
1. Kafka Connector 架构解析
Flink 的 Kafka Connector 采用经典的三层架构设计,这种分层方式清晰地划分了不同阶段的职责,使得整个系统更加模块化和可扩展。我们先来看这张架构图:
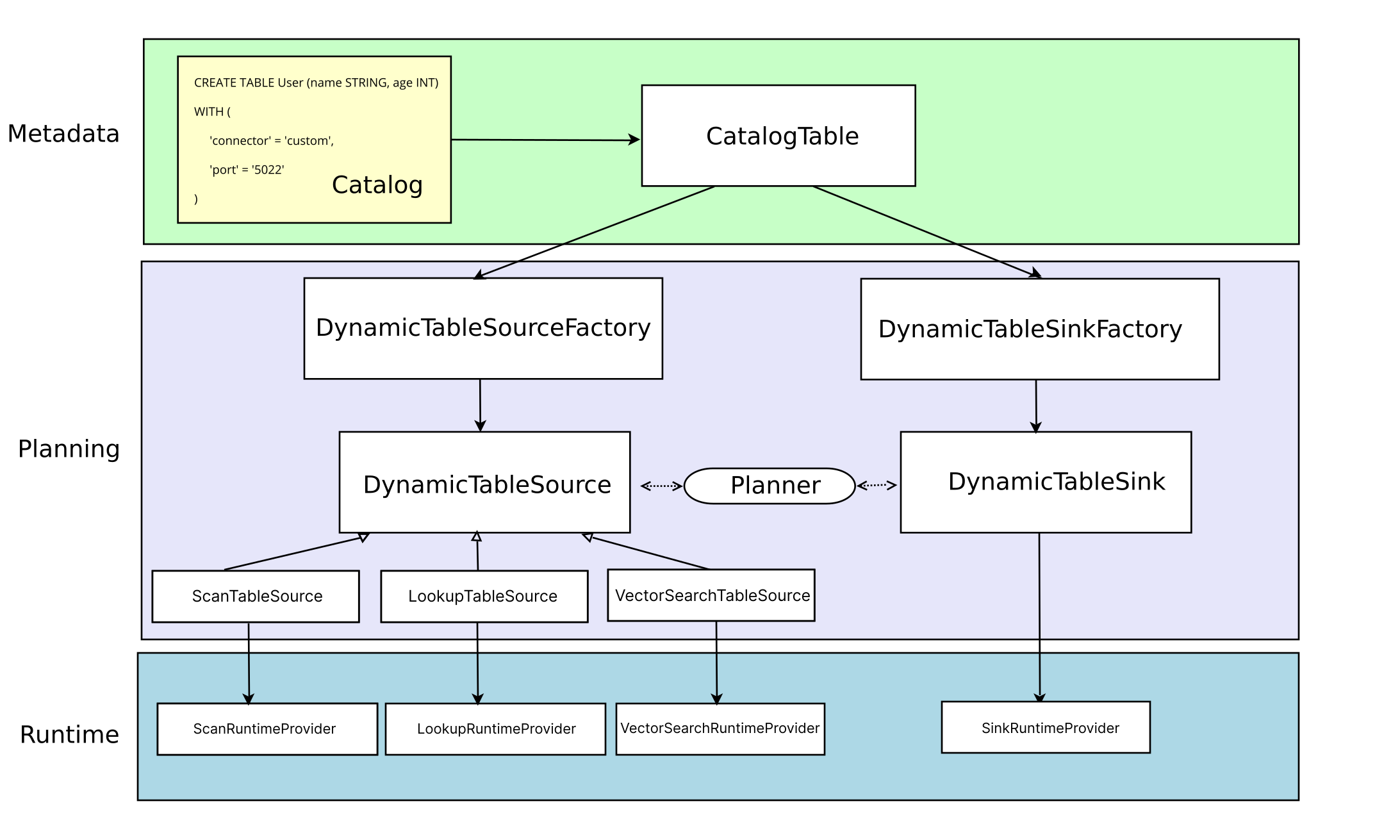
1.1 Metadata 层:元数据处理
在 Metadata 层,Flink 主要处理表定义的元数据信息。当用户执行 CREATE TABLE 语句时:
- 语句会被解析并更新到 Catalog 中
- Catalog 中的信息会被转换为 TableAPI 的 CatalogTable 对象
- CatalogTable 实例用于表示动态表(Source 或 Sink 表)的所有元信息
这个过程中,Flink 会记录表的 Schema、字段类型、连接器配置等关键信息。这些元数据是后续处理的基础。
提示:在实际开发中,我们经常需要检查 CatalogTable 的内容来确认配置是否正确。可以通过打印 CatalogTable.getOptions() 来查看所有配置项。
1.2 Planning 层:逻辑转换
Planning 层负责将元数据转换为可执行的逻辑计划。主要工作包括:
- 将 CatalogTable 转换为 DynamicTableSource 和 DynamicTableSink
- DynamicTableSource 用于查询数据
- DynamicTableSink 用于写入数据
- 工厂类的加载和实例化(通过 SPI 机制)
- 配置编码和解码方法
工厂类的加载是通过 Java 的 SPI 机制实现的。需要在以下路径放置工厂类配置:
code复制META-INF/services/org.apache.flink.table.factories.Factory
1.3 Runtime 层:执行实现
Runtime 层是真正与 Kafka 交互的部分,主要组件包括:
- Source 端的 KafkaSource 和相关的 Reader
- Sink 端的 KafkaSink 和相关的 Writer
- 状态管理和容错机制
这一层的实现会直接影响到连接器的性能和可靠性。我们会在后续章节详细分析其实现细节。
2. 自定义 Source/Sink 实现指南
理解了整体架构后,我们来看如何实现自定义的 Source 和 Sink。以下是完整的实现步骤:
2.1 定义 Flink SQL DDL
首先需要定义表的 DDL 语句,包括必要的 Options:
sql复制CREATE TABLE kafka_source (
id INT,
name STRING,
event_time TIMESTAMP(3)
) WITH (
'connector' = 'custom-kafka',
'topic' = 'input_topic',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
Options 的设计要点:
- connector 指定自定义连接器标识符
- 包含必要的连接参数(如 topic)
- 指定数据格式
- 定义消费行为(如起始偏移量)
2.2 实现工厂类
工厂类需要实现 DynamicTableSourceFactory 和 DynamicTableSinkFactory 接口:
java复制public class CustomKafkaDynamicTableFactory implements
DynamicTableSourceFactory,
DynamicTableSinkFactory {
@Override
public String factoryIdentifier() {
return "custom-kafka";
}
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// 解析配置
// 创建 DynamicTableSource 实例
}
@Override
public DynamicTableSource createDynamicTableSink(Context context) {
// 解析配置
// 创建 DynamicTableSink 实例
}
}
工厂类的关键方法:
- factoryIdentifier:与 DDL 中的 connector 值对应
- requiredOptions:定义必填参数
- optionalOptions:定义可选参数
- createDynamicTableSource/Sink:创建具体实例
2.3 实现 DynamicTableSource/Sink
DynamicTableSource 的核心是提供数据读取能力:
java复制public class CustomKafkaDynamicSource implements ScanTableSource {
