
1. 项目概述:AI饮食助手的价值与定位
作为一名长期与饮食选择困难症斗争的程序员,我深知每天决定"吃什么"这个看似简单的问题有多么令人头疼。传统解决方案要么过于简单(如随机选择),要么过于复杂(如营养计算器),都难以满足现代人对饮食的个性化需求。而借助n8n低代码平台和AI技术,我们可以构建一个智能饮食助手,它能:
- 根据个人饮食偏好和历史记录进行智能推荐
- 自动记录每日饮食情况
- 生成周度饮食分析报告
- 通过微信等常用渠道推送提醒
这个项目的独特价值在于:
- 采用低代码方式实现,技术门槛大幅降低
- 整合了数据库操作、消息推送等实用功能
- 通过MCP协议扩展了大模型的能力边界
- 部署方案同时支持本地开发和云端生产环境
提示:即使没有专业的AI开发经验,通过n8n的可视化界面,普通开发者也能在2-3天内完成整个系统的搭建。
2. 环境准备与n8n平台部署
2.1 Docker环境配置
n8n官方推荐使用Docker进行部署,这能确保环境一致性并简化依赖管理。以下是详细步骤:
-
安装Docker Desktop(Windows/Mac)或docker-ce(Linux)
- Windows用户需启用WSL2支持
- Linux用户需配置docker用户组权限
-
创建数据卷(避免容器重启数据丢失):
bash复制docker volume create n8n_data
- 启动n8n容器(开发环境配置):
bash复制docker run -it --rm --name n8n \
-p 5678:5678 \
-v n8n_data:/home/node/.n8n \
docker.n8n.io/n8nio/n8n
- 生产环境建议添加以下参数:
bash复制 -e N8N_BASIC_AUTH_ACTIVE=true \
-e N8N_BASIC_AUTH_USER=<用户名> \
-e N8N_BASIC_AUTH_PASSWORD=<密码> \
--restart unless-stopped
2.2 平台初始化与账号注册
访问 http://localhost:5678 后,首次使用需完成:
- 邮箱注册(建议使用常用邮箱)
- 查收验证码邮件(可能在垃圾箱)
- 激活社区版许可证(永久免费)
注意事项:n8n的Fair-Code许可证允许个人和小团队免费自托管,但商业用途需购买企业版。如果出现注册问题,可以尝试清除浏览器缓存或使用隐私模式访问。
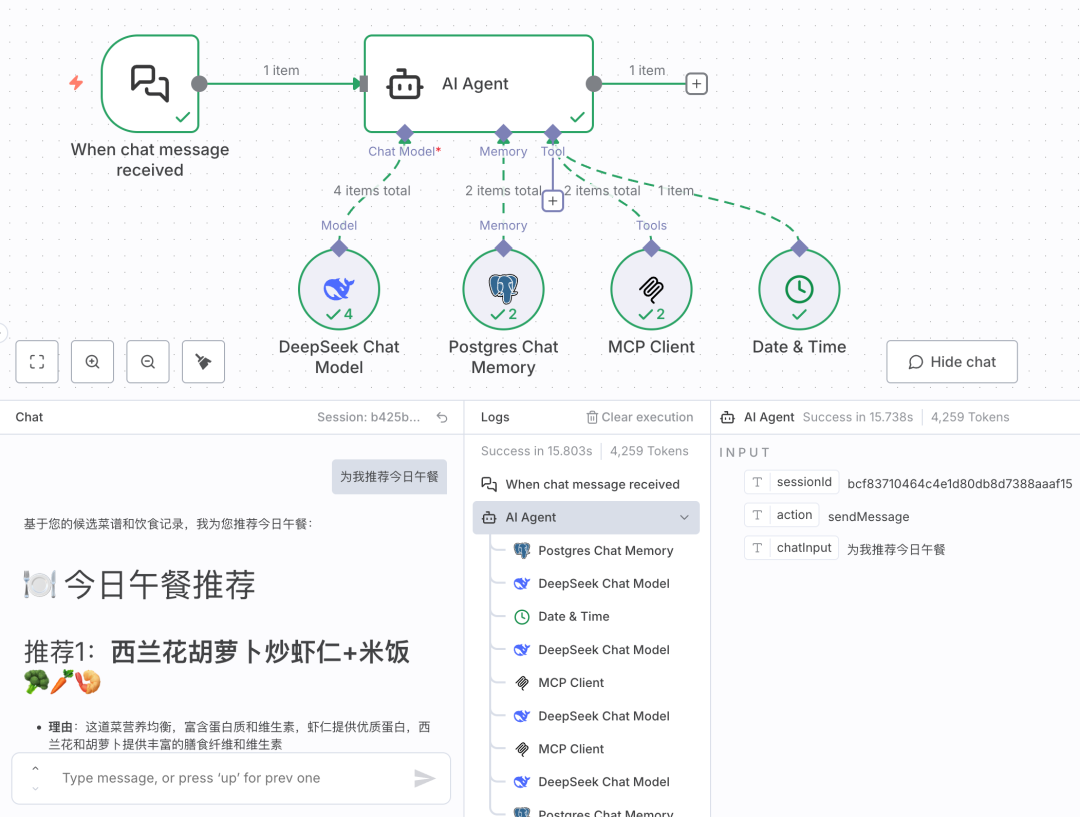
3. AI Agent核心组件配置
3.1 大语言模型接入
n8n支持多种LLM接入,以下是深度求索(DeepSeek)的配置示例:
-
获取API Key:
- 访问DeepSeek平台
- 创建应用并获取API Key(新用户有免费额度)
-
在n8n中添加AI Agent节点:
- 创建工作流(Workflow)
- 添加"AI Agent"节点
- 选择"DeepSeek Chat Model"
