
1. 从算法到架构:计算寻址的本质解析
在计算机科学领域,数据寻址效率是系统性能的决定性因素。作为一名长期奋战在分布式系统一线的工程师,我深刻体会到:所有高性能存储系统的核心秘密,都藏在一个看似简单的算法题里——Two Sum。
1.1 从暴力遍历到哈希映射的范式转变
让我们回顾这个经典问题的两种解法:
暴力解法需要O(n²)时间复杂度,因为它采用最原始的"查找"思维:为了找到目标组合,必须遍历所有可能的元素对。这种模式在存储系统中的体现就是全表扫描——当我们需要定位某个数据时,不得不检查存储系统中的每一个数据项。
java复制// 典型暴力解法示例
public int[] twoSum(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] == target)
return new int[]{i, j};
}
}
return null;
}
哈希表解法则将时间复杂度降至O(n),关键在于它采用了"计算"思维:
java复制// 哈希表优化解法
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i]; // 关键计算步骤
if (map.containsKey(complement)) {
return new int[]{map.get(complement), i};
}
map.put(nums[i], i);
}
return null;
}
这个简单的优化揭示了存储系统设计的黄金法则:计算永远优于查找。当我们能够通过确定性计算直接定位数据位置时,就完全避免了昂贵的查找开销。
1.2 寻址成本的本质分析
在存储系统中,寻址成本可以量化为:
code复制总寻址成本 = 元数据访问次数 × 元数据访问延迟
+ 数据访问次数 × 数据访问延迟
其中,不同层级的访问延迟差异惊人:
| 访问类型 | 典型延迟 | 相对比例 |
|---|---|---|
| CPU寄存器访问 | 0.3 ns | 1x |
| L1缓存访问 | 1 ns | 3x |
| L2缓存访问 | 4 ns | 13x |
| 主内存访问 | 100 ns | 300x |
| SSD随机读取 | 16,000 ns | 53,000x |
| 网络往返(RTT) | 500,000 ns | 1,666,666x |
| S3 API调用 | 50,000,000 ns | 166,666,666x |
这个差异解释了为什么减少高延迟访问次数如此关键。在分布式存储场景下,即使只是多一次网络请求或磁盘IO,都可能使整体延迟增加数个数量级。
2. 经典存储系统的寻址艺术
2.1 HashMap:计算寻址的典范
HashMap之所以能实现O(1)时间复杂度,核心在于它将key的查找转化为确定性的地址计算:
- 哈希计算:通过hash(key)将任意key映射为固定长度的哈希值
- 取模定位:通过hash & (capacity-1)计算数组下标
- 冲突处理:对哈希冲突采用链表或红黑树解决
java复制// HashMap的核心寻址逻辑
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { // 关键计算步骤
// ...后续冲突处理逻辑
}
return null;
}
这种设计带来了几个重要启示:
- 连续内存布局(数组)支持直接地址计算
- 哈希函数的质量决定冲突概率
- 冲突处理策略影响最坏情况性能
2.2 HDFS:分布式场景的元数据优化
HDFS面对的是PB级数据的存储挑战,其寻址设计体现了分布式系统的独特考量:
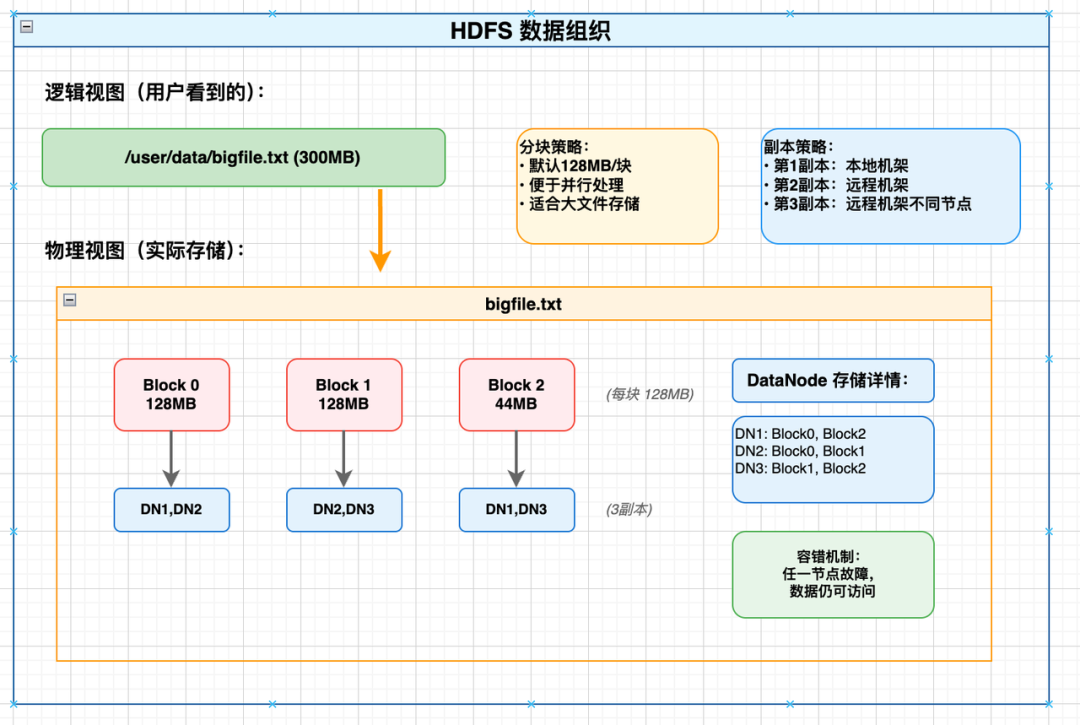
核心创新点:
- 全内存元数据:NameNode将所有元数据(文件→块映射、块→节点映射)保存在内存中的HashMap
- 分层定位:
- 第一层:路径→文件(内存HashMap)
- 第二层:文件→块列表(内存数组)
- 第三层:块→DataNode列表(内存映射)
java复制// 简化的HDFS元数据结构
class NameNode {
// 文件系统目录树(内存HashMap)
Map<String, INode> inodeMap;
// 块到DataNode的映射
Map<Block, List<DataNode>> blocksMap;
}
// 客户端读取流程
DataInputStream read(String path, long offset) {
// 1. 获取文件块列表(1次RPC)
LocatedBlocks blocks = namenode.getBlockLocations(path, offset);
// 2. 计算目标块(客户端本地计算)
Block targetBlock = calculateTargetBlock(blocks, offset);
// 3. 连接DataNode直接读取
return datanode.readBlock(targetBlock);
}
这种设计的优势在于:
- 元数据访问完全避免磁盘IO
- 块定位通过简单算术计算完成
- 数据读取直接与DataNode交互,避免NameNode瓶颈
2.3 Kafka:顺序IO与稀疏索引的完美结合
Kafka作为高吞吐消息系统,其寻址设计独具匠心:

关键设计要素:
- 分段日志:将无限增长的日志分为固定大小的Segment
- 稀疏索引:每个Segment配套一个索引文件,记录部分消息的offset→position映射
- 内存映射:索引文件通过mmap加载到内存
java复制// Kafka索引查找核心逻辑
