
1. Lasso回归实战:从数据预处理到结果解读
在医学研究和生物统计领域,变量选择一直是个令人头疼的问题。传统回归分析在面对高维数据时,往往会陷入过拟合或解释性差的困境。而Lasso回归通过引入L1正则化,不仅能够进行变量选择,还能有效防止过拟合,成为临床研究中强有力的分析工具。
我最近在分析一组心血管疾病风险因素数据时,就深刻体会到了Lasso回归的价值。面对27个潜在的风险因素,传统方法要么难以取舍,要么构建的模型过于复杂。通过Lasso回归,我最终筛选出了4个最具临床意义的变量,大大简化了模型,同时保持了良好的预测性能。
2. 数据预处理:为Lasso回归奠定基础
2.1 数据清洗与变量整理
数据质量是任何统计分析的前提,对于Lasso回归尤为重要。在开始建模前,我们需要对数据进行系统性的清洗和整理:
r复制# 加载必要的R包
library(dplyr) # 数据清洗和转换
library(tidyr) # 数据整理
library(mice) # 缺失值处理
# 检查数据结构
str(data)
summary(data)
关键步骤解析:
-
变量分类与编码:
- 明确区分因变量(结局变量)和自变量(预测变量)
- 对分类变量进行哑变量编码(dummy coding)
- 特别注意有序分类变量的处理方式
-
缺失值处理策略:
- 连续变量:均值/中位数插补
- 分类变量:众数插补
- 缺失率>20%的变量建议直接剔除
- 考虑使用多重插补(mice包)处理复杂缺失模式
注意:Lasso回归对缺失值较为敏感,务必确保数据完整性。在临床研究中,缺失模式本身可能包含重要信息,需要仔细评估。
2.2 数据标准化与拆分
Lasso回归对变量的量纲非常敏感,因此标准化是必不可少的步骤:
r复制# 数值变量标准化
data_scaled <- data %>%
mutate(across(where(is.numeric),
~ scale(.),
.names = "{.col}_scaled"))
# 分类变量转为因子
categorical_vars <- c("sex", "smoke", "HTN", "DM")
for (var in categorical_vars) {
data_scaled[[var]] <- as.factor(data_scaled[[var]])
}
# 数据拆分(70%训练集,30%测试集)
set.seed(123)
train_indices <- sample(1:nrow(data_scaled), 0.7*nrow(data_scaled))
train_data <- data_scaled[train_indices, ]
