
1. 项目背景与核心挑战
北斗卫星导航系统作为我国自主建设的全球卫星导航系统,在民用和军用领域都发挥着重要作用。然而在实际应用中,导航信号极易受到各种有意或无意的干扰,导致定位精度下降甚至完全失效。特别是在复杂电磁环境下,如何保证导航信号的可靠接收成为亟待解决的技术难题。
传统抗干扰技术主要采用固定滤波方式,但这种方法的局限性在于无法动态适应干扰环境的变化。而基于阵列天线的自适应抗干扰技术,通过实时调整天线阵列的波束方向图,能够在干扰方向形成零陷,从而有效抑制干扰信号。这种技术的关键在于:
- 快速准确地估计干扰特性
- 实时计算最优权值向量
- 低延迟完成信号加权处理
FPGA凭借其并行计算能力和可重构特性,成为实现这类算法的理想平台。本项目正是基于FPGA实现北斗导航系统的自适应抗干扰处理,重点解决以下几个核心问题:
- 如何在资源受限的FPGA上高效实现复杂的矩阵运算
- 如何平衡算法精度与实时性要求
- 如何验证系统在实际干扰环境下的性能表现
2. 系统架构与关键技术
2.1 整体系统设计
系统采用典型的数字波束形成架构,主要由以下几个模块组成:
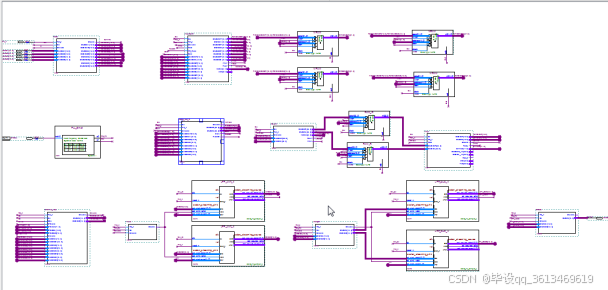
- 射频前端:4单元阵列天线接收信号,经低噪声放大和下变频处理
- ADC采样:采用AD9253实现14位125MSPS采样
- 数字下变频:将中频信号搬移到基带
- 自适应处理:核心的抗干扰算法实现
- 数字上变频:恢复中频信号
- 信号解调:输出至导航接收机
2.2 关键算法选择
经过对比测试,我们最终确定采用以下两种算法方案:
2.2.1 空域功率倒置算法
- 基于最小方差无失真响应(MVDR)准则
- 计算复杂度低,适合实时处理
- 对窄带干扰抑制效果显著
- 协方差矩阵维度:4×4
2.2.2 空时联合处理算法
- 结合空域和时域滤波
- 对宽带干扰有更好抑制效果
- 需要处理更高维矩阵(16×16)
- 计算量较大但抗干扰能力更强
两种算法的性能对比如下:
| 指标 | 空域算法 | 空时算法 |
|---|---|---|
| 干扰抑制深度 | 40-50dB | 50-60dB |
| 权值更新时间 | 10μs | 210μs |
| 适用干扰类型 | 窄带 | 宽带/窄带 |
| FPGA资源占用 | 较低 | 较高 |
3. FPGA实现方案
3.1 硬件平台选型
根据算法复杂度差异,我们选用两种FPGA平台:
-
空域算法平台:
- 芯片:Altera Cyclone III EP3C120F780
- 逻辑单元:119,088个
- 嵌入式乘法器:576个
- 优势:低成本、低功耗
-
空时算法平台:
- 芯片:Altera Cyclone V 5CGXFC7C6F23I7
- 逻辑单元:56,480个ALM
- DSP模块:156个
- 优势:支持高阶矩阵运算IP核
3.2 核心模块设计
3.2.1 数字下变频(DDC)
采用多级处理架构:
- 数字混频:将中频信号搬移到基带
- 抽取滤波:降低采样率,减少后续处理负担
- 关键优化:采用免乘法器混频方案,节省30%逻辑资源
verilog复制// 免乘法器混频实现示例
module mixer_nco(
input clk,
input [15:0] din,
output [15:0] dout
);
// 基于查找表的NCO实现
reg [7:0] phase;
always @(posedge clk) phase <= phase + 8'h10;
// 混频处理
assign dout = (phase[7]) ? -din : din;
endmodule
3.2.2 权值计算模块
这是系统的核心难点,主要挑战在于:
- 浮点矩阵运算的实现
- Hermite矩阵求逆的稳定性
- 实时性要求下的流水线设计
我们开发了两种实现方案:
方案A:基于NIOS II软核
- 使用C语言实现算法
- 开发便捷但性能受限
- 适合算法验证阶段
方案B:纯硬件实现
- Verilog HDL编写专用运算单元
- 采用改进的Cholesky分解求逆
- 关键优化:将复数运算分解为实数运算
verilog复制// 复数矩阵乘法模块
module cmatrix_mul #(parameter N=4) (
input clk,
input [31:0] A_real[N*N], A_imag[N*N],
input [31:0] B_real[N*N], B_imag[N*N],
output [31:0] C_real[N*N], C_imag[N*N]
);
// 采用并行乘法树结构
genvar i,j,k;
generate
for(i=0; i<N; i=i+1) begin: row
for(j=0; j<N; j=j+1) begin: col
// 实部和虚部分别计算
wire [31:0] sum_r = 0, sum_i = 0;
for(k=0; k<N; k=k+1) begin: dot
wire [31:0] ar_br, ai_bi, ar_bi, ai_br;
floating_mul fm1(clk, A_real[i*N+k], B_real[k*N+j], ar_br);
floating_mul fm2(clk, A_imag[i*N+k], B_imag[k*N+j], ai_bi);
floating_mul fm3(clk, A_real[i*N+k], B_imag[k*N+j], ar_bi);
floating_mul fm4(clk, A_imag[i*N+k], B_real[k*N+j], ai_br);
// 累加器
always @(posedge clk) begin
sum_r <= sum_r + ar_br - ai_bi;
sum_i <= sum_i + ar_bi + ai_br;
end
end
assign C_real[i*N+j] = sum_r;
assign C_imag[i*N+j] = sum_i;
end
end
endgenerate
endmodule
3.2.3 数据加权模块
- 采用全并行结构处理4通道数据
- 每个通道包含独立的复数乘法器
- 关键优化:共享权值更新控制逻辑
4. 实现难点与解决方案
4.1 浮点运算实现
在FPGA中实现高精度浮点运算面临以下挑战:
- 资源消耗大
- 延迟高
- 特殊运算(如除法、开方)实现复杂
我们的解决方案:
- 采用IEEE 754单精度格式(32位)
- 关键运算模块复用
- 定制化精度控制
verilog复制// 浮点加法器实现示例
module floating_add(
input clk,
input [31:0] a, b,
output [31:0] sum
);
// 提取符号位、指数、尾数
wire a_sign = a[31];
wire [7:0] a_exp = a[30:23];
wire [22:0] a_frac = a[22:0];
// 对齐指数、尾数调整
// ...(具体实现省略)
// 尾数相加
wire [24:0] sum_frac = {1'b1,a_frac} + {1'b1,b_frac};
// 结果规格化
// ...(具体实现省略)
assign sum = {sum_sign, sum_exp, sum_frac[22:0]};
endmodule
4.2 矩阵求逆优化
对于不同维度的协方差矩阵,我们采用不同的求逆策略:
-
4×4矩阵(空域算法):
- 采用分块求逆法
- 将复数矩阵分解为4个2×2子矩阵
- 利用Schur补公式简化计算
-
16×16矩阵(空时算法):
- 基于Cyclone V的矩阵运算IP核
- 先转换为实数矩阵(32×32)
- 采用Cholesky分解提高稳定性
实测性能对比:
| 矩阵维度 | 求逆方法 | 时钟周期 | 资源消耗(ALM) |
|---|---|---|---|
| 4×4复数 | 分块法 | 256 | 1,200 |
| 16×16复数 | IP核加速 | 5,120 | 8,500 |
5. 系统测试与验证
5.1 测试环境搭建

