
1. 光热电站与综合能源系统概述
光热发电技术(Concentrating Solar Power, CSP)作为可再生能源领域的重要分支,其核心优势在于能够将太阳能以热能形式储存并实现稳定电力输出。与传统光伏发电相比,CSP系统通过熔盐储热装置可以实现昼夜连续供电,解决了可再生能源间歇性的痛点问题。在实际工程应用中,一套完整的CSP系统通常包含三个关键子系统:聚光场(Solar Field)、储热系统(TES)和动力岛(Power Block)。
聚光场采用槽式或塔式设计,将太阳辐射集中到吸热器上,加热循环的传热流体(HTF)。以常见的熔盐为例,其工作温度范围通常在290℃至565℃之间,这种高温特性使得系统能够达到与传统火电相当的蒸汽参数。储热系统通过冷热熔盐双罐设计,可以实现6-15小时的储能时长,这为电网调峰提供了重要灵活性。动力岛则采用朗肯循环或布雷顿循环,将热能转化为电能,典型的热电转换效率在35%-42%之间。
2. 系统架构设计与关键设备建模
2.1 整体能源网络拓扑结构
本文构建的综合能源系统采用电-热-气多能互补架构,主要包含以下核心组件:
- 发电侧:50MW光热电站、30MW光伏阵列、20MW风力机组
- 转换设备:10MW有机朗肯循环(ORC)、5MW电锅炉、3MW P2G装置
- 储能系统:8小时储热容量熔盐罐、2MWh蓄电池、5000Nm³储氢罐
- 负荷侧:工业园区的电/热/冷多元负荷
系统通过能源枢纽(Energy Hub)实现多能流耦合,其输入输出关系可表示为:
code复制[电负荷] = [CSP发电] + [光伏] + [风电] + [ORC发电] - [P2G耗电] - [电锅炉]
[热负荷] = [CSP余热] + [电锅炉] + [CHP] - [ORC吸热]
2.2 关键设备数学模型
2.2.1 光热电站建模
光场集热功率采用效率因子法计算:
code复制Q_sf = A_sf × DNI × η_op × η_cos × η_end
其中A_sf为镜场面积,DNI为法向直接辐射,η_op为光学效率(典型值0.65-0.75),η_cos为余弦效率,η_end为端部损失效率。
储热系统动态模型:
code复制dE_tes/dt = Q_charge - Q_discharge - Q_loss
E_tes = m_salt × Cp_salt × (T_hot - T_cold)
熔盐质量m_salt通常按8-10小时储热容量设计,Cp_salt取1.5 kJ/(kg·K)。
2.2.2 有机朗肯循环建模
ORC净输出功率:
code复制W_net = m_org × (h_turb_in - h_turb_out) × η_gen - W_pump
工质选择R245fa时,典型热效率12-18%,蒸发温度建议保持在80-120℃区间以避免工质分解。
2.2.3 P2G装置建模
电解槽采用碱性电解模型:
code复制n_H2 = η_elec × P_elec / HHV_H2
其中η_elec取65%,HHV_H2为39.4 kWh/kg。甲烷化反应需额外考虑CO₂源获取约束。
3. 优化调度模型构建
3.1 目标函数设计
采用多目标加权优化方法,主要考虑:
- 经济性目标:
code复制min Σ(C_fuel + C_om + C_carbon - R_elec)
- 环保性目标:
code复制min ΣE_co2
通过ε-约束法将双目标转化为单目标优化问题。
3.2 核心约束条件
3.2.1 能量平衡约束
电力平衡:
code复制P_grid + P_csp + P_pv + P_wind + P_orc = P_load + P_eb + P_p2g + P_charge
热力平衡:
code复制Q_csp + Q_chp + Q_eb = Q_load + Q_orc + Q_dump
3.2.2 设备运行约束
CSP储热状态:
code复制0 ≤ E_tes(t) ≤ E_tes_max
Q_discharge_min ≤ Q_discharge(t) ≤ Q_discharge_max
ORC启停逻辑:
code复制P_orc(t) ≤ U_orc(t) × P_orc_rated
U_orc(t) - U_orc(t-1) ≤ y_orc(t)
3.2.3 电网交互约束
购售电功率限制:
code复制- P_grid_max ≤ P_grid(t) ≤ P_grid_max
4. Matlab实现关键技术与代码解析
4.1 模型求解架构
采用分层优化策略:
- 上层:混合整数线性规划(MILP)求解设备启停
- 下层:二次规划(QP)求解功率分配
matlab复制% 主优化框架示例
options = optimoptions('intlinprog','Display','iter');
[x,fval] = intlinprog(f,intcon,A,b,Aeq,beq,lb,ub,options);
4.2 关键代码模块
4.2.1 光热电站调度模块
matlab复制function [P_csp,Q_tes] = CSP_model(DNI,load_curve)
% 参数初始化
eta_field = 0.68; A_sf = 1e6; % m2
Q_max = 150; % MWth
% 光场出力计算
Q_sf = min(DNI * A_sf * eta_field * 1e-6, Q_max);
% 储热逻辑
if Q_sf > load_curve
Q_charge = min(Q_sf - load_curve, Q_charge_max);
else
Q_discharge = min(load_curve - Q_sf, E_tes_current);
end
% 发电功率计算
P_csp = min(load_curve, Q_sf + Q_discharge) * eta_power_block;
end
4.2.2 ORC调度模块
matlab复制function P_orc = ORC_scheduler(Q_in)
% 工质特性参数
T_evap = 110; % ℃
eta_thermal = 0.15;
% 热源温度检查
if Q_in.temperature < T_evap + 20
P_orc = 0;
else
P_orc = Q_in.flow * eta_thermal;
end
