
1. 为什么我们需要Kubernetes?
十年前,当我第一次尝试在生产环境部署微服务时,手动管理几十个Docker容器简直是场噩梦。凌晨三点被报警叫醒,因为某个容器崩溃了;流量突增时手忙脚乱地扩容;不同服务间的依赖关系像意大利面条一样纠缠不清...这正是Kubernetes(简称K8S)要解决的核心痛点。
K8S本质上是一个分布式操作系统,专门为管理容器化应用而设计。它把底层基础设施抽象成统一的资源池,让开发者只需声明"我想要什么",而不是操心"如何实现"。就像你不需要知道电梯的机械结构也能按按钮到达目标楼层一样。
2. K8S解决的具体问题清单
2.1 故障自愈:永不宕机的服务
传统运维中,当某个容器崩溃时,通常需要人工介入重启。在K8S集群中,控制器会持续监控Pod(容器组)状态。假设我们有一个运行Nginx的Pod:
yaml复制apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
如果这个Pod意外终止,ReplicaSet控制器会立即检测到实际状态与声明状态不符(比如声明需要1个运行实例但实际为0),自动创建新的Pod。这个过程完全自动化,响应时间在毫秒级。
经验提示:生产环境建议始终通过Deployment管理Pod,而不是直接创建裸Pod。Deployment提供了更完善的滚动更新和版本回滚机制。
2.2 智能调度:资源利用的艺术
K8S调度器(Scheduler)就像一位精明的管家,考虑以下因素决定Pod的最佳安置位置:
- 节点剩余资源(CPU/Memory)
- 亲和性规则(比如某些Pod需要部署在同一节点)
- 反亲和性规则(避免单点故障)
- 自定义策略(GPU需求、特定硬件等)
例如,通过节点选择器确保数据库Pod运行在SSD存储节点:
yaml复制spec:
nodeSelector:
disktype: ssd
2.3 弹性伸缩:应对流量洪峰
Horizontal Pod Autoscaler(HPA)可以根据CPU利用率或自定义指标自动调整Pod数量。假设我们有一个Web服务:
bash复制kubectl autoscale deployment web --cpu-percent=50 --min=2 --max=10
这条命令会确保:
- 始终保持至少2个Pod副本
- 当CPU平均利用率超过50%时自动扩容
- 最多不超过10个Pod
在618大促期间,某电商平台的订单服务通过HPA实现了从20个Pod到200个Pod的自动扩容,平稳支撑了10倍流量增长。
2.4 服务编排:复杂的依赖管理
通过Init Container机制,可以确保容器按正确顺序启动。比如一个Web应用需要等待数据库就绪:
yaml复制initContainers:
- name: wait-for-db
image: busybox
command: ['sh', '-c', 'until nc -z db 3306; do echo waiting for db; sleep 2; done;']
K8S会先运行initContainer,直到数据库端口可达才会启动主容器。类似地,Sidecar模式可以让辅助容器(如日志收集器)与主容器协同工作。
3. K8S架构深度解析
3.1 控制平面:集群的大脑
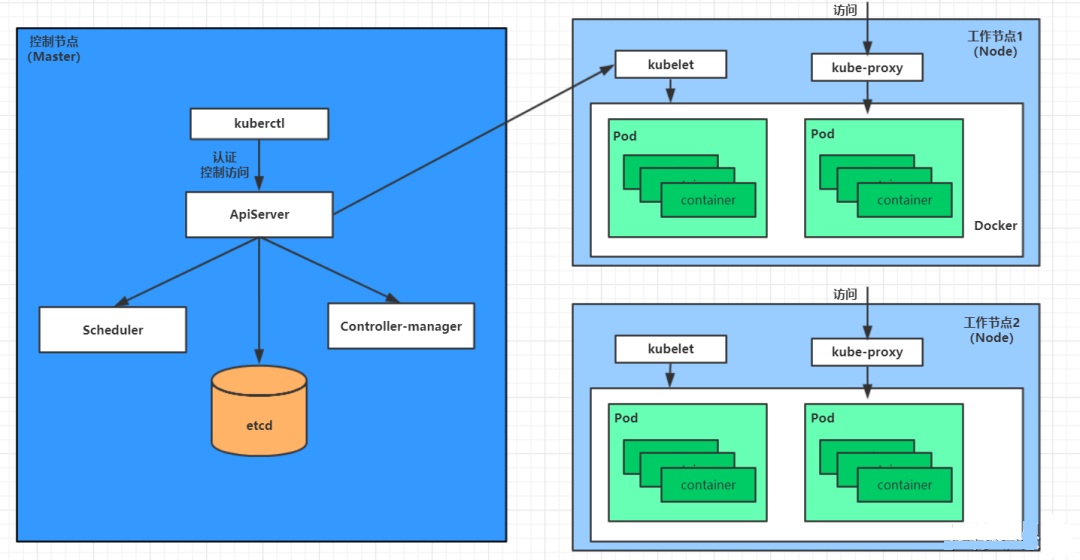
API Server 是所有请求的网关,采用声明式API设计。当你执行kubectl apply时:
- 请求首先经过认证(Authentication)
- 然后检查权限(Authorization)
- 最后通过准入控制(Admission Control)的层层校验
Controller Manager 包含多个控制器循环:
- Deployment控制器:确保有指定数量的Pod在运行
- Job控制器:管理一次性任务
- Namespace控制器:处理命名空间生命周期
Etcd 作为分布式键值存储,保存了整个集群的状态。生产环境建议:
- 使用SSD磁盘
- 部署3/5/7个节点组成高可用集群
- 定期备份数据
3.2 工作节点:干活的工人
Kubelet 是节点上的"监工",它:
- 每20秒向API Server报告节点状态
- 监控容器资源使用情况
- 执行Pod的生命周期操作
Kube-Proxy 维护网络规则,实现Service的VIP(虚拟IP)路由。当前主要支持三种模式:
- userspace(已淘汰)
- iptables(默认)
- IPVS(高性能推荐)
4. 核心概念:Pod设计哲学
4.1 为什么需要Pod?
