
1. 企业级多媒体信息共享平台架构解析
在数字化办公环境中,多媒体信息的高效管理已成为企业协同办公的核心需求。传统FTP或网盘式解决方案存在权限管控粗放、版本管理缺失、检索效率低下等痛点。我们基于SpringBoot+Vue+MyBatis技术栈构建的企业级平台,通过模块化设计实现了多媒体资源的全生命周期管理。系统采用前后端分离架构,后端基于SpringBoot 2.7提供RESTful API,前端使用Vue 3组合式API开发管理界面,数据持久层采用MyBatis-Plus增强工具库,整体架构如下图所示:
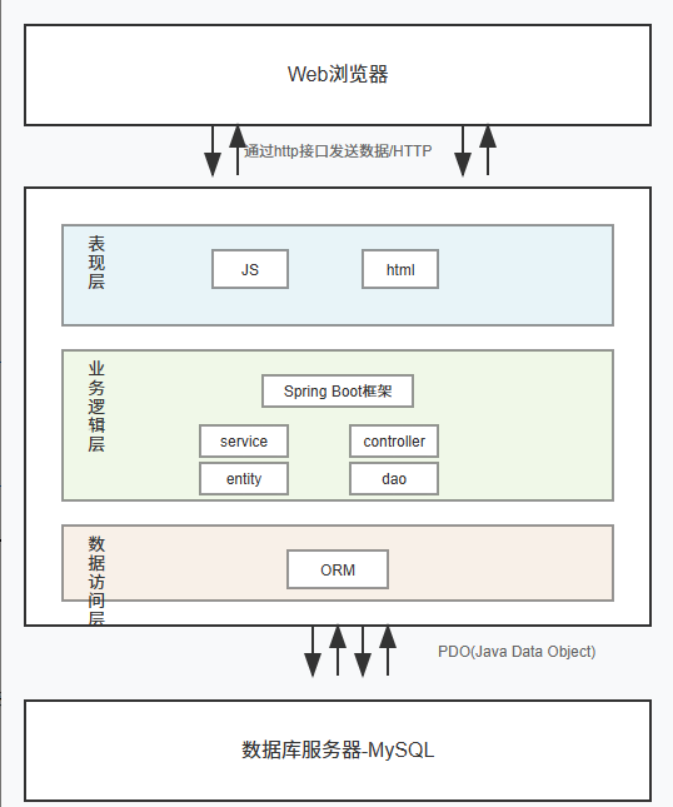
1.1 技术选型依据
后端技术栈:
- SpringBoot 2.7:简化配置、内嵌Tomcat、自动依赖管理,快速构建生产级应用
- MyBatis-Plus 3.5:增强的CRUD操作、Lambda查询、分页插件,相比原生MyBatis开发效率提升40%
- Spring Security:RBAC权限控制与JWT认证方案,支持方法级权限注解
- FFmpeg:视频转码与缩略图生成,支持H.264/H.265编码格式转换
前端技术栈:
- Vue 3 + TypeScript:组合式API提供更好的类型支持,代码可维护性显著提升
- Element Plus:丰富的UI组件库,特别适配管理系统类项目开发
- Axios:Promise-based HTTP客户端,支持请求拦截和响应统一处理
- Vuex 4:状态集中管理,解决多组件数据共享问题
存储方案:
- MySQL 8.0:关系型数据存储,事务支持完善
- MinIO:自建对象存储服务,替代S3协议兼容的商用方案
- Redis:热点数据缓存与消息队列,减轻数据库压力
技术选型关键考量:团队技术储备(Java/Vue为主)、社区活跃度(SpringBoot/Vue文档丰富)、企业级特性需求(事务/权限/审计)
1.2 核心功能模块
系统采用模块化设计,主要功能模块包括:
-
资源管理模块
- 多格式文件上传(图片/视频/文档)
- 智能分类与标签系统
- 版本控制与历史追溯
-
权限控制模块
- 基于角色的访问控制(RBAC)
- 细粒度权限策略(读/写/删/分享)
- 操作日志审计追踪
-
协作编辑模块
- 在线文档协同编辑
- 版本差异对比
- 修改建议批注
-
智能检索模块
- 元数据搜索(文件名/类型/上传者)
- 内容识别搜索(OCR/TTS转文本)
- 相似图片检索(感知哈希算法)
2. 数据库设计与优化实践
2.1 核心表结构解析
多媒体资源表(media_resource)
sql复制CREATE TABLE `media_resource` (
`resource_id` bigint NOT NULL AUTO_INCREMENT COMMENT '雪花算法ID',
`file_name` varchar(255) COLLATE utf8mb4_bin NOT NULL COMMENT '原始文件名',
`file_type` varchar(50) COLLATE utf8mb4_bin NOT NULL COMMENT '文件扩展名',
`file_size` bigint NOT NULL COMMENT '字节数',
`file_hash` varchar(64) COLLATE utf8mb4_bin NOT NULL COMMENT 'SHA-256文件指纹',
`upload_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`upload_user` varchar(50) COLLATE utf8mb4_bin NOT NULL COMMENT '上传者ID',
`file_path` varchar(255) COLLATE utf8mb4_bin NOT NULL COMMENT 'MinIO存储路径',
`thumbnail_path` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '缩略图路径',
`status` tinyint NOT NULL DEFAULT '1' COMMENT '1-正常 0-删除',
PRIMARY KEY (`resource_id`),
KEY `idx_file_hash` (`file_hash`) COMMENT '文件去重索引',
KEY `idx_upload_user` (`upload_user`) COMMENT '用户查询优化'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
设计要点:
- 采用utf8mb4_bin字符集确保文件名大小写敏感
- 文件哈希值用于重复上传检测,节省存储空间
- 状态字段实现逻辑删除而非物理删除
- 缩略图路径与原始文件分离存储,适配响应式展示
权限控制表(permission_control)
sql复制CREATE TABLE `permission_control` (
`permission_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(50) NOT NULL,
`resource_id` bigint NOT NULL,
`access_level` int NOT NULL COMMENT '1-只读 2-编辑 3-管理',