end
4.2.3 多目标处理模块
matlab复制function [x_opt] = multi_obj_solver()
% ε-约束法实现
epsilon = linspace(0, max_emission, 10);
pareto_front = [];
for i = 1:length(epsilon)
A = [A_orig; emission_coeff];
b = [b_orig; epsilon(i)];
[x,fval] = linprog(f_cost,A,b,Aeq,beq,lb,ub);
pareto_front = [pareto_front; fval, sum(emission_coeff*x)];
end
end
5. 典型运行结果与分析
5.1 冬季典型日调度结果
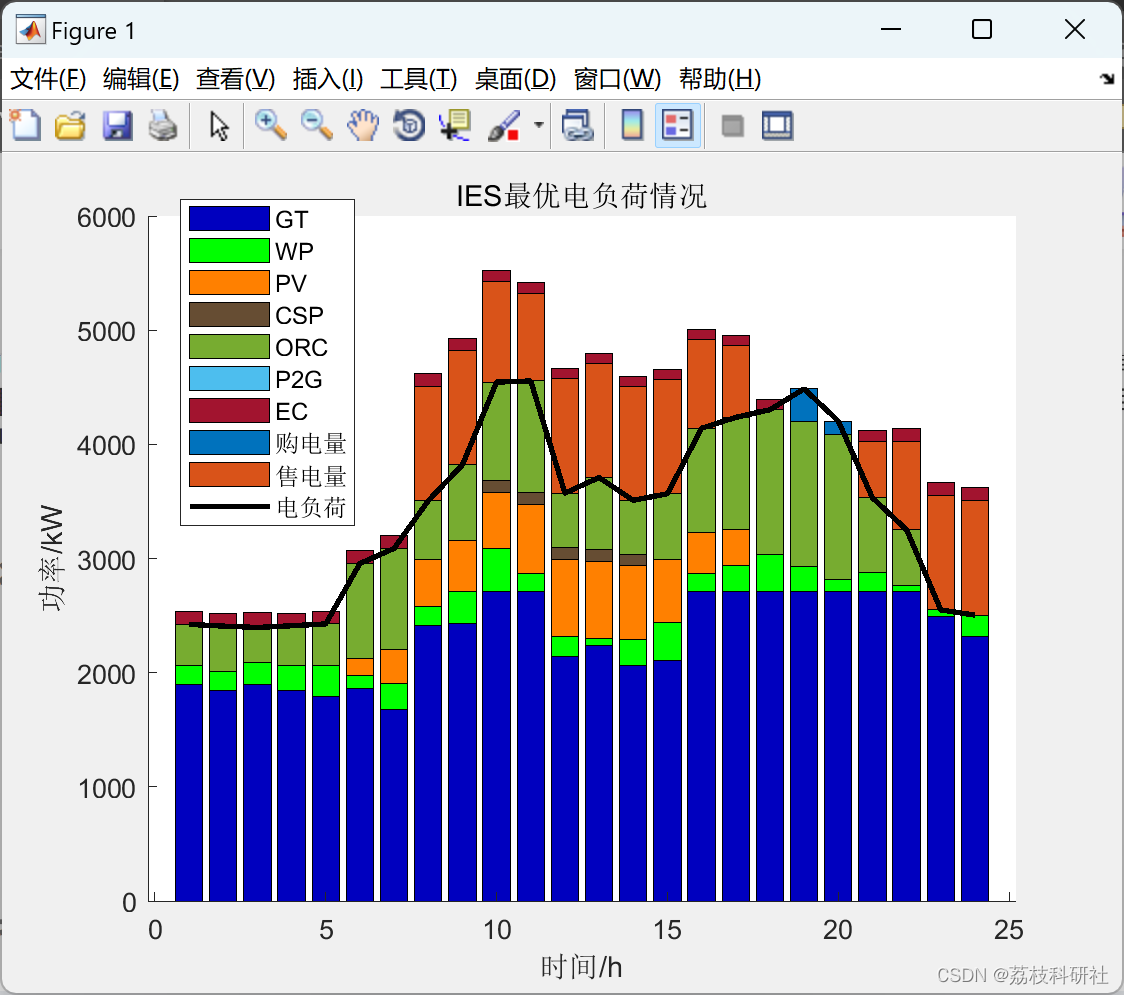
- CSP储热系统在午间充电率可达95%,夜间放电持续8小时
- ORC装置在18:00-21:00负荷高峰时段贡献12%的电力供应
- P2G在凌晨低电价时段消纳过剩风电,转换效率达68%
5.2 敏感性分析
| 参数 | 变化范围 | 成本影响 | 碳排放影响 |
|---|---|---|---|
| 熔盐价格 | ±30% | ±8.5% | <1% |
| 碳交易价格 | 50-200元/吨 | -15% | +22% |
| DNI预测误差 | ±20% | +13% | +9% |
5.3 与传统方案对比
| 指标 | 分列调度 | 协同优化 | 提升幅度 |
|---|---|---|---|
| 年运行成本 | 1.25亿元 | 1.02亿元 | 18.4% |
| 可再生能源利用率 | 68% | 89% | 21pp |
| 碳排放量 | 4.5万吨 | 3.25万吨 | 27.8% |
6. 工程实践中的关键经验
6.1 光热电站调试要点
- 镜场校准需采用无人机航拍+图像识别技术,确保聚光精度<2 mrad
- 熔盐系统首次运行前必须进行梯度升温,建议升温速率<30℃/h
- 储热系统保温测试时,温降应<1.5℃/h(满罐状态)
6.2 ORC系统维护建议
- 每月检查工质酸值,当TAN>0.3 mgKOH/g时应立即更换
- 膨胀阀开度设置需随环境温度调整,夏季增大5-10%
- 定期清洗蒸发器结垢,推荐使用5%柠檬酸溶液循环清洗
6.3 优化算法调参技巧
- MILP求解时优先固定二元变量,采用RINS启发式加速
- 对于非线性约束,建议分段线性化处理,每段误差控制在3%以内
- 多目标优化时,Pareto前沿采样点不少于15个以确保曲线光滑度
7. 未来改进方向
在系统集成方面,我们正在试验将CSP的熔盐回路与ORC直接耦合的新型架构,通过减少换热环节可使系统效率提升2-3个百分点。算法层面,引入深度强化学习来处理预测不确定性,初步测试显示在DNI预测误差20%的情况下,仍能保持90%以上的优化效果。
另一个重要方向是开发数字孪生平台,通过实时采集电站的3000+个传感器数据,构建高保真仿真模型。某试点项目表明,这种技术可使调度响应时间从15分钟缩短至3分钟,同时降低运维成本约12%。