- 填入API Key
对于其他兼容OpenAI API的模型(如通义千问),可使用以下配置:
json复制{
"baseURL": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"apiKey": "your-api-key"
}
3.2 记忆存储方案选择
AI Agent的记忆系统决定了对话的连续性,我们有多种选择:
| 记忆类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Simple Memory | 零配置,开箱即用 | 重启后丢失 | 快速测试 |
| PostgreSQL | 持久化存储 | 需要数据库配置 | 生产环境 |
| Redis | 高性能 | 需要额外服务 | 高并发场景 |
推荐PostgreSQL配置示例:
yaml复制# docker-compose片段
services:
postgres:
image: postgres:15
environment:
POSTGRES_PASSWORD: yourpassword
volumes:
- pg_data:/var/lib/postgresql/data
volumes:
pg_data:
连接字符串格式:
code复制postgres://username:password@host.docker.internal:5432/dbname
3.3 工具集成策略
工具(Tools)是Agent能力的扩展,本项目中需要:
-
日期时间工具:
- 添加"Date & Time Tool"
- 设置时区为Asia/Shanghai
- 用于餐点时间判断
-
HTTP请求工具:
- 配置消息推送接口
- 配置饮食记录接口
- 需要处理JSON参数中的动态表达式
-
MCP客户端工具:
- 对接DBHub实现数据库查询
- 配置Endpoint地址
- 测试工具可用性
避坑指南:当工具较多时,建议为每个工具设置清晰的名称和描述,避免后续维护时混淆。工具的描述文本会直接影响AI对工具功能的理解。
4. DBHub MCP服务部署与配置
4.1 服务部署
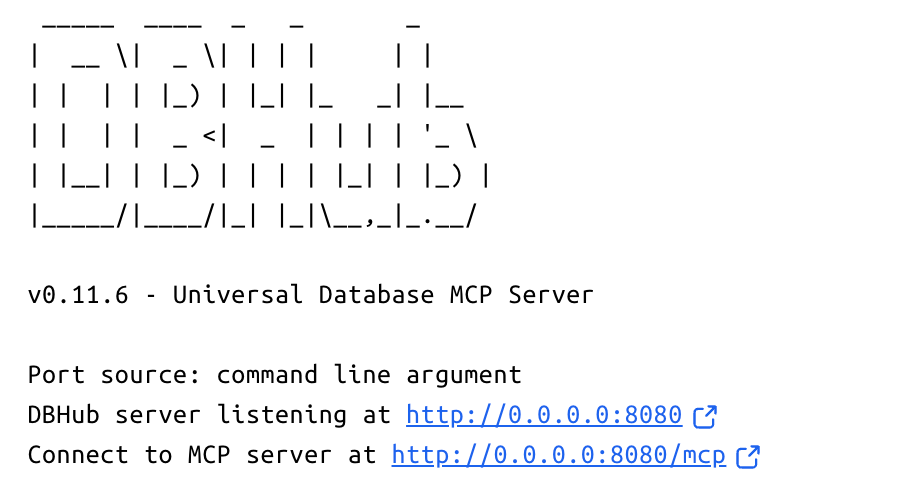
DBHub作为MCP协议的数据库中间件,使用Docker部署最为便捷:
bash复制docker run -d --name dbhub \
-p 8080:8080 \
-e DB_CONNECTION_STRING="mysql://root:password@host.docker.internal:3306/eat_what_today" \
bytebase/dbhub
4.2 数据库设计
需要准备两张核心表:
- 候选菜谱表(candidate_food):
sql复制CREATE TABLE candidate_food (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