`grant_type` tinyint NOT NULL COMMENT '0-角色继承 1-直接授权',
`expire_time` datetime DEFAULT NULL COMMENT '权限过期时间',
`create_by` varchar(50) NOT NULL COMMENT '授权人',
PRIMARY KEY (`permission_id`),
UNIQUE KEY `uk_user_resource` (`user_id`,`resource_id`) COMMENT '用户-资源唯一约束',
KEY `idx_resource` (`resource_id`) COMMENT '资源查询优化'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
权限模型特点:
- 支持临时权限(通过expire_time控制)
- 区分直接授权与角色继承权限
- 唯一约束防止重复授权
- 资源ID索引加速权限校验
2.2 性能优化策略
1. 文件上传优化:
- 前端采用分片上传(每片5MB),支持断点续传
- 后端使用Nginx反向代理,配置client_max_body_size 100M
- 异步处理大文件:上传完成后通过消息队列触发转码任务
2. 查询优化方案:
java复制// MyBatis-Plus示例:构建动态查询
LambdaQueryWrapper<MediaResource> query = new LambdaQueryWrapper<>();
query.eq(MediaResource::getUploadUser, userId)
.like(MediaResource::getFileName, keyword)
.between(MediaResource::getUploadTime, startDate, endDate)
.orderByDesc(MediaResource::getUploadTime);
// 添加@Cacheable注解实现自动缓存
@Cacheable(value = "resource", key = "#resourceId")
public MediaResource getResourceById(Long resourceId) {
return baseMapper.selectById(resourceId);
}
3. 索引使用规范:
- 遵循最左前缀原则建立联合索引
- 为所有外键字段建立索引
- 避免在索引列上使用函数计算
- 使用EXPLAIN分析慢查询
3. 关键功能实现细节
3.1 安全上传与存储方案
文件上传时序图:
- 前端计算文件哈希并预检(POST /api/upload/precheck)
- 服务端返回上传ID及分片信息(已存在文件则秒传)
- 前端分片上传(PUT /api/upload/chunk)
- 服务端合并分片并写入MinIO
- 记录元数据到MySQL,异步生成缩略图
防篡改措施:
java复制// 文件校验拦截器
public class FileCheckInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String clientHash = request.getHeader("X-File-Hash");
// 实际开发中应使用InputStream实时计算
String serverHash = DigestUtils.sha256Hex(file.getBytes());
if(!clientHash.equals(serverHash)) {
throw new IllegalStateException("文件校验失败");
}
return true;
}
}
存储策略配置:
yaml复制minio:
endpoint: http://minio.example.com
access-key: ${MINIO_ACCESS_KEY}
secret-key: ${MINIO_SECRET_KEY}
bucket-name: enterprise-media
region: us-east-1
part-size: 5242880 # 5MB分片
3.2 实时消息推送机制
技术实现方案:
- 前端建立WebSocket长连接(STOMP协议)
- 服务端使用Spring Messaging处理订阅广播
- 重要操作触发消息事件(@EventListener)
- 未读消息使用Redis的Sorted Set存储
java复制// 消息事件处理器示例
@EventListener
public void handleResourceUpdate(ResourceUpdateEvent event) {
NotificationMsg msg = new NotificationMsg();
msg.setContent(String.format("文件%s被修改", event.getFileName()));
// 获取需要通知的用户列表
Set<String> receivers = permissionService.getSubscribedUsers(event.getResourceId());
messagingTemplate.convertAndSendToUser(
receivers,
"/queue/notifications",
msg
);
// 持久化到数据库