test_data <- data_scaled[-train_indices, ]
标准化要点:
- Z-score标准化(均值0,标准差1)是最常用方法
- 分类变量不需要标准化,但需要转换为因子
- 标准化参数应从训练集计算,然后应用到测试集
- 对于生存数据,时间变量不应标准化
3. Lasso回归模型构建
3.1 模型矩阵准备
在R中构建Lasso回归模型前,需要准备专门的模型矩阵:
r复制library(glmnet)
library(survival)
# 定义预测变量
predictor_names <- c("sex", "smoke", "HTN", "DM", "BMI_scaled",
"SBP_scaled", "DBP_scaled", "ALT_scaled")
# 构建生存对象(对于Cox模型)
y <- Surv(train_data$time, train_data$event)
# 构建模型矩阵
x <- model.matrix(~ ., data = train_data[, predictor_names])[, -1]
关键细节:
model.matrix会自动处理因子变量,生成哑变量[, -1]用于去除截距项(glmnet会自行处理)- 对于不同类型的因变量,需要不同的设置:
- 连续变量:直接使用数值向量
- 二分类变量:使用因子或0/1编码
- 生存数据:使用Surv对象
3.2 交叉验证与λ选择
选择合适的正则化参数λ是Lasso回归的核心:
r复制set.seed(123)
cv_fit <- cv.glmnet(x, y, family = "cox", alpha = 1, nfolds = 10)
# 查看最优λ值
optimal_lambda <- cv_fit$lambda.min
simplified_lambda <- cv_fit$lambda.1se
cat("lambda.min:", optimal_lambda, "\n")
cat("lambda.1se:", simplified_lambda, "\n")
交叉验证要点:
alpha=1表示纯Lasso回归(α=0为岭回归,0<α<1为弹性网络)nfolds=10表示10折交叉验证lambda.min对应最小交叉验证误差lambda.1se对应误差在最小值1个标准误内的最简模型
4. 结果可视化与解读
4.1 交叉验证曲线分析
r复制plot(cv_fit)
abline(v = log(cv_fit$lambda.min), col = "red", lty = 2)