category VARCHAR(20) COMMENT '如:川菜、粤菜、面食等',
cooking_method VARCHAR(20) COMMENT '炒、煮、蒸等',
difficulty TINYINT COMMENT '制作难度1-5',
last_recommended DATE COMMENT '上次推荐日期'
);
- 饮食记录表(my_dietary_record):
sql复制CREATE TABLE my_dietary_record (
id INT AUTO_INCREMENT PRIMARY KEY,
food_name VARCHAR(50) NOT NULL,
lunch_or_dinner ENUM('lunch','dinner') NOT NULL,
eat_date DATE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
4.3 MCP客户端配置
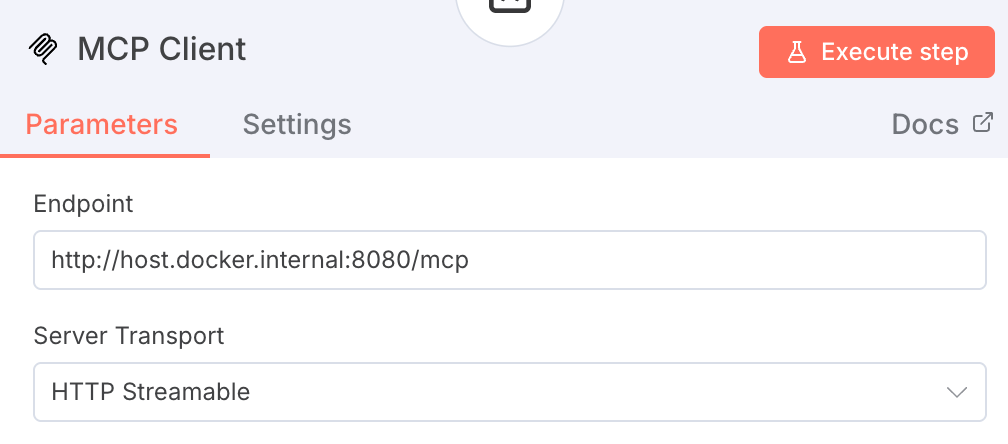
在AI Agent节点中添加MCP Client Tool:
-
Endpoint填写:
code复制
http://host.docker.internal:8080/mcp -
工具描述中注明可用方法:
markdown复制可调用方法: - execute_sql: 执行SQL查询 - resource__schemas: 获取数据库schema列表 - prompt__generate_sql: 自然语言转SQL
常见问题:如果出现连接失败,检查Docker容器网络配置,Linux环境下需添加
--add-host=host.docker.internal:host-gateway参数。
5. 提示词工程与AI行为设计
5.1 系统消息设计
系统消息决定了AI的基础行为模式,以下是饮食助手的核心提示词:
text复制你是一个专业的AI饮食助手,需要根据以下规则为用户推荐餐食:
1. 多样性原则:
- 避免连续三天推荐同类菜品
- 午餐和晚餐应有明显区别
- 每周海鲜不超过2次
2. 健康原则:
- 早餐推荐易消化食物
- 晚餐不推荐油炸食品
- 控制碳水化合物的摄入频次
3. 个性化设置:
- 用户忌口:生食、动物内脏
- 偏好:喜欢川菜但不宜过辣
- 可接受外卖但不超过50%
4. 数据查询:
- 使用execute_sql查询candidate_food和my_dietary_record表
- 推荐前检查近期饮食记录
- 更新候选菜谱的last_recommended字段
5.2 工具调用提示
明确指导AI如何使用各种工具:
text复制可用工具及使用场景:
1. Date & Time Tool:
- 判断当前是午餐还是晚餐时间
- 计算周报日期范围
2. MCP execute_sql:
- 查询:"SELECT name FROM candidate_food WHERE..."