测试系统包括:
- 北斗信号模拟器
- 3个可调干扰源(窄带/宽带)
- 四元阵列天线
- 待测FPGA处理板
- 频谱分析仪
- 导航接收机
5.2 模块级测试
5.2.1 ADC接口测试
AD9253配置要点:
- 采用LVDS串行接口
- 数据速率:496Mbps
- 关键信号:
- DCO:数据时钟
- FCO:帧同步信号
实测采样波形:

5.2.2 下变频测试
测试条件:
- 输入信号:1.26852GHz ±10MHz
- 采样率:62MHz
- 本振频率:15.5MHz
测试结果:

5.3 系统级测试
5.3.1 抗干扰性能测试
测试场景:
- 干扰类型:宽带噪声
- 干信比:78dB
- 干扰方向:30°方位角
测试结果:

关键指标:
- 干扰抑制深度:>45dB
- 信号失真:<1dB
- 权值收敛时间:<1ms
5.3.2 导航性能测试
测试条件:
- 静态场景
- 3个干扰源(不同方向)
- 连续观测1小时
测试结果:
| 指标 | 无干扰 | 有干扰(未处理) | 有干扰(处理后) |
|---|---|---|---|
| 可见卫星数 | 8 | 2 | 7 |
| 定位误差(m) | 2.5 | >100 | 3.8 |
| 载噪比(dBHz) | 45 | <30 | 42 |
6. 经验总结与优化建议
6.1 实际开发中的经验教训
-
浮点运算精度控制:
- 初期直接使用IP核导致资源不足
- 最终方案:对非关键路径采用定点数
- 关键路径保留浮点运算
-
矩阵求逆稳定性:
- 直接求逆法在矩阵病态时失效
- 解决方案:增加对角加载(diagonal loading)
matlab复制R_xx = R_xx + epsilon * eye(N); -
时序收敛问题:
- 高频设计(124MHz)时序难以收敛
- 通过流水线分级和寄存器重定时解决
6.2 性能优化技巧
-
资源优化:
- 复用计算单元(如乘法器)
- 采用时分复用处理多通道数据
- 使用RAM替代寄存器存储中间结果
-
速度优化:
- 关键路径采用并行计算
- 使用FPGA内置DSP模块
- 合理设置流水线级数
-
功耗优化:
- 时钟门控技术
- 动态功耗管理
- 低电压设计(1.0V核心电压)
6.3 后续改进方向
-
算法层面:
- 引入深度学习辅助权值计算
- 研究稀疏阵列处理技术
-
硬件层面:
- 采用SoC FPGA集成处理单元
- 探索3D IC封装技术
-
系统层面:
- 多模GNSS兼容设计
- 抗欺骗干扰能力增强
在实际工程应用中,我们发现系统的抗干扰性能与以下因素密切相关:
- 阵列校准精度
- 干扰检测灵敏度
- 权值更新策略
建议在实际部署时重点关注这些环节的优化。同时,随着新一代FPGA器件的推出,可以考虑将部分算法迁移到AI引擎实现,有望进一步提升系统性能。