public OffsetPosition translateOffset(long offset) {
// 1. 找到目标Segment(O(logN))
LogSegment segment = segments.floorEntry(offset);
// 2. 在索引中二分查找(O(logM))
OffsetPosition position = segment.index.lookup(offset);
// 3. 顺序扫描日志文件(平均4KB)
return segment.log.scanFrom(position);
}
这种设计的精妙之处在于:
- 将随机查找转化为顺序读取(磁盘友好)
- 稀疏索引大幅减少索引大小(内存友好)
- 分段存储支持高效过期和压缩
3. 现代存储系统的寻址演进
3.1 Milvus向量数据库:从分散存储到统一Segment
Milvus V1版本面临小文件问题:
- 每个字段独立存储
- 每个Segment产生多个binlog文件
- 查询需要合并多个字段文件
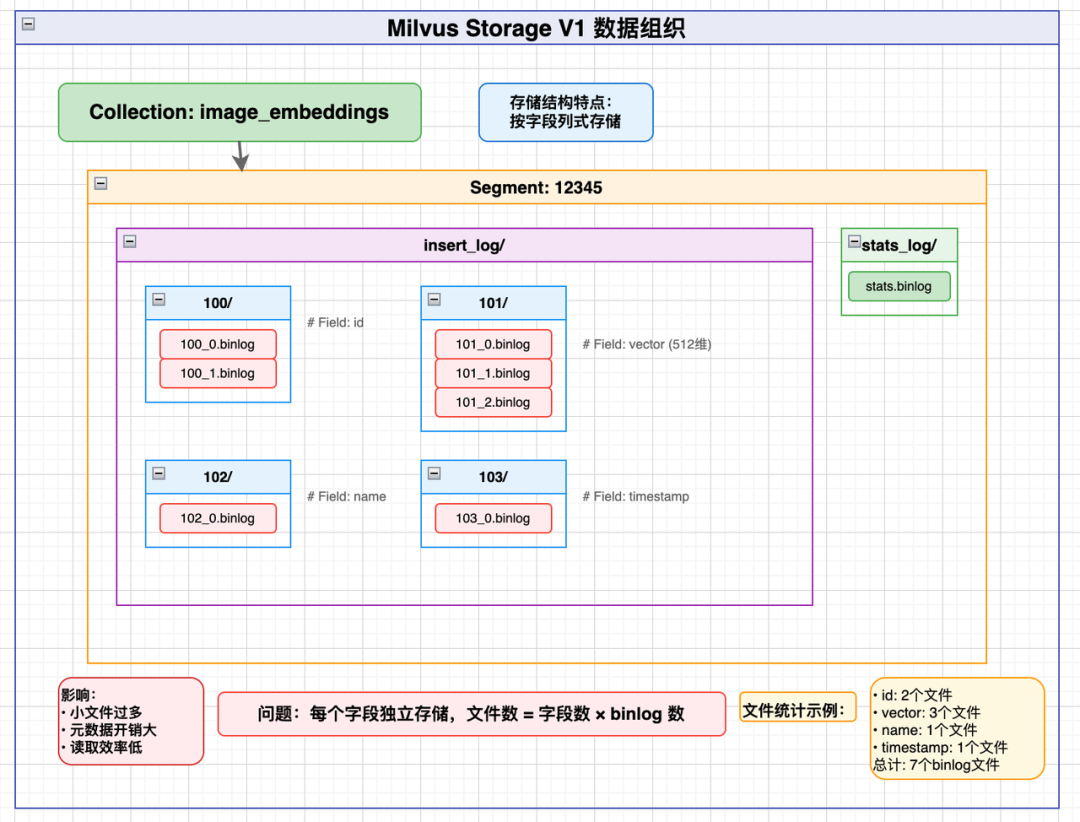
V2版本的革新:
- 按Segment整合:每个Segment所有字段存储为Parquet文件
- 列式存储:支持只读取所需列
- 大字段分离:向量等大字段独立存储
python复制# V2查询优化示例
def query(segment_id, target_id):
# 1. 读取id列(小字段文件)
id_data = read_parquet_column(f"{segment_id}/ids.parquet")
# 2. 定位目标行
row_index = find_target_row(id_data, target_id)
# 3. 读取向量列(大字段文件)
vector = read_parquet_row(f"{segment_id}/vectors.parquet", row_index)
return vector
优化效果:
- 文件数量减少10倍+
- S3 API调用减少90%+
- 查询延迟从分钟级降至秒级
3.2 Iceberg:元数据分层与统计剪枝
Iceberg解决了数据湖场景下的"文件爆炸"问题:
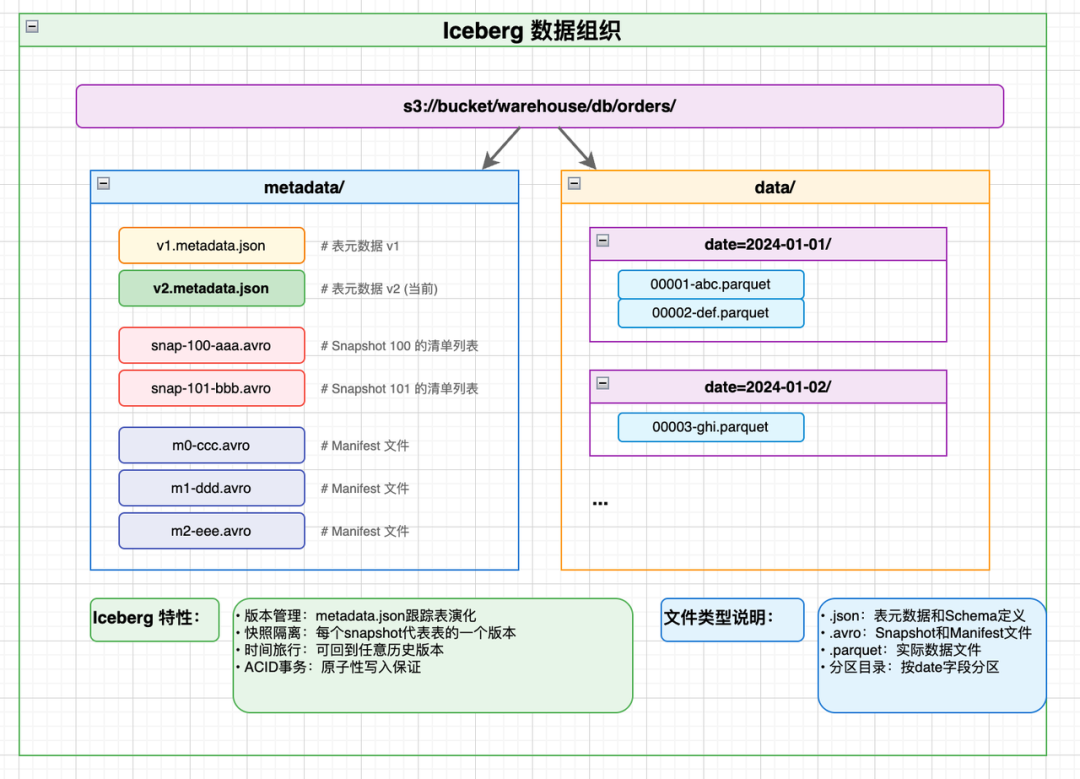
核心创新:
-
三层元数据:
- 快照(Snapshot):表当前状态
- 清单列表(Manifest List):分区统计信息
- 清单文件(Manifest):文件级统计信息
-
统计剪枝:
- 文件记录min/max值
- 分区谓词下推
- 布隆过滤器
sql复制-- 查询示例:利用统计信息剪枝
SELECT * FROM orders
WHERE date BETWEEN '2024-01-01' AND '2024-01-31'