- 避免直接使用INSERT/UPDATE
3. Send notice to user:
- 推荐结果自动发送
- 周报定时发送
- 格式:"【推荐】今日午餐:XXX"
4. Save the food:
- 当用户说"今天吃了XXX"时调用
- 参数格式:{"food_name":"XXX","meal_type":"lunch"}
5.3 测试与迭代
通过Chat Trigger节点进行对话测试:
-
典型测试用例:
- "推荐今天的午餐"
- "我中午吃了宫保鸡丁"
- "生成本周饮食报告"
-
观察AI的:
- 工具调用顺序
- SQL查询合理性
- 推荐逻辑是否符合预期
-
迭代优化:
- 调整提示词中的权重描述
- 增加示例对话
- 限制输出格式
经验分享:提示词中的禁止项(如"不要推荐生食")比鼓励项(如"多推荐蔬菜")更有效,因为AI对否定语意的理解更准确。
6. 消息推送系统集成
6.1 PushPlus配置
-
注册流程:
-
API参数说明:
json复制{ "token": "your-token", "title": "饮食推荐", "content": "内容支持HTML", "template": "html", "channel": "wechat" }
6.2 n8n中的HTTP请求配置
在AI Agent节点的Tools中添加:
-
基本配置:
- 方法:POST
- URL:https://www.pushplus.plus/send
- Headers: Content-Type: application/json
-
动态参数设置:
json复制{ "token": "your-token", "title": "$fromAI('notice_title', '消息标题,如午餐推荐')", "content": "$fromAI('notice_content', 'HTML格式内容')" }

6.3 消息内容设计
推荐消息模板:
html复制<div>
<h2>今日{meal_type}推荐</h2>
<p>主菜:{main_dish}</p>
<p>搭配:{side_dish}</p>
<p>营养建议:{nutrition_tips}</p>
<small>回复"已吃"记录用餐情况</small>
</div>
周报消息模板:
html复制<div>
<h2>{week_number}周饮食报告</h2>
<table border="1">
<tr><th>类别</th><th>次数</th></tr>
{diet_stats}
</table>
<p>健康建议:{health_advice}</p>
</div>
技术细节:使用$fromAI表达式时,若内容包含特殊字符会导致JSON解析失败,此时应改用"Using Fields Below"方式逐字段设置参数。
7. 数据存储与接口开发
7.1 饮食记录API
使用Python+Flask实现:
python复制from flask import Flask, request, jsonify
import mysql.connector
app = Flask(__name__)
# 数据库配置
db_config = {
'host': 'localhost',
'user': 'root',
'password': 'yourpassword',
'database': 'eat_what_today'
}
@app.route('/api/record-meal', methods=['POST'])
def record_meal():
data = request.json
try:
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
sql = """INSERT INTO my_dietary_record
(food_name, lunch_or_dinner, eat_date)
VALUES (%s, %s, CURDATE())"""
cursor.execute(sql, (data['food_name'], data['meal_type']))
conn.commit()
return jsonify({"status": "success"})
except Exception as e:
return jsonify({"status": "error", "message": str(e)})
finally:
if 'conn' in locals() and conn.is_connected():
