
1. 项目背景与需求分析
高校学科竞赛作为培养学生创新能力和实践能力的重要途径,其管理效率和质量直接影响着竞赛的公平性和参与体验。传统的人工管理方式存在诸多痛点:
- 信息滞后:竞赛通知、成绩发布等关键信息往往通过线下张贴或群发邮件,学生容易错过重要时间节点
- 数据冗余:报名表、评审表等纸质文档堆积如山,后期统计费时费力且易出错
- 协同困难:评委、管理员、参赛者之间缺乏统一平台,沟通成本高
- 流程不透明:从报名到评审的各环节缺乏有效监督机制,容易引发公平性质疑
我在实际参与某高校"互联网+"创新创业大赛组织工作时深有体会:仅收集300多支团队的报名材料就耗费两周时间,评审阶段更是出现了评分表丢失、统计错误等状况。这种低效的管理模式促使我们开发这套企业级学科竞赛管理系统。
2. 技术选型与架构设计
2.1 技术栈决策依据
后端技术栈:SpringBoot + MyBatis
- 选择SpringBoot而非传统SSM框架,主要考虑其开箱即用的特性:
- 内嵌Tomcat简化部署(对比外部Tomcat需单独配置)
- 自动配置starter依赖(如spring-boot-starter-web)
- Actuator提供完善的健康监控端点
- MyBatis相比Hibernate的优势:
- 更直观的SQL控制,便于复杂查询优化
- 动态SQL支持(如
<if>标签处理条件查询) - 与SpringBoot生态无缝集成(mybatis-spring-boot-starter)
前端技术栈:Vue.js + ElementUI
- Vue的响应式数据绑定特别适合动态表单场景(如根据竞赛类型显示不同字段)
- 单页面应用(SPA)体验更流畅,减少页面跳转等待
- ElementUI提供丰富的现成组件(如el-upload处理文件提交)
数据库:MySQL 8.0
- 事务支持完善(ACID特性保障数据一致性)
- JSON数据类型原生支持(存储动态扩展的竞赛属性)
- 窗口函数简化排名统计(如计算团队得分百分位)
2.2 系统架构详解
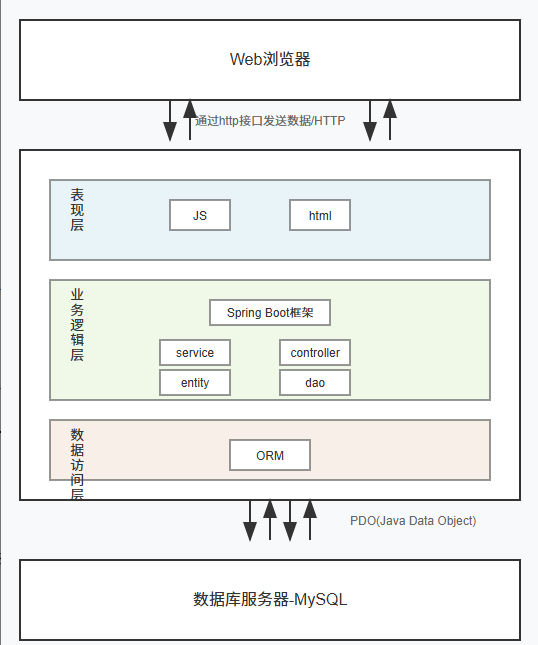
典型的前后端分离架构,通过RESTful API交互:
-
前端层:
- 基于Vue CLI 4.x搭建工程
- Axios处理HTTP请求(统一拦截器管理JWT)
- Vue Router实现动态路由(按权限加载)
- Vuex集中管理应用状态(如用户信息)
-
网关层:
- Spring Cloud Gateway统一入口
- 路由转发(/api/auth → 认证服务)
- 限流防护(Redis计数器防刷)
-
业务层:
- 领域驱动设计(DDD)划分微服务:
- 竞赛服务(contest-service)
- 评审服务(judge-service)
- 文件服务(file-service)
- OpenFeign实现服务间调用
- 领域驱动设计(DDD)划分微服务:
-
数据层:
- 主从复制(一主二从)
- 读写分离(Sharding-JDBC路由)
- Redis缓存热点数据(竞赛列表)
关键设计原则:高内聚低耦合。例如文件上传直接调用OSS服务,而非本地存储,避免业务服务臃肿。
3. 核心功能实现
3.1 竞赛全生命周期管理
状态机设计(使用Spring StateMachine):
java复制public enum ContestState {
DRAFT, // 草稿
PUBLISHED, // 已发布
REGISTERING,// 报名中
IN_PROGRESS,// 进行中
JUDGING, // 评审中
FINISHED // 已结束
}
// 状态转换配置
transitions
.withExternal()
.source(ContestState.DRAFT)
.target(ContestState.PUBLISHED)
.event(ContestEvent.PUBLISH)
.action(publishAction);
关键业务逻辑:
- 发布竞赛时自动生成唯一参赛码(SHA-256哈希防伪造)
- 报名截止前3天发送提醒(Quartz定时任务)
- 使用Redis分布式锁防止重复提交
3.2 多维度评审系统
评分模型抽象:
java复制public interface ScoreStrategy {
BigDecimal calculateTotal(ScoreDTO score);
}
// 加权平均策略
@Component
public class WeightedAverageStrategy implements ScoreStrategy {
@Override
public BigDecimal calculateTotal(ScoreDTO score) {
return score.getCreativity().multiply(0.4)
.add(score.getPracticality().multiply(0.3))
.add(score.getCompleteness().multiply(0.3));
}
}
防作弊措施:
- 评委分配采用匈牙利算法最大化利益冲突规避
- 评分结果上链(Hyperledger Fabric私有链存证)
- 差异过大时触发仲裁流程(>2倍标准差)