abline(v = log(cv_fit$lambda.1se), col = "blue", lty = 2)
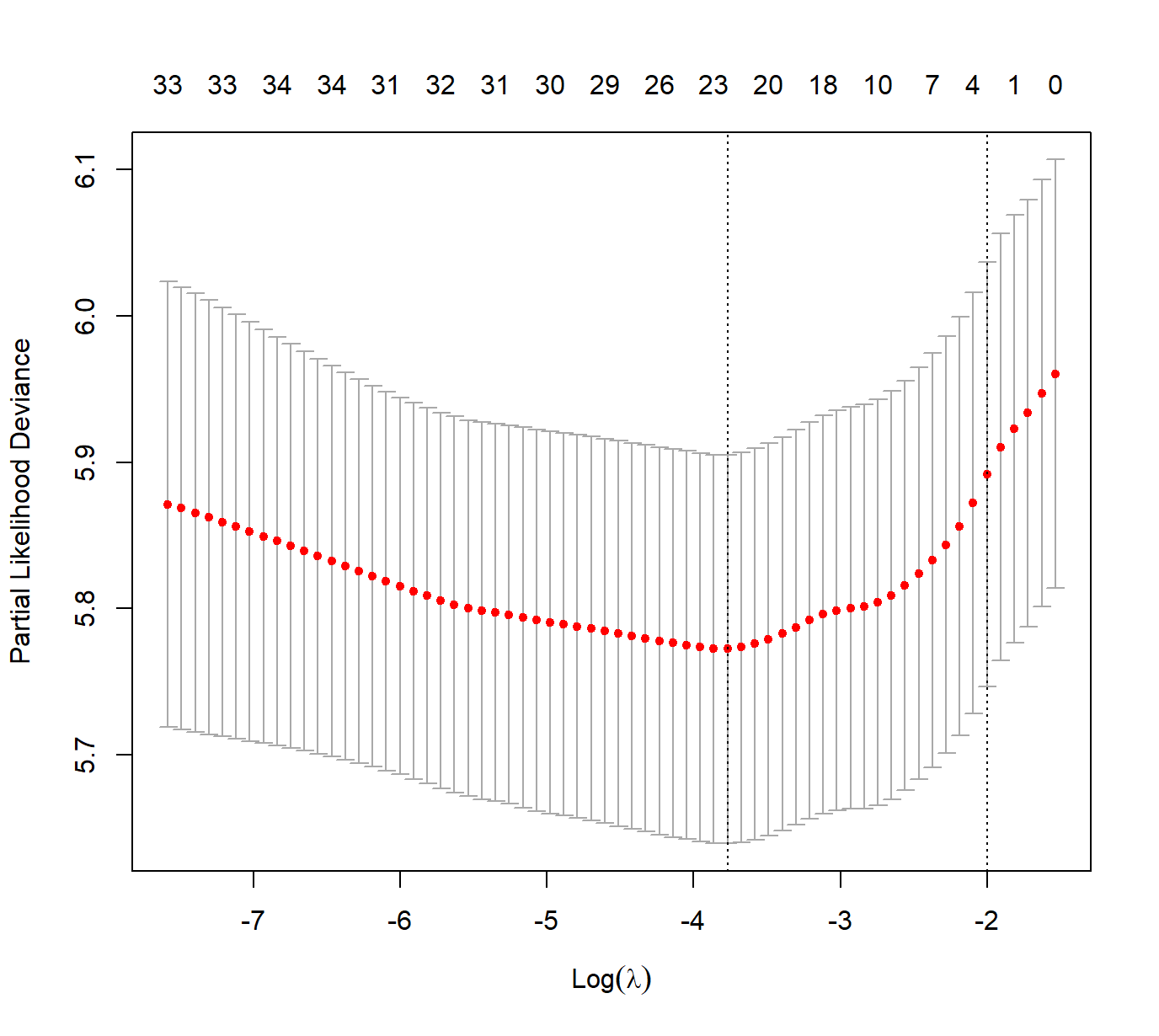
曲线解读要点:
- 横轴:log(λ)值,反映正则化强度
- 纵轴:交叉验证误差(对于Cox模型是偏似然偏差)
- 红色虚线:lambda.min,对应最小误差
- 蓝色虚线:lambda.1se,对应误差略大但更简化的模型
- 上横轴:对应λ值的非零系数数量
4.2 系数路径图解读
r复制fit_full <- glmnet(x, y, family = "cox", alpha = 1)
plot(fit_full, xvar = "lambda", label = TRUE)
abline(v = log(optimal_lambda), col = "red", lty = 2)
abline(v = log(simplified_lambda), col = "blue", lty = 2)
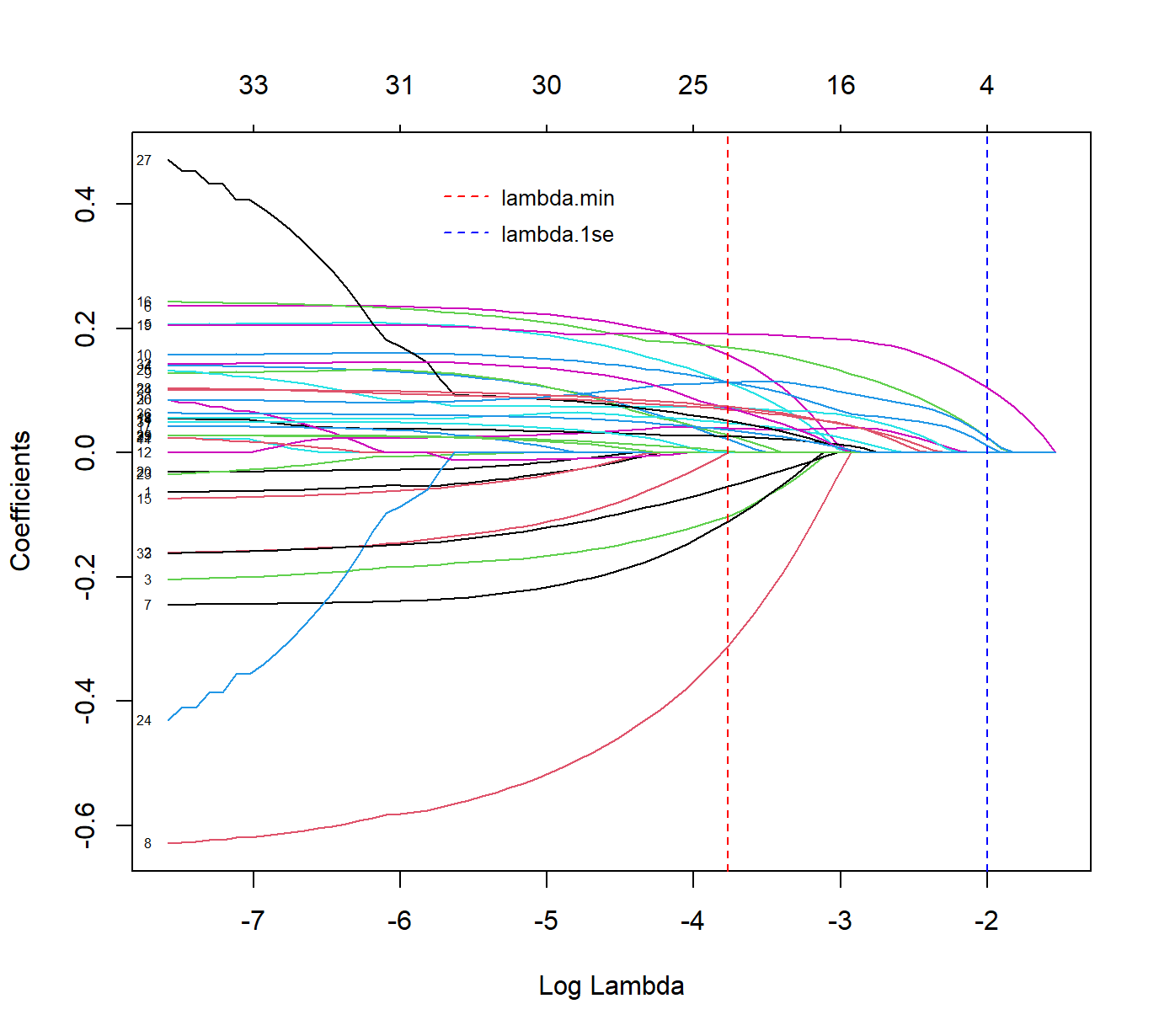
路径图解析:
- 每条彩色线代表一个变量的系数变化轨迹
- 从左到右,随着λ增大(惩罚增强),系数逐步收缩至0
- 最先消失的变量被认为贡献较小
- 最后保留的变量被认为最重要
4.3 变量选择与系数提取
r复制# 使用lambda.1se获取精简模型
coef_1se <- coef(cv_fit, s = "lambda.1se")
# 提取被选中的变量
selected_vars <- rownames(coef_1se)[as.vector(coef_1se != 0)]
selected_coef <- coef_1se[coef_1se != 0]
# 创建结果数据框
result_df <- data.frame(
Variable = selected_vars,
Coefficient = as.vector(selected_coef),
HR = exp(as.vector(selected_coef))
)
print(result_df)
结果解读要点:
- 系数大小反映变量影响程度
- 正系数表示危险因素,负系数表示保护因素
- 对于Cox模型,exp(系数)即为风险比(HR)
- 临床解释需结合专业背景
5. 实战经验与常见问题
5.1 变量筛选后的模型优化
Lasso回归筛选变量后,通常建议用传统方法重建模型:
r复制# 使用筛选出的变量构建Cox模型
final_vars <- c("HTN", "DM", "SBP_scaled", "BMI_scaled")
