
1. C程序的内存空间布局解析
在Linux系统编程中,理解C程序的内存空间布局是基础中的基础。让我们先来看一张典型的内存布局图:
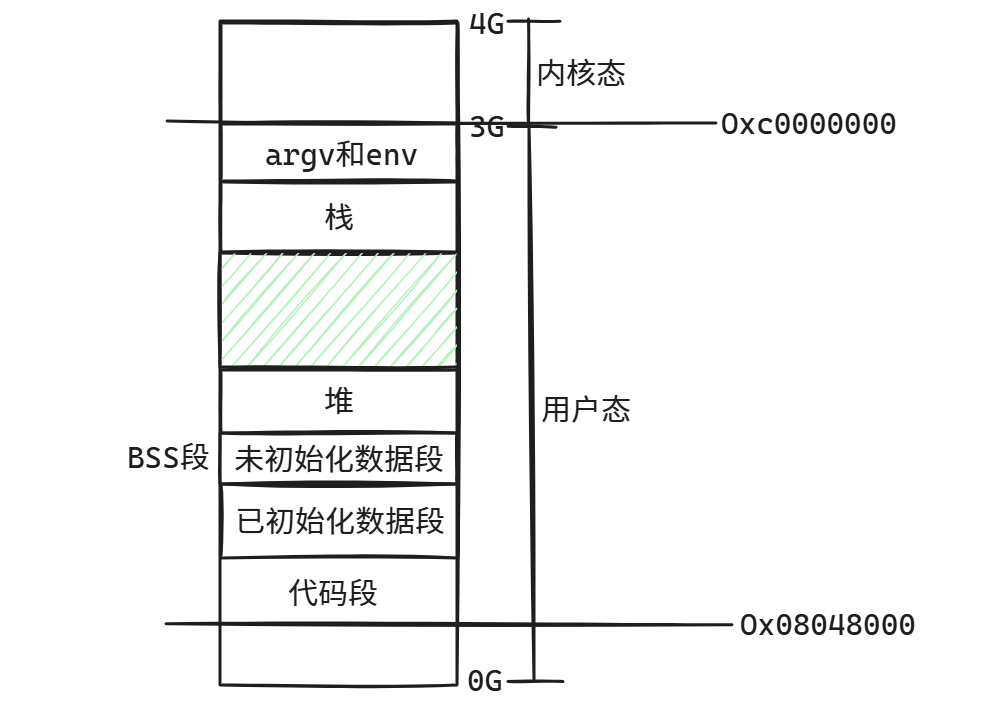
这个布局展示了32位Linux系统中进程的虚拟地址空间分配。从上到下分别是:
- 栈(Stack):向下增长,存储局部变量、函数参数和返回地址
- 堆(Heap):向上增长,用于动态内存分配(malloc/free)
- 未初始化数据段(BSS):存储未初始化的全局变量
- 已初始化数据段(Data):存储已初始化的全局变量和静态变量
- 代码段(Text):存储程序的可执行指令
注意:当堆和栈空间不足时,它们会分别向上和向下扩展,挤压中间的区域。这个中间区域通常用于存放共享库(静态库/动态库)的映射。
1.1 32位系统的4GB内存限制原理
32位系统的虚拟地址由32位二进制数组成,这意味着:
- 可寻址范围:0 ~ 2³²-1(即0x00000000到0xFFFFFFFF)
- 每个地址对应1字节,因此总容量为4GB(4,294,967,296字节)
这个限制源于CPU的地址总线宽度。32位CPU最多只能用32位来标记内存地址,所以虚拟地址空间的上限就是4GB,与实际物理内存大小无关。
1.2 用户态程序从0x08048000开始的奥秘
在Linux i386架构下,ELF可执行文件默认加载到0x08048000,主要原因有三:
-
低地址空间预留:
- 0x00000000~0x08047FFF区域被刻意保留
- NULL指针指向0x0,访问会触发段错误(方便调试)
- 用于加载动态链接器(ld-linux.so)等系统组件
-
历史兼容性与对齐要求:
- 0x08048000是4KB页对齐地址(0x1000 × 0x8048)
- 避免与动态链接器、库文件的加载区域冲突
-
虚拟地址空间划分:
- 经典3G/1G划分:
- 用户态:0x00000000~0xBFFFFFFF(3GB)
- 内核态:0xC0000000~0xFFFFFFFF(1GB)
- 经典3G/1G划分:
1.3 进程内存查看实战
我们可以使用以下命令查看进程内存分布:
bash复制# 查找进程ID
ps axf | grep 你的程序名
# 查看内存映射
pmap -x 进程ID
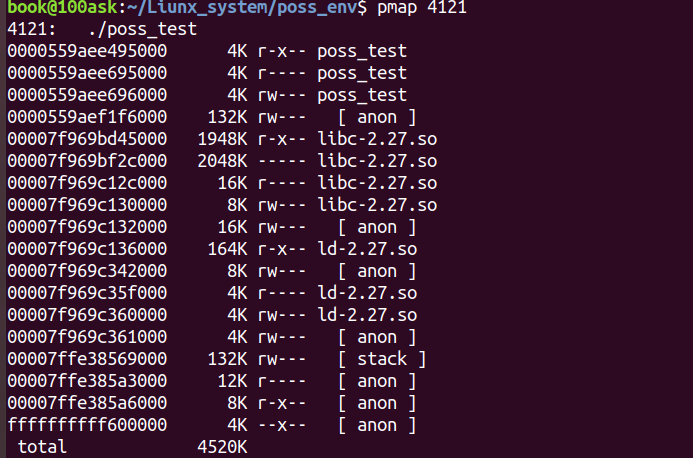
pmap输出显示了进程的完整内存布局,包括:
- 各段的起始地址和大小
- 权限标志(r/w/x)
- 映射的文件(如共享库)
2. 静态库深度解析与实现
2.1 静态库的本质
静态库(.a文件)实际上是多个.o目标文件的归档集合。它的核心特点是:
- 编译时链接:库代码被完整复制到可执行文件中
- 自包含:运行时不再依赖原库文件
- 体积大:每个使用静态库的程序都包含库代码副本
比喻:就像把菜谱和所有食材打包带走,在任何厨房都能做出这道菜。
2.2 静态库创建全流程
让我们通过一个加法库的示例演示静态库创建过程:
- 编写源代码:
c复制// add.c
#include "add.h"
int add(int a, int b) {
return a + b;
}
- 生成目标文件:
bash复制gcc -c add.c -o add.o
- 创建静态库:
bash复制ar rcs libadd.a add.o
r:替换已存在的成员c:创建库(如果不存在)s:创建索引
- 使用静态库:
bash复制gcc main.c -L. -ladd -o main
-L.:指定库搜索路径(当前目录)-ladd:链接libadd.a
2.3 静态库的优劣势分析
优势:
- 部署简单(单个可执行文件)
- 运行时不依赖外部环境
- 性能略高(无动态链接开销)
劣势:
- 可执行文件体积大
- 库更新需要重新编译程序
- 内存利用率低(相同库代码被多次加载)
3. 动态库深入剖析与实战
3.1 动态库的核心特性
动态库(.so文件)的关键特点是:
- 运行时加载:程序运行时才加载库代码
- 共享性:多个程序可共享同一库实例
- 体积小:可执行文件只包含引用
