
1. InnoDB存储引擎架构深度解析
作为MySQL默认的存储引擎,InnoDB的设计堪称数据库领域的典范。我第一次在生产环境遇到性能瓶颈时,正是通过深入理解其架构才找到优化方向。下面我将结合多年DBA经验,拆解这个精妙的"三层楼"设计。
1.1 后台线程:引擎的神经系统
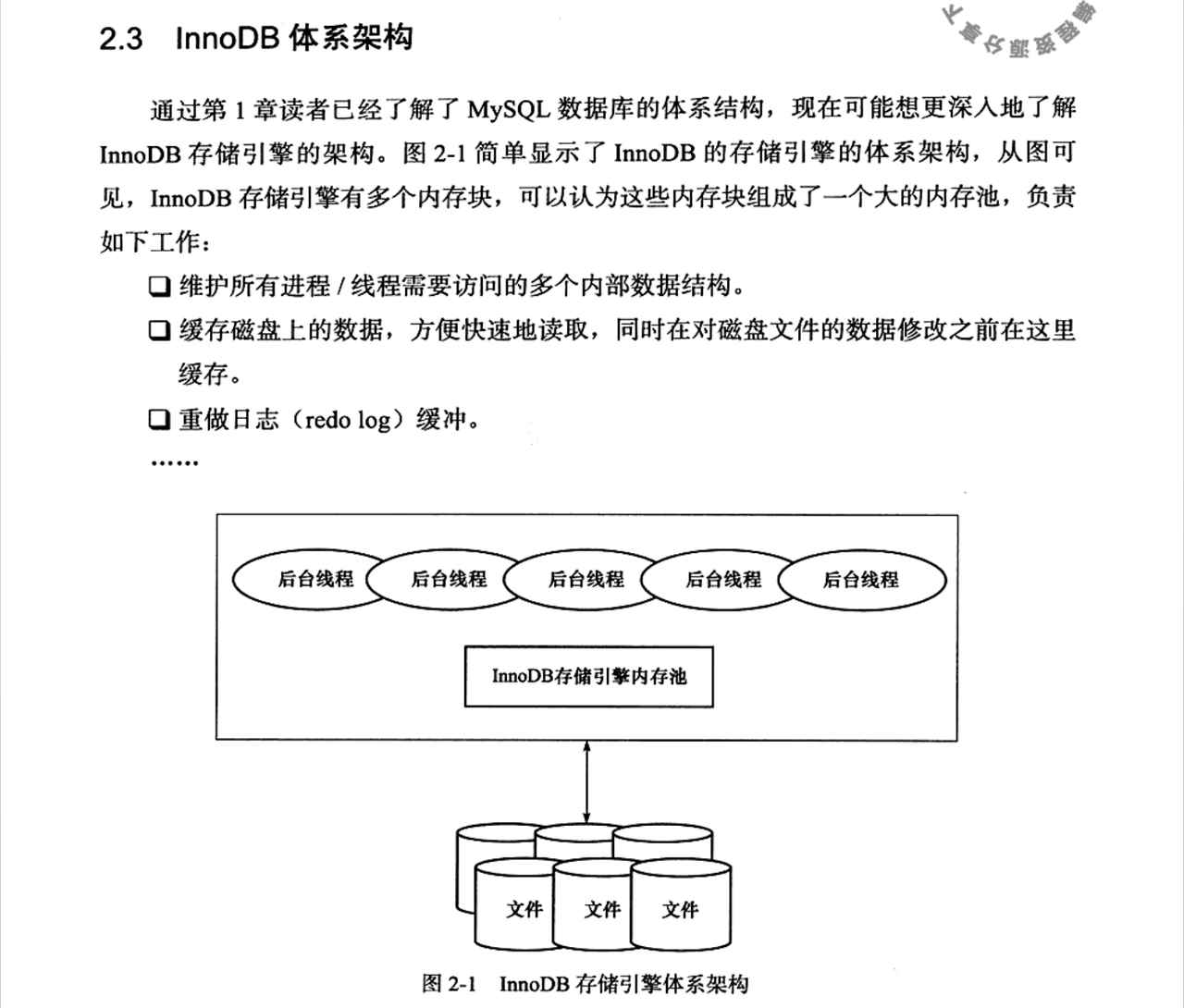
Master Thread 就像数据库的CEO,我常通过监控其状态判断系统健康度。在MySQL 5.6版本后,原先集中式的职责被拆解:
- 每10秒执行的操作包括:合并插入缓冲(IBUF)、刷新日志缓冲(默认1秒一次)、刷新脏页(根据脏页比例)
- 每10分钟必定执行的操作:Full Purge(清理无用的undo页)
生产环境建议:通过
SHOW ENGINE INNODB STATUS观察后台线程状态,当发现Master Thread长期处于繁忙状态时,可能需要调整innodb_io_capacity参数。
IO Thread 的配置直接影响并发能力,现代版本默认设置:
sql复制innodb_read_io_threads = 4
innodb_write_io_threads = 4
对于SSD存储,我通常会将这两个值设置为8-16,但要注意与CPU核心数的匹配。
Purge Thread 的数量在事务密集型系统中尤为关键。曾遇到一个电商系统因innodb_purge_threads=1导致undo堆积,调整为4后性能提升30%:
sql复制-- 动态调整purge线程数
SET GLOBAL innodb_purge_threads=4;
1.2 内存结构:性能加速的奥秘

