
1. JMeter逻辑控制器概述
在性能测试领域,JMeter作为一款开源的负载测试工具,其逻辑控制器(Logic Controller)功能是构建复杂测试场景的核心组件。逻辑控制器能够改变测试脚本的默认执行顺序,实现条件分支、循环迭代等编程逻辑,使测试脚本具备更强的灵活性和场景适配能力。
提示:逻辑控制器必须与取样器(Sampler)配合使用,单独添加控制器而不包含任何取样器将不会产生实际测试行为。
1.1 逻辑控制器核心价值
逻辑控制器主要解决以下三类测试需求:
- 流程控制:通过条件判断决定是否执行特定测试步骤(如If控制器)
- 重复执行:精确控制部分请求的循环次数(如循环控制器)
- 数据驱动:遍历数据集执行参数化测试(如ForEach控制器)
在JMeter的线程组结构中,逻辑控制器位于线程组与取样器之间,形成"线程组 → 逻辑控制器 → 取样器"的三层架构。这种设计使得我们可以针对不同测试需求灵活组合各类控制器。
1.2 控制器类型速查表
| 控制器类型 | 主要功能 | 典型应用场景 |
|---|---|---|
| If控制器 | 条件判断执行分支 | 根据变量值选择不同测试路径 |
| 循环控制器 | 固定次数循环执行 | 压力测试中的重复请求 |
| 事务控制器 | 将多个请求合并为业务事务 | 完整业务流程的性能测试 |
| ForEach控制器 | 遍历变量集合执行 | 参数化测试、搜索关键词遍历 |
| 仅一次控制器 | 整个测试中只执行一次 | 登录等前置操作 |
| 随机控制器 | 随机选择子节点执行 | A/B测试场景 |
| 交替控制器 | 轮流执行子节点 | 混合业务场景测试 |
2. If控制器深度解析
If控制器是JMeter中实现条件测试的关键组件,其工作原理类似于编程语言中的if语句。通过判断条件表达式的结果(true/false),决定是否执行控制器下的子元素。
2.1 配置参数详解
在If控制器的配置界面中,有几个关键参数需要特别注意:
-