比喻:就像去餐厅点菜,厨房(动态库)准备好食材,多个顾客(程序)共享厨房资源。
3.2 -fPIC的重要性
位置无关代码(Position-Independent Code)是动态库的必备特性:
bash复制gcc -fPIC -c add.c -o add.o
- 使代码可以被加载到任意内存地址执行
- 通过相对地址而非绝对地址访问数据和函数
- 是实现库共享的基础
3.3 动态库创建完整流程
- 编译位置无关代码:
bash复制gcc -fPIC -c add.c -o add.o
- 创建动态库:
bash复制gcc -shared -o libadd.so add.o
- 配置系统查找路径:
bash复制sudo cp libadd.so /usr/local/lib
sudo ldconfig
或者修改/etc/ld.so.conf:
bash复制echo "/path/to/your/libs" | sudo tee -a /etc/ld.so.conf
sudo ldconfig
3.4 动态库的优劣势
优势:
- 节省磁盘和内存空间
- 库更新无需重新编译程序
- 支持运行时加载/卸载
劣势:
- 部署复杂(需确保库路径正确)
- 轻微性能开销(动态链接过程)
- 兼容性问题(不同版本库可能冲突)
4. 手工装载库高级技巧
4.1 手工装载原理
手工装载(运行时动态链接)提供了更灵活的控制:
c复制#include <dlfcn.h>
void* handle = dlopen("libadd.so", RTLD_LAZY);
if (!handle) {
fprintf(stderr, "%s\n", dlerror());
exit(1);
}
typedef int (*add_func)(int, int);
add_func add = (add_func)dlsym(handle, "add");
int result = add(3, 4);
dlclose(handle);
4.2 关键API详解
-
dlopen:
- 打开动态库文件
- 参数:库路径、标志(RTLD_LAZY/RTLD_NOW)
- 返回库句柄
-
dlsym:
- 查找符号(函数/变量)地址
- 参数:库句柄、符号名
- 返回符号地址
-
dlclose:
- 关闭动态库
- 参数:库句柄
- 返回:成功(0)或失败(-1)
-
dlerror:
- 获取最近一次错误信息
- 返回:错误描述字符串
4.3 手工装载的应用场景
- 插件系统:运行时加载功能模块
- 延迟加载:减少启动时间
- 条件加载:根据环境选择不同实现
- 热更新:不重启程序替换功能
5. 库的实战问题排查指南
5.1 常见问题及解决方案
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 找不到库 | 库路径未配置 | 设置LD_LIBRARY_PATH或更新/etc/ld.so.conf |
| 符号未定义 | 链接时缺少依赖库 | 检查-l参数顺序,确保依赖库在后 |
| 版本冲突 | 安装了多个版本库 | 使用ldd检查依赖,统一库版本 |
| 段错误 | ABI不兼容 | 确保所有组件使用相同编译器版本编译 |
5.2 实用调试命令
- 查看动态依赖:
bash复制ldd 你的程序
- 查看符号表:
bash复制nm -D libxxx.so
- 查看库版本:
bash复制objdump -p libxxx.so | grep SONAME
- 追踪库加载:
bash复制LD_DEBUG=libs 你的程序
5.3 性能优化建议
- 预加载常用库:
bash复制LD_PRELOAD=/path/to/libxxx.so 你的程序
- 使用RTLD_NOW:
c复制dlopen("libxxx.so", RTLD_NOW); // 立即解析所有符号
- 符号版本控制:
c复制__asm__(".symver oldfunc,func@VERS_1.1");
在实际项目中,我经常遇到库版本冲突问题。一个实用的技巧是使用LD_LIBRARY_PATH优先加载指定版本的库,而不是修改系统默认路径。这样可以避免影响其他应用程序。