conn.close()
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
7.2 n8n中的工具配置
-
HTTP Request Tool配置:
- 名称:Save the food
- URL:http://host.docker.internal:5000/api/record-meal
- 方法:POST
- Headers: Content-Type: application/json
- Body:
json复制{ "food_name": "$fromAI('food_name', '食物名称')", "meal_type": "$fromAI('meal_type', '午餐或晚餐')" }
-
触发条件提示词:
text复制
当用户表达已用餐时(如"吃了XX"、"刚吃完XX"),调用Save the food工具记录,其中: - food_name: 提取用户说的食物名称 - meal_type: 根据当前时间判断是午餐还是晚餐

7.3 数据统计功能
通过MCP执行SQL实现周报统计:
sql复制-- 本周饮食统计
SELECT
COUNT(*) AS total_meals,
SUM(CASE WHEN lunch_or_dinner='lunch' THEN 1 ELSE 0 END) AS lunch_count,
SUM(CASE WHEN food_name LIKE '%蔬菜%' THEN 1 ELSE 0 END) AS veggie_count
FROM my_dietary_record
WHERE eat_date BETWEEN DATE_SUB(CURDATE(), INTERVAL 7 DAY) AND CURDATE()
安全建议:生产环境中应为API接口添加认证,如JWT或Basic Auth,避免未授权访问。n8n的HTTP节点支持添加认证头信息。
8. 定时任务与自动化流程
8.1 餐点推荐定时器
配置两个Schedule Trigger节点:
-
午餐推荐(上午10点触发):
- Cron表达式:
0 10 * * * - 时区:Asia/Shanghai
- 输出内容:设置User Message为"现在是午餐时间,请推荐午餐"
- Cron表达式:
-
晚餐推荐(下午5点触发):
- Cron表达式:
0 17 * * * - 时区:Asia/Shanghai
- 输出内容:设置User Message为"现在是晚餐时间,请推荐晚餐"
- Cron表达式:
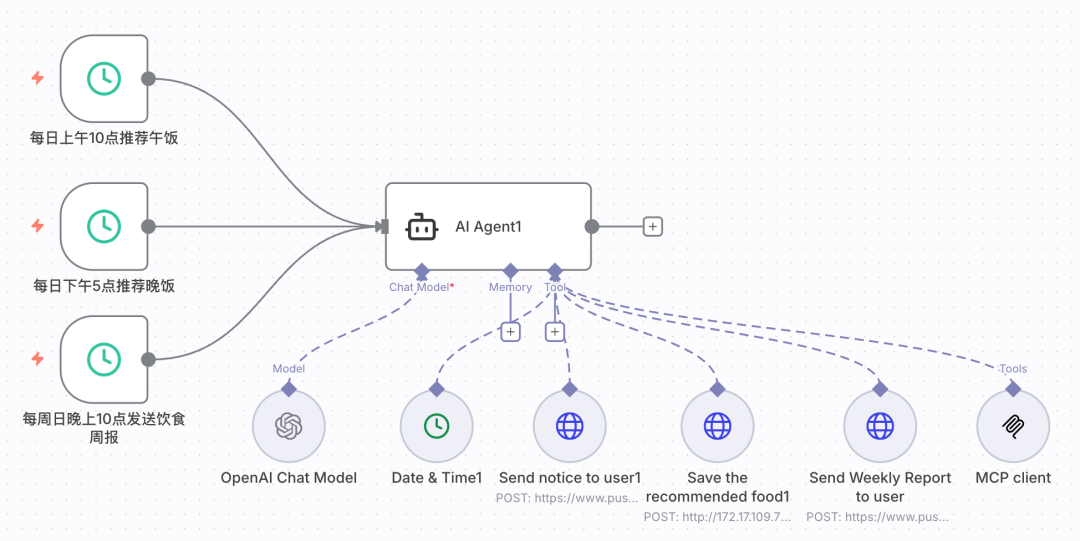
8.2 周报生成配置
周日晚上10点的周报任务:
-
Schedule Trigger配置:
- Cron表达式:
0 22 * * 0 - 时区:Asia/Shanghai
- User Message:"请生成本周饮食报告"
- Cron表达式:
-
AI Agent需要:
- 查询本周饮食记录
- 分析饮食结构
- 调用消息推送接口
8.3 工作流激活与测试
-
激活工作流:
- 保存工作流
- 点击"Active"切换按钮
- 检查右上角状态指示器
-
手动测试:
- 点击"Execute Workflow"手动触发
- 使用"Test Step"功能逐节点调试
- 查看执行历史和日志
排错技巧:如果定时任务未触发,检查服务器时间是否正确,以及n8n实例是否保持运行状态。生产环境建议使用PM2等进程管理器保活。
9. 生产环境部署指南
9.1 服务器准备
推荐配置:
- CPU:2核以上
- 内存:4GB以上
- 系统:Ubuntu 22.04 LTS
- 磁盘:50GB以上(数据库单独挂载)
必备组件:
bash复制# Docker安装
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
# Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/download/v2.24.5/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
9.2 反向代理配置
Nginx示例配置:
nginx复制server {
listen 443 ssl;
server_name your.domain.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass http://localhost:5678;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