条件表达式:支持JavaScript和Groovy语法
- 直接条件:
${变量} == "值" - 函数条件:
${__jexl3(${VAR} >= 10)}
- 直接条件:
-
评估所有子节点:当勾选时,会先计算所有子元素的表达式
-
使用表达式语言:建议勾选以支持更灵活的条件判断
注意:JMeter 5.4.1版本后,默认使用__jexl3函数进行条件判断,比传统的JavaScript引擎性能更高。
2.2 电商场景实战案例
假设我们需要测试电商平台的搜索功能,根据用户类型显示不同的搜索结果:
java复制// 用户类型变量定义
userType = "vip" // 可能取值:vip/normal
// 测试逻辑
if(userType == "vip") {
showVipResults();
} else {
showNormalResults();
}
JMeter实现步骤:
- 添加「用户定义的变量」组件,设置userType=vip
- 添加If控制器,条件设置为:
"${userType}" == "vip"- 添加HTTP请求:VIP商品搜索接口
- 添加另一个If控制器,条件设置为:
"${userType}" != "vip"- 添加HTTP请求:普通商品搜索接口
- 添加查看结果树验证
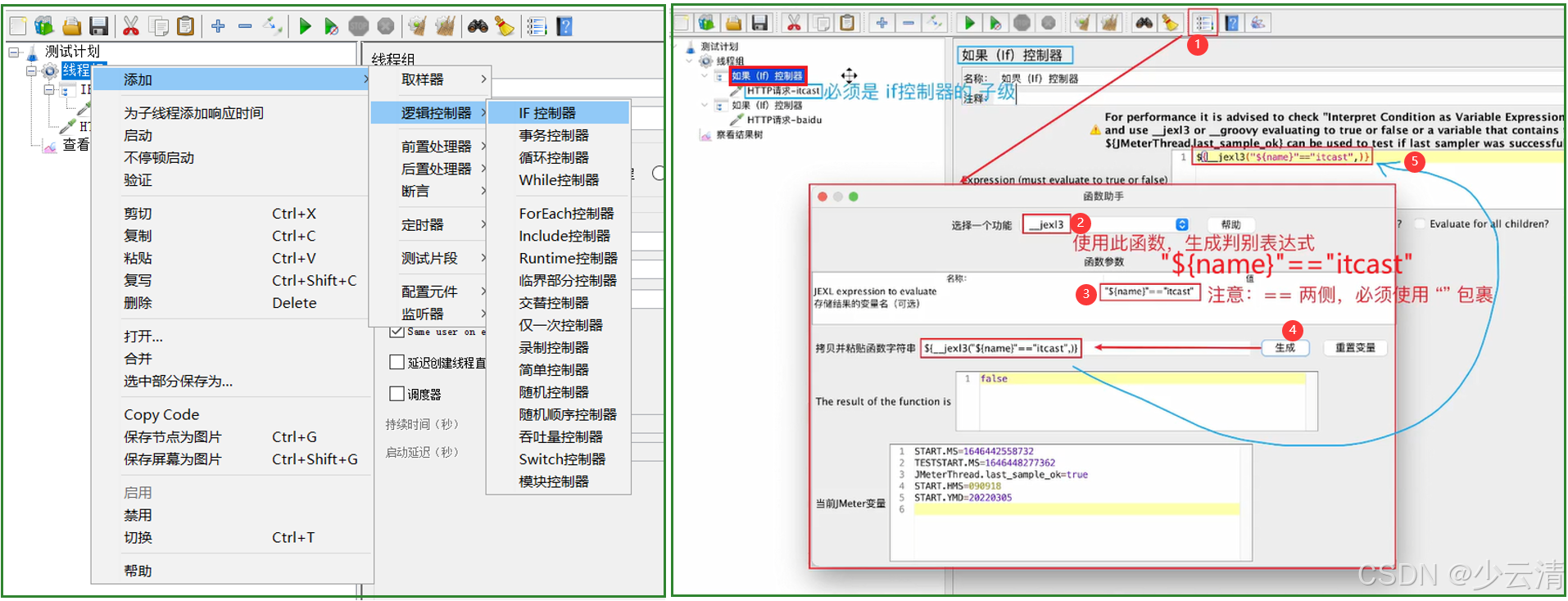
2.3 避坑指南
-
字符串比较问题:JMeter变量比较时,建议将变量用引号包裹
- 正确:
"${name}" == "baidu" - 错误:
${name} == "baidu"
- 正确:
-
条件表达式性能:复杂判断建议使用__jexl3而非JavaScript
- 推荐:
${__jexl3(${count} > 5 && ${status} == "success")}
- 推荐:
-
变量未定义处理:当引用的变量可能不存在时,应设置默认值
- 安全写法:
"${name:-default}" == "baidu"
- 安全写法:
3. 循环控制器高级应用
循环控制器提供精确的循环执行控制,与线程组的循环次数设置形成互补关系。理解两者的区别是掌握JMeter循环控制的关键。
3.1 循环机制对比分析
| 特性 | 线程组循环 | 循环控制器 |
|---|---|---|
| 作用范围 | 线程组内所有请求 | 控制器下子元素 |
| 执行顺序 | 全局最后处理 | 优先于线程组循环 |
| 嵌套影响 | 不可嵌套 | 可多层嵌套 |
| 典型应用 | 简单重复测试 | 复杂循环场景 |
循环次数计算公式:
code复制实际循环次数 = 线程组循环次数 × 循环控制器次数
3.2 性能测试实战案例
需求:测试系统在持续负载下的稳定性,要求:
- 模拟20个并发用户
- 每个用户先执行登录(仅1次)
- 然后循环执行搜索操作30次
- 整个场景重复执行10遍
JMeter实现方案:
-
线程组设置:
- 线程数:20
- 循环次数:10
-
添加「仅一次控制器」:
- 包含登录请求
-
添加「循环控制器」(循环次数=30):
- 包含搜索请求
-
添加监听器:
- 聚合报告
- 响应时间图
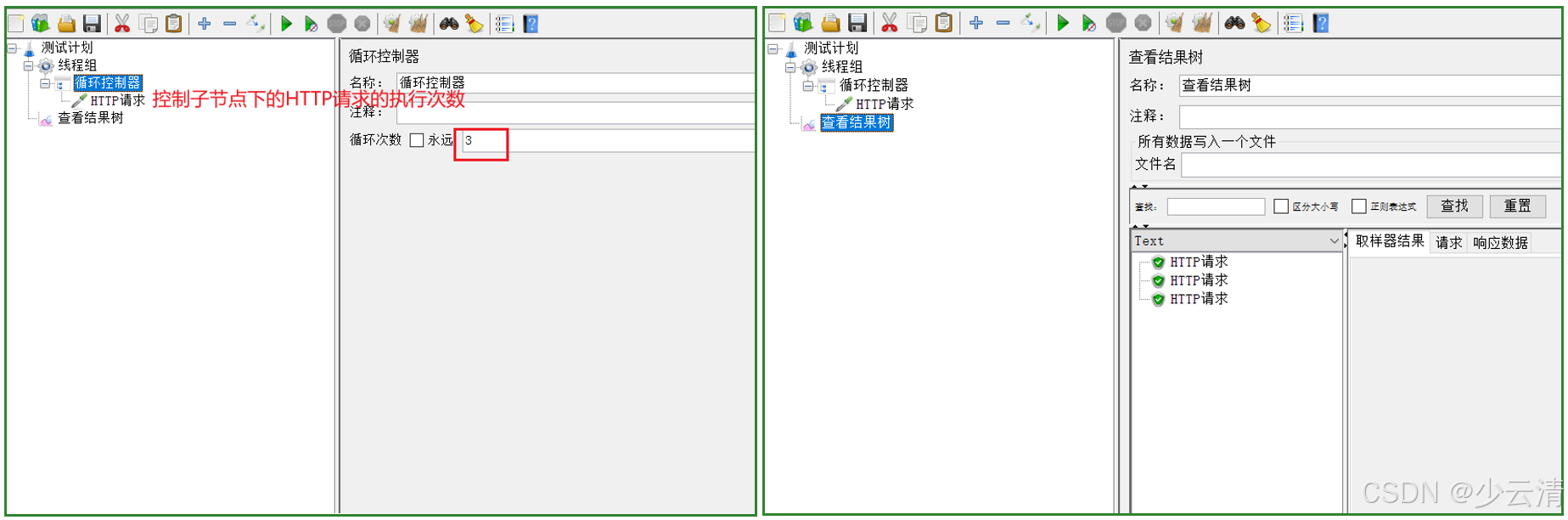
3.3 高级技巧
-
动态循环次数:通过变量控制循环次数
- 设置:循环次数
${loopCount} - 前置配置:使用「用户定义的变量」或「CSV数据文件设置」
- 设置:循环次数
-
嵌套循环应用:实现多维测试场景
python复制for i in range(5): # 外层循环控制器 for j in range(3): # 内层循环控制器 send_request() -
循环中断条件:结合If控制器实现break效果
- 添加「如果控制器」作为循环控制器的子元素
- 条件满足时使用「测试动作」采样器停止当前线程
4. 事务控制器专业用法
事务控制器将多个采样器合并为一个逻辑事务,在性能测试中用于模拟完整的业务操作流程。
4.1 事务类型详解