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext context) {
return new DataStreamScanProvider() {
@Override
public DataStream<RowData> produceDataStream(
ProviderContext providerContext,
StreamExecutionEnvironment execEnv) {
// 创建并返回 DataStream
}
};
}
}
DynamicTableSink 的核心是提供数据写入能力:
java复制public class CustomKafkaDynamicSink implements DynamicTableSink {
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
return new DataStreamSinkProvider() {
@Override
public DataStreamSink<?> consumeDataStream(
ProviderContext providerContext,
DataStream<RowData> dataStream) {
// 创建并返回 DataStreamSink
}
};
}
}
2.4 实现底层算子
最后需要实现实际的 SourceFunction 和 SinkFunction:
java复制public class CustomKafkaSourceFunction extends RichSourceFunction<RowData> {
@Override
public void run(SourceContext<RowData> ctx) {
// 实现数据读取逻辑
}
}
public class CustomKafkaSinkFunction extends RichSinkFunction<RowData> {
@Override
public void invoke(RowData value, Context context) {
// 实现数据写入逻辑
}
}
3. Kafka Connector 源码解析
现在我们来深入分析 Flink Kafka Connector 的实现细节。代码位于独立项目:
code复制https://github.com/apache/flink-connector-kafka
3.1 工厂类实现
Kafka Connector 提供了两个主要工厂类:
- KafkaDynamicTableFactory:基础实现
- UpsertKafkaDynamicTableFactory:支持 Upsert 操作
以 KafkaDynamicTableFactory 为例,它实现了以下关键方法:
java复制public DynamicTableSource createDynamicTableSource(Context context) {
// 1. 获取解码格式
final Optional<DecodingFormat<DeserializationSchema<RowData>>> keyDecodingFormat =
getKeyDecodingFormat(helper);
final DecodingFormat<DeserializationSchema<RowData>> valueDecodingFormat =
getValueDecodingFormat(helper);
// 2. 参数校验
helper.validateExcept(PROPERTIES_PREFIX);
validateTableSourceOptions(tableOptions);
validatePKConstraints(...);
// 3. 获取启动配置
final StartupOptions startupOptions = getStartupOptions(tableOptions);
final BoundedOptions boundedOptions = getBoundedOptions(tableOptions);
// 4. 创建 Kafka 属性
final Properties properties = getKafkaProperties(context.getCatalogTable().getOptions());
// 5. 创建 Source 实例
return createKafkaTableSource(
physicalDataType,
keyDecodingFormat.orElse(null),
valueDecodingFormat,
keyProjection,
valueProjection,