# WebSocket支持
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
9.3 启动脚本
docker-compose.yml示例:
yaml复制version: '3'
services:
n8n:
image: n8nio/n8n
ports:
- "5678:5678"
environment:
- N8N_EDITOR_BASE_URL=https://your.domain.com
- N8N_TIMEZONE=Asia/Shanghai
volumes:
- n8n_data:/home/node/.n8n
restart: unless-stopped
extra_hosts:
- "host.docker.internal:host-gateway"
dbhub:
image: bytebase/dbhub
ports:
- "8080:8080"
environment:
- DB_CONNECTION_STRING=mysql://root:password@host.docker.internal:3306/eat_what_today
restart: unless-stopped
volumes:
n8n_data:
启动命令:
bash复制docker-compose up -d
9.4 数据迁移
-
导出本地工作流:
- 在n8n界面点击"Download"按钮
- 保存为JSON文件
-
导入生产环境:
- 登录生产环境n8n
- 创建新工作流
- 选择"Import from URL"上传文件
-
敏感信息重置:
- API Keys需要重新配置
- 数据库连接信息更新
- 消息推送token更换
部署提示:建议使用环境变量管理敏感信息,避免直接写入配置文件。n8n支持通过
process.env.VAR_NAME读取环境变量。
10. 常见问题解决方案
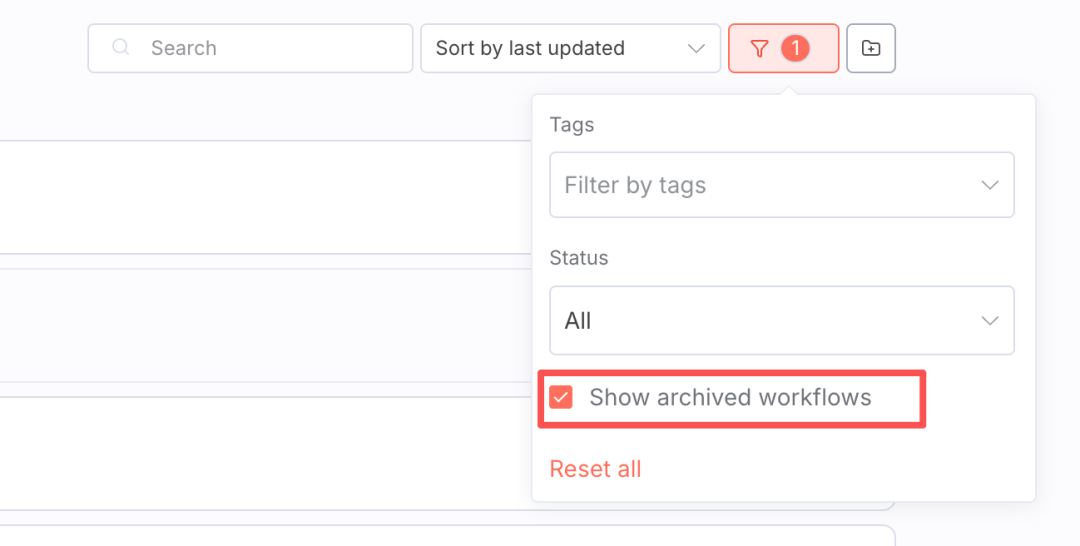
10.1 工作流相关
问题1:工作流意外归档(Archived)
- 解决方案:
- 在工作流列表页面点击Filter按钮
- 勾选"Show archived workflows"
- 找到目标工作流点击"Unarchive"
问题2:Agent节点报错"Cannot read properties of undefined"
- 解决方法:
- 导出工作流为JSON
- 修改AI Agent节点的
typeVersion为2.2 - 重新导入工作流
10.2 工具调用问题
问题3:$fromAI表达式导致JSON解析错误
- 解决方案:
- 在HTTP Request节点中
- 将"Specify Body"从"Using JSON"切换为"Using Fields Below"
- 分别设置每个字段的key和value
问题4:MCP工具调用返回空
- 排查步骤:
- 检查DBHub日志确认请求到达
- 验证数据库连接字符串
- 测试直接访问MCP端点
- 检查AI的提示词是否准确描述了工具功能
10.3 部署相关问题
问题5:线上Chat页面显示端口号
- 解决方案:
在docker-compose.yml中添加:yaml复制environment: - N8N_EDITOR_BASE_URL=https://your.domain.com
问题6:Connection Lost错误
- 解决方法:
确保Nginx配置包含WebSocket支持:nginx复制proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade";
10.4 性能优化建议
-
数据库索引优化:
sql复制ALTER TABLE my_dietary_record ADD INDEX idx_date (eat_date); ALTER TABLE candidate_food ADD INDEX idx_last_rec (last_recommended); -
n8n配置调优:
bash复制# 增加内存限制 docker run -e N8N_MEMORY=4096 ... -
请求批处理:
- 合并多个SQL查询
- 使用JOIN替代多次简单查询
- 设置合理的查询超时时间
经验总结:在实际运行中,最大的性能瓶颈通常是数据库查询。建议在复杂查询前先用EXPLAIN分析执行计划,并添加适当的索引。对于高频查询,可以考虑使用Redis缓存结果。