JMeter支持两种事务生成方式:
-
采样器事务:将子采样器的响应时间累加
- 适用场景:需要统计各步骤耗时的业务流程
- 配置方法:勾选"Generate parent sample"
-
独立事务:重新计算整个事务的响应时间
- 适用场景:需要真实端到端时间的业务流
- 配置方法:不勾选"Generate parent sample"
4.2 电商下单场景实现
典型电商下单流程包含:
- 登录 → 2. 添加购物车 → 3. 结算 → 4. 支付
JMeter配置步骤:
- 添加「事务控制器」(命名为"完整下单流程")
- 按顺序添加4个HTTP请求:
- POST /login
- POST /addToCart
- POST /checkout
- POST /payment
- 配置事务控制器:
- 勾选"Generate parent sample"
- 勾选"Include duration of timer and pre-post processors"
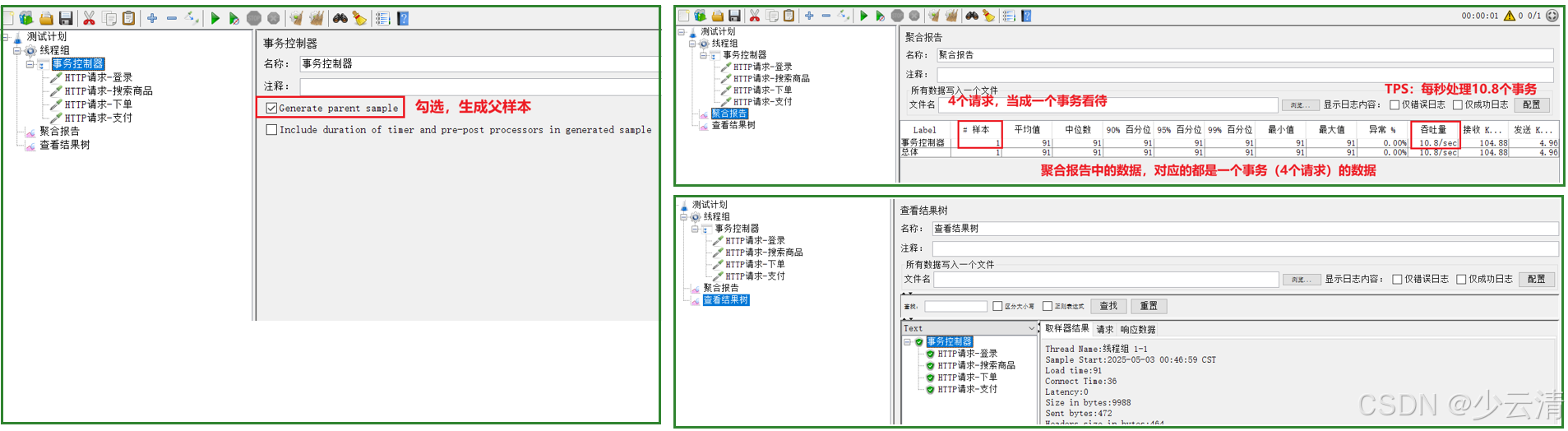
4.3 性能分析要点
- 事务成功率:在聚合报告中关注事务的Error%
- 响应时间分布:使用事务控制器后可以分析:
- 各子步骤耗时占比
- 端到端总耗时
- 吞吐量计算:事务级TPS比单个请求的TPS更具业务意义
经验分享:在实际压力测试中,建议对关键业务路径都添加事务控制器,这样生成的测试报告更能反映真实用户体验。
5. ForEach控制器与参数化测试
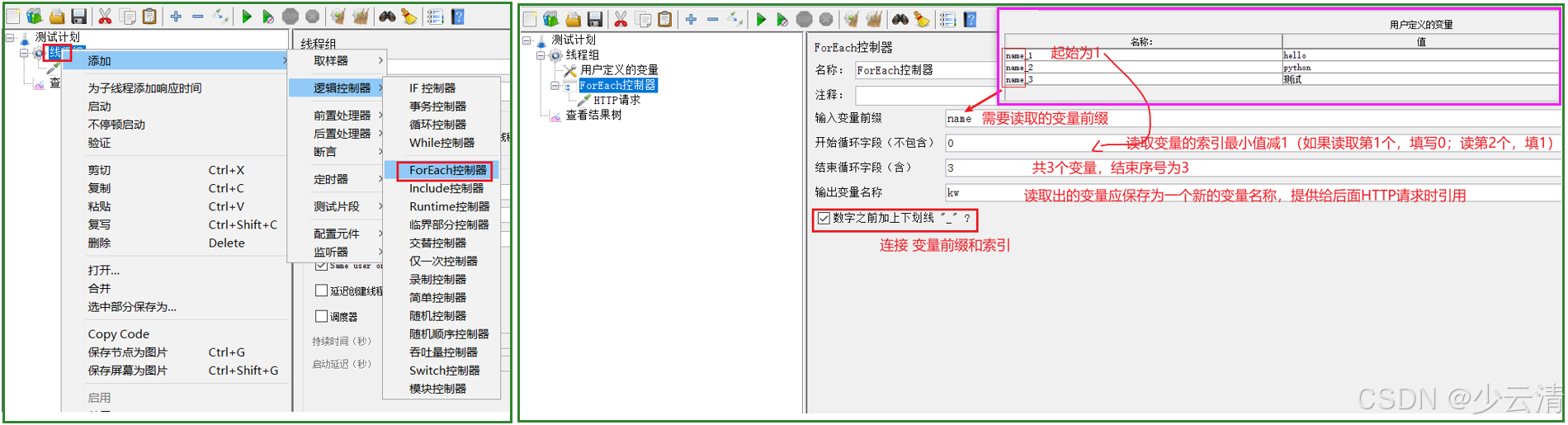
ForEach控制器是JMeter中实现数据驱动测试的核心组件,通常与变量提取器配合使用,实现动态参数遍历。
5.1 核心配置参数
| 参数名 | 说明 |
|---|---|
| 输入变量前缀 | 要遍历的变量名前缀(不包含数字后缀) |
| 输出变量名 | 每次循环时当前取值的变量名 |
| 开始/结束索引 | 控制遍历范围,默认为空表示遍历所有 |