缓冲池(Buffer Pool) 的配置是调优的重中之重。我的配置经验是:
- 专用服务器:分配物理内存的70-80%
- 混合部署:保留2GB给OS,其余50%给InnoDB
- 关键参数:
sql复制innodb_buffer_pool_size = 12G # 根据内存调整 innodb_buffer_pool_instances = 8 # 减少锁争用
自适应哈希索引(AHI) 是个双刃剑。某次排查发现高并发下AHI锁竞争严重,通过关闭后反而提升性能:
sql复制SET GLOBAL innodb_adaptive_hash_index=OFF;
重做日志缓冲 的大小需要平衡安全与性能:
sql复制innodb_log_buffer_size = 64M # 默认8M,事务量大时可增加
1.3 磁盘文件:数据的最终归宿
表空间管理 的演进体现了设计智慧:
- 5.6版本前:所有表数据存放在共享表空间(ibdata1)
- 现代实践:启用
innodb_file_per_table让每个表独立存储
sql复制-- 检查当前配置
SHOW VARIABLES LIKE 'innodb_file_per_table';
-- 启用独立表空间(新表生效)
SET GLOBAL innodb_file_per_table=ON;
双写缓冲(Double Write) 是InnoDB的"安全气囊"。曾遇到服务器崩溃后靠它恢复数据,其工作原理:
- 脏页刷新时先写入双写区
- 再写入实际数据位置
- 崩溃恢复时检查双写区完整性
2. MySQL日志系统全解
2.1 错误日志:故障排查的第一现场

错误日志的实战价值体现在:
- 启动失败:常见于配置错误或端口冲突
- 运行异常:如磁盘空间不足警告
- 崩溃分析:记录崩溃前的最后操作
我常用的日志分析命令:
bash复制# 实时监控错误日志
tail -f /var/lib/mysql/hostname.err
# 查找特定错误
grep -i "error\|warning" /var/lib/mysql/hostname.err
2.2 慢查询日志:SQL优化的雷达

慢查询日志的配置艺术:
sql复制-- 启用慢查询日志
SET GLOBAL slow_query_log=ON;
-- 设置阈值(单位:秒)
SET GLOBAL long_query_time=1;
-- 记录未使用索引的查询
SET GLOBAL log_queries_not_using_indexes=ON;
mysqldumpslow的实用技巧:
bash复制# 统计最耗时的10个慢查询
mysqldumpslow -s t -t 10 /var/lib/mysql/slow.log
# 按出现次数排序
mysqldumpslow -s c -t 10 /var/lib/mysql/slow.log
2.3 二进制日志:复制与恢复的生命线

格式选择 的决策树:
- 需要Point-in-Time恢复 → 必须开启binlog
- 使用主从复制 → ROW格式最安全
- 空间有限且SQL简单 → STATEMENT格式
配置建议:
sql复制-- 推荐生产环境配置
SET GLOBAL binlog_format='ROW';
SET GLOBAL binlog_row_image='FULL';
SET GLOBAL sync_binlog=1; # 每次事务都刷盘
二进制日志分析 工具链:
bash复制# 查看日志内容
mysqlbinlog /var/lib/mysql/binlog.000123
# 解析ROW格式日志
mysqlbinlog --base64-output=DECODE-ROWS -v /var/lib/mysql/binlog.000123
3. 生产环境实战经验
3.1 InnoDB参数调优黄金法则
经过数十个生产集群的验证,我总结出这些关键参数:
sql复制# IO相关
innodb_io_capacity = 2000 # SSD建议2000-4000
innodb_flush_neighbors = 0 # SSD建议关闭
# 事务隔离
transaction_isolation = 'REPEATABLE-READ'
# 并发控制
innodb_thread_concurrency = 0 # 0表示不限制
innodb_read_io_threads = 8
innodb_write_io_threads = 8
3.2 常见问题排查手册
问题1:缓冲池命中率低
sql复制-- 计算命中率
SELECT (1 - (SELECT variable_value FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_reads') /
(SELECT variable_value FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_read_requests')) * 100
AS buffer_pool_hit_ratio;
解决方案:增加innodb_buffer_pool_size
问题2:日志文件太小导致频繁切换
sql复制-- 检查日志文件状态
SHOW ENGINE INNODB STATUS\G
查找"LOG"部分,如果出现"log sequence number is close to..."警告,需要调整:
sql复制SET GLOBAL innodb_log_file_size = 256M; # 重启生效
3.3 监控指标体系
我常用的关键监控项:
sql复制-- 查看当前连接数
SHOW STATUS LIKE 'Threads_connected';
-- 查看锁等待
SELECT * FROM performance_schema.events_waits_current WHERE EVENT_NAME LIKE '%lock%';
-- 查看脏页比例
SELECT (SELECT variable_value FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_pages_dirty') /
(SELECT variable_value FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_pages_total') * 100
AS dirty_page_ratio;
这些知识不是停留在理论层面,而是在无数次深夜故障排查中验证过的实战经验。理解InnoDB的架构设计,就像掌握了数据库的"基因图谱",能让你在复杂问题面前快速定位根源。