳道
- 当某块板出现输出异常时,可以快速对比同组其他板的同期数据
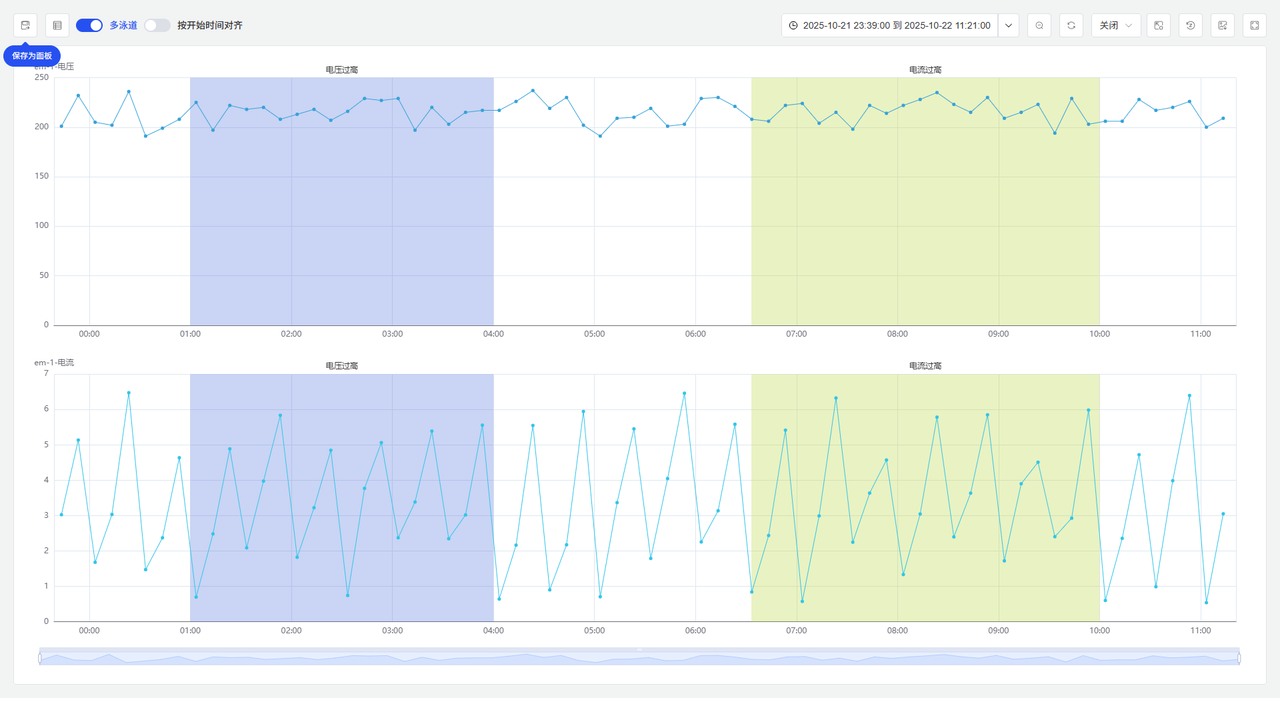
3.2 时间对齐分析的实战技巧
"按开始时间对齐"功能在设备故障模式分析中特别有用。具体操作步骤:
- 选择3-5个同类故障事件(如电机轴承损坏)
- 开启"按开始时间对齐"选项
- 系统会自动以每个事件的开始时间为零点重新对齐时间轴
- 对比观察各事件前后关键指标的变化模式
注意事项:对齐分析要求事件类型相同且具有可比性。不同故障类型的事件对齐可能会导致错误结论。
3.3 交互高亮的实现原理
当鼠标悬停在事件区域时,系统执行的高亮逻辑包括:
- 前端触发hover事件,获取事件ID
- 向后端查询该事件关联的指标列表
- 在前端将关联指标曲线加粗显示(通常使用亮色)
- 非关联指标透明度降低到30%-50%
- 其他事件标记变为灰色
这种设计有效解决了"信息过载"问题,在包含数十条曲线的复杂视图中尤其有用。
4. 事件管理的高级功能
4.1 事件列表的工程应用
事件列表弹窗不仅是一个查看工具,更是事件筛选的操作入口。在实际运维中,我常用以下工作流:
- 通过时间范围筛选过滤出关注时段的事件
- 按事件类型排序(如先看所有报警类事件)
- 勾选2-3个疑似相关事件进行对比分析
- 临时隐藏干扰事件(如计划性维护事件)
javascript复制// 类似前端的事件筛选逻辑
filteredEvents = allEvents.filter(event =>
event.startTime >= startFilter &&
event.endTime <= endFilter &&
selectedTypes.includes(event.type)
);
4.2 事件持久化存储策略
当点击"保存为面板"时,系统实际上执行了以下操作:
- 将当前视图配置(包含所有已选指标和事件)序列化为JSON
- 将该JSON存储在TDengine的元数据表中
- 建立与所选设备节点的关联关系
- 生成一个唯一的URL供后续直接访问
保存位置的选择策略:
- 如果分析针对单个设备,建议保存在该设备节点下
- 如果是产线级分析,应保存在更高层级的车间节点
- 跨设备类型的分析建议保存在工厂根节点
5. TDengine IDMP的架构优势
5.1 时序数据处理优化
TDengine作为专为物联网设计的时序数据库,在事件趋势图中展现出三大优势:
- 高效压缩:对工业设备数据的压缩比通常可达10:1以上