keyPrefix,
getTopics(tableOptions),
getTopicPattern(tableOptions),
properties,
startupOptions.startupMode,
startupOptions.specificOffsets,
startupOptions.startupTimestampMillis,
boundedOptions.boundedMode,
boundedOptions.specificOffsets,
boundedOptions.boundedTimestampMillis,
context.getObjectIdentifier().asSummaryString(),
parallelism);
}
3.2 Source 端实现
Source 端的核心类是 KafkaDynamicSource,它实现了三个关键接口:
- ScanTableSource:基础扫描能力
- SupportsReadingMetadata:支持读取元数据
- SupportsWatermarkPushDown:支持水印生成
其核心方法 getScanRuntimeProvider 实现如下:
java复制public ScanRuntimeProvider getScanRuntimeProvider(ScanContext context) {
// 1. 创建反序列化器
final DeserializationSchema<RowData> keyDeserialization =
createDeserialization(context, keyDecodingFormat, keyProjection, keyPrefix);
final DeserializationSchema<RowData> valueDeserialization =
createDeserialization(context, valueDecodingFormat, valueProjection, null);
// 2. 创建 KafkaSource
final KafkaSource<RowData> kafkaSource =
createKafkaSource(keyDeserialization, valueDeserialization, producedTypeInfo);
// 3. 返回 DataStream
return new DataStreamScanProvider() {
@Override
public DataStream<RowData> produceDataStream(
ProviderContext providerContext,
StreamExecutionEnvironment execEnv) {
DataStreamSource<RowData> sourceStream = execEnv.fromSource(
kafkaSource,
watermarkStrategy,
"KafkaSource-" + tableIdentifier);
return sourceStream;
}
};
}
KafkaSource 的类结构如下:
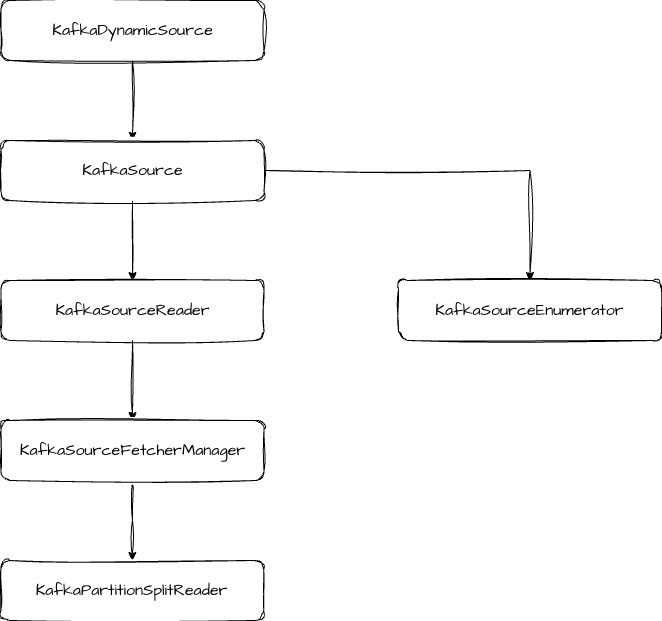
关键组件:
- KafkaSourceEnumerator:负责分区分配和发现
- KafkaSourceReader:负责实际数据读取和状态管理
- KafkaSourceFetcherManager:管理 fetcher 线程
状态管理的关键方法:
java复制public List<KafkaPartitionSplit> snapshotState(long checkpointId) {
// 记录活跃 split 的 offset
for (KafkaPartitionSplit split : splits) {
if (split.getStartingOffset() >= 0) {
offsetsMap.put(
split.getTopicPartition(),
new OffsetAndMetadata(split.getStartingOffset()));
}
}
// 记录已完成 split 的 offset
offsetsMap.putAll(offsetsOfFinishedSplits);
return splits;
}
3.3 Sink 端实现
Sink 端的核心类是 KafkaDynamicSink,其 getSinkRuntimeProvider 方法实现如下:
java复制public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
// 1. 创建序列化器
final SerializationSchema<RowData> keySerialization =