| 添加"_"前缀 | 处理JMeter变量命名规范(建议勾选) |
5.2 多关键词搜索实战
需求:测试搜索引擎对不同关键词的响应性能
-
准备测试数据:
- 使用「用户定义的变量」:
code复制keyword_1 = 性能测试 keyword_2 = JMeter keyword_3 = 负载均衡
- 使用「用户定义的变量」:
-
配置ForEach控制器:
- 输入变量前缀:keyword
- 输出变量名:currentKeyword
- 勾选"Add '_' before number"
-
添加HTTP请求:
- 路径:/search?q=$
-
添加断言:
- 响应断言:验证结果包含$
5.3 正则表达式高级配合
当需要从响应中提取多个变量时,ForEach控制器与正则表达式提取器的组合尤为强大。
案例:测试新闻网站的热门话题搜索
-
添加HTTP请求获取新闻首页
-
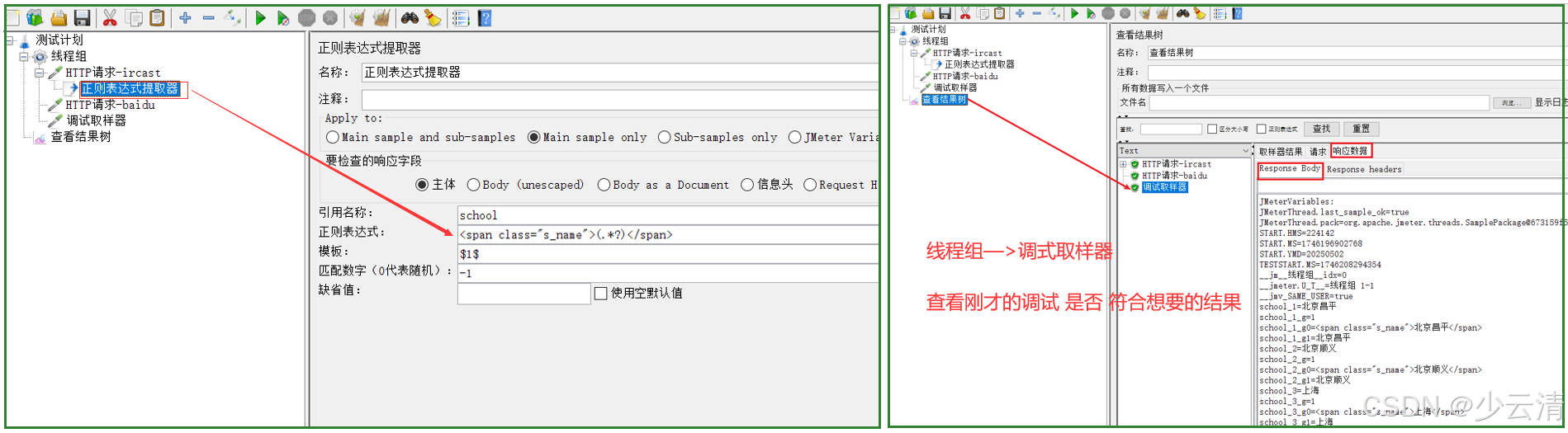
添加「正则表达式提取器」:
- 引用名称:topics
- 正则表达式:
<a class="topic">(.+?)</a> - 模板:$1$
- 匹配数字:-1(全部匹配)
-
添加ForEach控制器:
- 输入变量前缀:topics
- 输出变量名:currentTopic
-
添加搜索请求:
- 路径:/search?topic=$
5.4 性能优化建议
- 变量预加载:对于大型数据集,建议使用「CSV数据文件设置」而非用户变量
- 循环控制:合理设置开始/结束索引避免不必要的遍历
- 缓存管理:在长时间运行的测试中,注意定期清理缓存变量
6. 控制器组合实战技巧
在实际性能测试中,往往需要组合使用多种逻辑控制器来构建复杂场景。以下是几种典型组合模式:
6.1 条件循环模式
python复制if 用户登录成功:
for i in range(重试次数):
执行关键业务
if 业务成功:
break
JMeter实现:
- If控制器检查登录状态
- 嵌套循环控制器
- 内部If控制器检查业务状态
- 使用「测试动作」采样器实现break
6.2 数据驱动事务模式
python复制for 测试数据 in 数据集:
start_transaction()
步骤1(测试数据)
步骤2(测试数据)
end_transaction()
JMeter实现:
- ForEach控制器遍历数据
- 嵌套事务控制器
- 事务内包含多个参数化请求
6.3 多层控制结构
python复制for 用户类型 in 用户类型列表:
if 用户类型 == "VIP":
执行VIP流程
else:
执行普通流程
for i in range(操作次数):
执行公共操作
JMeter实现:
- 外层ForEach控制器遍历用户类型
- 内层If控制器分支
- 最内层循环控制器
7. 性能测试最佳实践
基于多年JMeter使用经验,分享几个关键实践建议:
-
控制器命名规范:
- 为每个控制器设置具有业务意义的名称
- 例如:"用户登录-仅一次"、"商品搜索-循环10次"
-
执行顺序控制:
- 利用「模块控制器」管理复杂的控制流
- 使用「测试片段」实现脚本模块化
-
调试技巧:
- 在调试阶段使用「调试采样器」输出变量值
- 配合「查看结果树」验证逻辑控制效果
-
资源监控:
- 大量循环时监控JMeter自身资源使用
- 建议单台负载机不超过300个线程
-
报告分析:
- 使用「事务控制器」生成有业务意义的指标
- 在「聚合报告」中重点关注事务级数据
在实际项目中,我曾遇到一个典型问题:当使用多层嵌套循环时,JMeter内存消耗会急剧上升。解决方案是:
- 优化测试数据量,避免不必要的迭代
- 增加JMeter启动内存:修改jmeter.bat中的HEAP参数
- 考虑分布式执行压力测试
逻辑控制器的合理使用可以大幅提升测试脚本的灵活性和场景覆盖率,但也要注意控制复杂度,避免创建难以维护的测试脚本结构。建议采用模块化设计思想,将复杂逻辑拆分为多个可复用的测试片段。