AND amount > 1000;
执行过程:
- 读取元数据确定相关快照(1次IO)
- 使用分区统计跳过无关分区(1次IO)
- 根据min/max过滤数据文件(2次IO)
- 只读取命中文件(平均3-5次IO)
与传统方案相比,Iceberg可以将PB级表的查询从全表扫描(数千次IO)优化为仅需数次IO。
4. 寻址优化的通用原则与实践
4.1 三大核心心法
基于上述案例分析,我们可以总结出存储系统寻址优化的三大心法:
-
计算优于查找
- 用确定性计算替代不确定性查找
- 示例:哈希计算、范围分区、行号计算
-
缓存高频元数据
- 将热点元数据放在更快介质
- 示例:内存索引、mmap文件、SSD缓存
-
统计驱动剪枝
- 利用统计信息跳过无关数据
- 示例:min/max过滤、布隆过滤器、分区裁剪
4.2 性能优化矩阵
不同场景下的优化策略选择:
| 场景特征 | 适用策略 | 典型案例 |
|---|---|---|
| 点查询为主 | 哈希计算+内存索引 | HashMap、Redis |
| 范围查询 | 有序存储+稀疏索引 | Kafka、LSM-Tree |
| 海量小文件 | 文件合并+列式存储 | Milvus V2、Parquet |
| 复杂条件查询 | 统计剪枝+谓词下推 | Iceberg、Delta Lake |
| 超大规模数据 | 分层存储+冷热分离 | HDFS、S3分级存储 |
4.3 实践建议
在实际系统设计中,我总结出以下几点经验:
-
写入时多付出,读取时少付出
- 在写入阶段收集完整统计信息
- 对数据进行合理排序和分区
- 建立必要的索引结构
-
关注90%场景,而非100%情况
- 为高频查询路径特殊优化
- 接受边缘场景的性能折衷
- 保持简单性优于过度设计
-
延迟与吞吐的权衡
- 点查询优化延迟(减少IO次数)
- 分析查询优化吞吐(并行IO)
- 根据业务特点选择平衡点
-
监控驱动优化
- 建立详细的访问模式监控
- 识别真正的性能瓶颈
- 避免过早和过度优化
5. 未来演进方向
存储系统的寻址优化仍在快速发展,以下几个方向值得关注:
-
硬件加速:
- 使用GPU加速向量计算
- 利用FPGA实现定制哈希
- 持久内存(PMem)的应用
-
机器学习增强:
- 学习型索引结构
- 查询模式预测
- 自动数据布局优化
-
新存储介质:
- 计算存储一体化
- 存算分离架构优化
- 异构存储智能分层
-
标准化接口:
- 通用数据定位协议
- 跨系统元数据交换
- 统一的数据跳过标准
在这个数据爆炸的时代,寻址效率仍然是存储系统设计的核心挑战。从Two Sum算法到现代分布式系统,计算优于查找的基本原则始终未变,但实现方式在不断创新。作为工程师,我们需要深入理解这些底层原理,才能设计出适应未来需求的高效存储架构。