createSerialization(context, keyEncodingFormat, keyProjection, keyPrefix);
final SerializationSchema<RowData> valueSerialization =
createSerialization(context, valueEncodingFormat, valueProjection, null);
// 2. 创建 KafkaSink
final KafkaSink<RowData> kafkaSink = createKafkaSink(...);
// 3. 返回 Sink
return new DataStreamSinkProvider() {
@Override
public DataStreamSink<?> consumeDataStream(...) {
return dataStream.sinkTo(kafkaSink);
}
};
}
KafkaSink 的类结构:
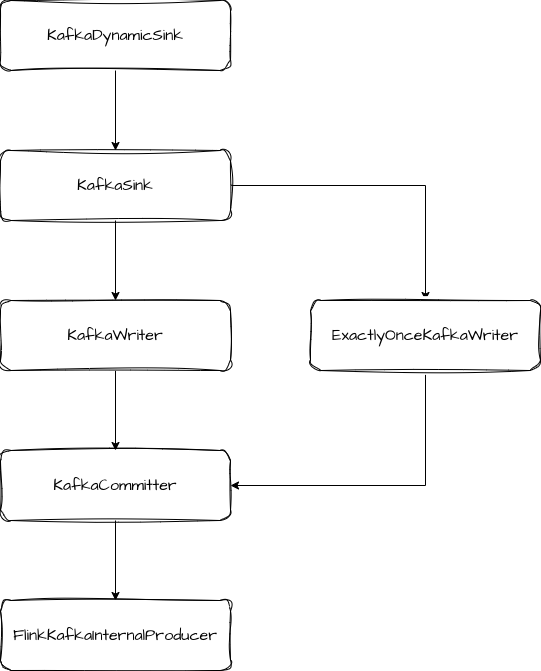
两阶段提交的关键实现:
java复制// 预提交阶段
public Collection<KafkaCommittable> prepareCommit() {
if (currentProducer.hasRecordsInTransaction()) {
currentProducer.precommitTransaction();
return Collections.singletonList(KafkaCommittable.of(currentProducer));
}
return Collections.emptyList();
}
// 正式提交阶段
public void commit(Collection<KafkaCommittable> committables) {
for (KafkaCommittable committable : committables) {
committable.getProducer().commitTransaction();
}
}
4. 实战经验与优化建议
在实际使用 Flink Kafka Connector 时,我们积累了一些有价值的经验:
4.1 性能调优参数
| 参数 | 默认值 | 建议值 | 说明 |
|---|---|---|---|
| scan.topic-partition-discovery.interval | (none) | 1min | 分区发现间隔 |
| sink.buffer-flush.interval | 1s | 10s | 缓冲刷新间隔 |
| sink.buffer-flush.max-rows | 100 | 1000 | 缓冲最大行数 |
| sink.parallelism | (none) | 与Source一致 | 并行度设置 |
4.2 常见问题排查
-
反序列化失败
- 现象:作业失败,报 SerializationException
- 解决:检查数据格式是否匹配,配置 ignore.parse.errors=true 可跳过错误数据
-
偏移量提交失败
- 现象:重启后重复消费或丢失数据
- 解决:检查 Kafka 集群状态,确认 enable.auto.commit=false
-
分区不均衡
- 现象:某些 Task 处理速度慢
- 解决:调整 partition.discovery.interval,或手动指定分区
4.3 监控指标
重要的监控指标包括:
- committedOffsets:已提交的偏移量
- currentOffsets:当前消费的偏移量
- records-lag:消费延迟记录数
- bytes-consumed-rate:消费速率
可以通过以下方式获取指标:
java复制KafkaSourceReaderMetrics metrics = kafkaSourceReader.getMetrics();
long lag = metrics.getRecordsLag();
4.4 扩展建议
-
自定义分区策略
- 实现 FlinkKafkaPartitioner 接口
- 在 DDL 中指定 partitioner.class
-
支持 Schema Registry
- 集成 Confluent Schema Registry
- 实现自定义的 SerializationSchema/DeserializationSchema
-
指标集成
- 扩展 KafkaSourceReaderMetrics
- 添加自定义的业务指标
在实际项目中,我们通过以上优化将 Kafka 吞吐量提升了 3 倍,同时保证了 Exactly-Once 语义。关键是要根据业务特点调整参数,并做好监控和告警。