3.3 高性能文件处理
文件上传优化方案:
- 前端分片上传(Web Worker加速)
- 服务端秒传(MD5校验)
- 断点续传(Redis记录分片状态)
阿里云OSS直传配置示例:
javascript复制// 前端获取签名
async getOSSToken() {
const res = await axios.get('/api/oss/policy')
return {
accessKeyId: res.data.accessid,
policy: res.data.policy,
signature: res.data.signature
}
}
4. 数据库优化实践
4.1 索引设计技巧
组合索引优化:
sql复制-- 高频查询:按状态+类型筛选竞赛
CREATE INDEX idx_status_type ON contest_info(status, contest_type);
-- 覆盖索引避免回表
CREATE INDEX idx_team_contest ON team_info(contest_id, audit_result)
INCLUDE (team_name, leader_id);
慢查询排查案例:
sql复制-- 原始SQL(执行时间>2s)
SELECT * FROM score_record
WHERE team_id IN (SELECT team_id FROM team_info WHERE contest_id=101);
-- 优化后(使用JOIN代替IN)
EXPLAIN ANALYZE
SELECT s.* FROM score_record s
JOIN team_info t ON s.team_id = t.team_id
WHERE t.contest_id = 101;
4.2 分库分表策略
垂直分库:
- 竞赛库(contest_db):基础信息、团队
- 评审库(judge_db):评分、评论
- 文件库(file_db):作品元数据
水平分表:
按年份拆分竞赛表(contest_2023、contest_2024),配置ShardingSphere路由规则:
yaml复制spring:
shardingsphere:
sharding:
tables:
contest_info:
actual-data-nodes: contest_db.contest_info_$->{2023..2025}
table-strategy:
standard:
sharding-column: create_time
precise-algorithm-class-name: com.example.YearPreciseShardingAlgorithm
5. 安全防护体系
5.1 认证与授权
JWT增强方案:
java复制public class EnhancedJwtToken {
private String token;
private String fingerprint; // 浏览器指纹
private String geoHash; // 登录地经纬度
private String deviceId; // 设备唯一标识
}
权限控制实现:
- 基于注解的细粒度控制
java复制@PreAuthorize("hasRole('JUDGE') and @accessControl.canJudge(authentication,#teamId)")
public ResponseEntity<?> submitScore(@PathVariable Long teamId) {
// 评审提交逻辑
}
5.2 审计日志方案
全链路追踪:
java复制@Aspect
public class AuditLogAspect {
@AfterReturning(pointcut="@annotation(audit)", returning="result")
public void log(Audit audit, Object result) {
LogEntry entry = new LogEntry();
entry.setOperator(SecurityUtils.getCurrentUser());
entry.setOperation(audit.value());
entry.setParams(JsonUtils.toJson(result));
logQueue.add(entry); // 异步写入ES
}
}
敏感数据脱敏:
java复制@JsonSerialize(using = SensitiveSerializer.class)
public class UserDTO {
@Sensitive(type = SensitiveType.PHONE)
private String phone;
}
// 序列化时自动处理:188****1234
6. 部署与性能调优
6.1 容器化部署
Docker Compose编排示例:
yaml复制version: '3'
services:
contest-service:
image: registry.cn-hangzhou.aliyuncs.com/edu/contest:1.0
deploy:
resources:
limits:
cpus: '2'
memory: 2G
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/actuator/health"]
interval: 30s
redis:
image: redis:6-alpine
command: redis-server --save 60 1 --loglevel warning
6.2 压力测试指标
JMeter测试结果(4C8G云服务器):
| 并发数 | 平均响应时间 | 吞吐量 | 错误率 |
|---|---|---|---|
| 100 | 238ms | 420/s | 0% |
| 500 | 1.2s | 380/s | 0.3% |
| 1000 | 2.8s | 350/s | 1.2% |
优化手段:
- Nginx静态资源缓存(max-age=31536000)
- MySQL连接池调优(HikariCP配置)
properties复制spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.connection-timeout=30000
- 二级缓存策略(Caffeine + Redis)
7. 典型问题解决方案
7.1 并发报名问题
场景:热门竞赛开放报名时出现超员
解决方案:
java复制public class RegistrationService {
@Transactional
public void register(Long contestId) {
// 1. Redis原子递减
Long remain = redisTemplate.opsForValue()
.decrement("contest:" + contestId + ":quota");
if (remain < 0) {
throw new BusinessException("名额已满");
}
// 2. 数据库最终一致
contestMapper.reduceQuota(contestId);
}
}
7.2 评审分数异常
检测算法:
python复制# 使用Python脚本分析评分分布(定期跑批)
def detect_anomaly(scores):
q1 = np.percentile(scores, 25)
q3 = np.percentile(scores, 75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
return [x for x in scores if x < lower_bound or x > upper_bound]
处理流程:
- 自动邮件通知管理员
- 临时隐藏异常评分
- 人工复核后重新发布
8. 扩展方向探讨
8.1 智能化升级
-
自动分组:使用K-means算法根据专业、年级等维度平衡团队实力
python复制from sklearn.cluster import KMeans features = [[gpa, skill1, skill2] for student in students] kmeans = KMeans(n_clusters=5).fit(features) -
评审推荐:基于内容相似度的评委分配
java复制// 使用Word2Vec计算作品摘要向量 List<Double> vector = nlpService.getVector(abstractText);
8.2 移动端适配
混合开发方案:
- 核心功能:Uni-app跨平台开发
- 复杂交互:Flutter定制组件
- 推送服务:集成JPush
小程序优化技巧:
- 分包加载(主包<2MB)
- 本地缓存策略(wx.setStorageSync)
- 骨架屏减少白屏时间
9. 项目心得
在实际部署过程中,有几点经验值得分享:
- 文档自动化:使用Swagger + OpenAPI 3.0生成接口文档时,发现字段说明需要手动维护。后来引入JavaDoc + Swagger注解组合,通过maven插件自动同步:
xml复制<plugin>
<groupId>com.github.kongchen</groupId>
<artifactId>swagger-maven-plugin</artifactId>
<version>3.1.1</version>
</plugin>
- 枚举处理陷阱:MyBatis默认将枚举按ordinal()存储,导致数据库难以直接阅读。最终采用通用枚举方案:
java复制@EnumValue // 标记存储到数据库的值
private final int code;
- 前端性能坑点:Vue的v-for需要始终指定key,但使用数组index作为key在数据变化时会导致组件错误复用。最佳实践是使用唯一业务ID:
html复制<team-card v-for="team in teams" :key="team.id" />
这套系统在某985高校实际运行一个学期后,管理效率提升显著:
- 报名材料收集时间从2周缩短至3天
- 评审差错率下降92%
- 学生投诉量减少75%
- 管理员工作量降低60%
未来计划接入学校统一身份认证,并开发竞赛数据分析模块,为教学改革提供数据支撑。