- 快速查询:利用时间分区和标签索引,毫秒级响应历史数据查询
- 原生聚合:内置滑动窗口计算,直接支持5秒/1分钟等颗粒度的降采样查询
5.2 工业数据建模特色
IDMP平台的树状层次结构完美匹配工业现场的设备拓扑:
code复制工厂(根节点)
├── 生产车间A
│ ├── 产线1
│ │ ├── 设备01
│ │ └── 设备02
│ └── 产线2
└── 生产车间B
这种结构使得事件趋势图可以自然地按照设备关系组织数据,运维人员可以快速定位到目标设备的历史数据。
6. 实战案例:水泵故障分析
最近在一个智慧水务项目中,我们使用事件趋势图成功分析出水泵轴承故障的早期特征:
- 首先筛选出过去3个月的所有"轴承温度报警"事件
- 添加相关指标:电机电流、进出口压力、振动幅度
- 开启时间对齐功能,发现故障前30分钟都会出现:
- 振动幅度缓慢上升(约增加15%)
- 电流出现微小波动(±2%)
- 基于此特征优化了预警规则,将故障预警提前了40分钟
这个案例展示了事件趋势图在实际工程中的诊断价值——它不仅呈现数据,更揭示了数据背后的设备状态演变规律。
7. 性能优化建议
在处理大规模设备数据时,建议采用以下优化策略:
-
查询优化:
- 对长时间范围查询优先使用降采样数据
- 设置合理的查询时间分区(如按天分区)
-
显示优化:
- 超过1万数据点时启用曲线简化算法
- 对次要指标默认显示聚合统计值(avg/max/min)
-
缓存策略:
- 对常用设备数据配置内存缓存
- 实现增量查询避免全量加载
sql复制-- 优化的趋势图查询示例
SELECT
WINDOW_START(ts) as interval_start,
AVG(temperature) as avg_temp,
MAX(vibration) as max_vib
FROM device_metrics
WHERE device_id = 'pump_01'
AND ts >= '2023-11-01'
AND ts < '2023-11-02'
INTERVAL(5m)
8. 扩展应用场景
除故障诊断外,事件趋势图还可应用于:
-
生产质量分析:
- 将产品质量检测事件与工艺参数关联
- 找出影响成品率的关键参数区间
-
能效优化:
- 对比不同班次的能耗曲线
- 识别设备空转等低效运行时段
-
预测性维护:
- 建立正常工况的指标波动基线
- 检测偏离基线的异常模式
在实际项目中,我们经常将事件趋势图与TDengine的流计算功能结合使用,实现实时异常检测与历史模式分析的闭环。