final_formula <- as.formula(paste("Surv(time, event) ~",
paste(final_vars, collapse = " + ")))
cox_fit <- coxph(final_formula, data = train_data)
summary(cox_fit)
优化建议:
- 检查比例风险假设(cox.zph)
- 评估模型校准度(校准曲线)
- 在测试集上验证模型性能
5.2 常见问题与解决方案
问题1:变量过多导致筛选不稳定
- 解决方案:先进行单变量筛选(p<0.2)
- 考虑使用弹性网络(alpha=0.5-0.9)
问题2:重要临床变量被剔除
- 解决方案:强制纳入关键变量(penalty.factor参数)
- 调整λ选择标准(更接近lambda.min)
问题3:模型在测试集表现差
- 检查训练/测试集分布是否一致
- 考虑增加样本量或使用bootstrap验证
5.3 高级技巧与扩展应用
-
分层Lasso:对不同变量组设置不同的惩罚强度
r复制penalty_factor <- ifelse(colnames(x) %in% clinical_vars, 0.5, 1) cv.glmnet(x, y, penalty.factor = penalty_factor) -
自适应Lasso:使用初始估计调整惩罚权重
r复制initial_coef <- coef(cv.glmnet(x, y, alpha = 0.5)) weights <- 1/abs(initial_coef[-1]) # 去除截距项 -
时间依赖性Lasso:处理时变协变量
r复制library(glmnetUtils) cv.glmnet(Surv(time, event) ~ ., data = train_data, family = "cox")
6. 临床研究的实际应用建议
在临床研究中应用Lasso回归时,有几个关键考虑:
-
变量预筛选:虽然Lasso可以处理高维数据,但临床变量通常需要基于病理生理学知识预先筛选
-
结果解释:Lasso筛选的变量仍需临床合理性检验,避免纯粹数据驱动的结论
-
模型验证:必须在独立数据集验证,特别是当样本量较小时
-
报告规范:应完整报告:
- 数据预处理步骤
- λ选择方法和依据
- 最终入选变量及系数
- 模型性能指标
-
与领域专家协作:统计结果必须结合临床意义解读
我在分析一组代谢综合征数据时,Lasso回归筛选出了腰围、空腹血糖和HDL三个关键指标。通过与内分泌专家的讨论,我们发现这一结果与当前代谢综合征的诊断标准高度一致,但同时也提示血压指标在本人群中的预测价值相对较低,这为后续研究提供了新的方向。