Docker提倡"一个容器一个进程",但现实中的服务往往需要多个紧密协作的进程。比如:
- Web服务器 + 日志收集器
- 主应用 + 配置热加载器
- 服务网格的Sidecar代理
Pod通过Linux命名空间隔离机制,让多个容器:
- 共享相同的网络栈(同一个IP)
- 通过Volume共享存储
- 可以通过localhost直接通信
4.2 Pod生命周期管理
Pod会经历以下阶段:
- Pending:调度中
- Running:至少一个容器运行中
- Succeeded:所有容器成功退出
- Failed:至少一个容器异常退出
- Unknown:状态无法获取
通过探针(Liveness/Readiness)可以更精确控制:
yaml复制livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
5. 生产环境最佳实践
5.1 资源限制与QoS
未设置资源限制的Pod就像高速公路上的危险驾驶者。建议始终定义:
yaml复制resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
这会影响K8S的QoS分级:
- Guaranteed:requests == limits
- Burstable:有requests但limits更高
- BestEffort:未设置任何限制
5.2 配置分离的艺术
通过ConfigMap和Secret管理配置:
bash复制kubectl create configmap game-config --from-file=./game.properties
然后在Pod中挂载:
yaml复制volumes:
- name: config-volume
configMap:
name: game-config
5.3 日志与监控方案
推荐组合:
- Prometheus:指标收集
- Grafana:可视化仪表盘
- EFK:Elasticsearch + Fluentd + Kibana日志系统
部署示例:
bash复制helm install prometheus-stack prometheus-community/kube-prometheus-stack
6. 常见问题排雷指南
6.1 Pod一直处于Pending状态
排查步骤:
kubectl describe pod <name>查看事件- 常见原因:
- 资源不足(检查
kubectl get nodes -o wide) - 不满足节点选择器/亲和性规则
- PV绑定失败
- 资源不足(检查
6.2 服务无法访问
诊断流程:
- 检查Service的Endpoints是否正常:
bash复制
kubectl get endpoints <service-name> - 验证网络策略(NetworkPolicy)是否阻止流量
- 测试从Pod内部直接访问目标端口
6.3 镜像拉取失败
解决方案:
- 检查镜像地址拼写
- 配置imagePullSecrets用于私有仓库认证
- 预拉取镜像到节点:
bash复制
docker pull <image> && kind load docker-image <image>
7. 从单机到集群的演进之路
当你的应用从几个容器发展到上百个微服务时,会经历典型的架构演进:
- 原始阶段:手工运行docker run
- 脚本化:用Shell脚本管理容器
- 编排工具:引入Docker Compose
- 生产级编排:迁移到K8S集群
- 云原生进阶:采用Service Mesh、Serverless等架构
某金融企业的真实迁移案例:
- 原有系统:20台物理机,手动部署
- 迁移后:K8S集群(10个节点),资源利用率提升40%
- 部署时间:从2小时缩短到5分钟
- 年度运维成本下降60%
8. 现代开发者的K8S技能栈
要真正掌握K8S,建议循序渐进学习:
-
基础核心:
- Pod/Deployment/Service概念
- kubectl常用操作
- YAML文件编写
-
中级技能:
- 持久化存储(PV/PVC)
- 配置管理(ConfigMap/Secret)
- 网络策略(NetworkPolicy)
-
高级主题:
- 自定义资源定义(CRD)
- 操作器模式(Operator)
- 集群联邦(Federation)
-
生态工具:
- Helm:包管理
- ArgoCD:GitOps实践
- Istio:服务网格
我个人的学习建议是:先在Minikube或Kind本地环境练习,然后通过实际项目加深理解。遇到问题时,K8S官方文档和GitHub Issue是最可靠的参考资料。