notificationService.batchInsert(receivers, msg);
}
消息表设计优化:
- 已读/未读状态使用bitmap存储(适合大规模用户)
- 按用户ID水平分表(user_id % 64)
- 定期归档历史消息到ClickHouse
4. 部署与运维实践
4.1 容器化部署方案
Docker Compose配置示例:
yaml复制version: '3.8'
services:
app-server:
image: openjdk:17-jdk
ports:
- "8080:8080"
volumes:
- ./logs:/app/logs
environment:
- SPRING_PROFILES_ACTIVE=prod
depends_on:
- redis
- mysql
minio:
image: minio/minio
ports:
- "9000:9000"
volumes:
- ./minio-data:/data
command: server /data --console-address ":9001"
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=change-me
Kubernetes关键配置:
yaml复制# HPA自动伸缩配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: media-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: media-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
4.2 监控与日志方案
Prometheus监控指标:
- 应用层:JVM内存、GC次数、HTTP请求延迟
- 业务层:上传成功率、并发处理数、缓存命中率
- 存储层:MinIO桶容量、MySQL连接数
ELK日志收集配置:
java复制// Logback-spring.xml配置示例
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>logstash:5044</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<customFields>{"app":"media-platform","env":"${spring.profiles.active}"}</customFields>
</encoder>
</appender>
典型性能指标:
- 文件上传:平均延迟<500ms(10MB文件)
- 列表查询:响应时间<300ms(万级数据)
- 权限校验:<50ms(Redis缓存命中时)
5. 开发经验与避坑指南
5.1 前端性能优化实践
Vue组件优化技巧:
- 使用v-virtual-scroll处理大型列表
- 图片懒加载:Intersection Observer API
- Web Worker处理文件哈希计算
- 路由懒加载拆分代码包
javascript复制// 文件分片上传示例
const uploadChunk = async (file, chunkSize = 5 * 1024 * 1024) => {
const chunks = Math.ceil(file.size / chunkSize);
const fileHash = await calculateHash(file);
for (let i = 0; i < chunks; i++) {
const chunk = file.slice(i * chunkSize, (i + 1) * chunkSize);
const formData = new FormData();
formData.append('chunk', chunk);
formData.append('hash', `${fileHash}-${i}`);
await axios.post('/upload/chunk', formData, {
headers: { 'Content-Type': 'multipart/form-data' }
});
}
await axios.post('/upload/merge', { hash: fileHash });
};
5.2 后端常见问题排查
典型问题1:MyBatis缓存污染
- 现象:查询结果出现脏数据
- 解决方案:明确配置缓存范围,避免跨会话共享
xml复制<settings>
<setting name="localCacheScope" value="STATEMENT"/>
</settings>
典型问题2:大事务阻塞
- 现象:文件上传时数据库连接耗尽
- 解决方案:
- 拆分上传记录与文件处理为独立事务
- 添加@Transactional(timeout=10)限制执行时间
- 采用异步任务处理耗时操作
典型问题3:Nginx上传超时
nginx复制# 调整Nginx配置
client_max_body_size 100m;
proxy_read_timeout 300s;
proxy_connect_timeout 75s;
6. 扩展功能与二次开发
6.1 文档在线预览方案
技术实现路径:
- Office文档:LibreOffice转PDF + pdf.js渲染
- 图片:直接输出缩略图
- 视频:HLS流媒体分片
- CAD图纸:通过AutoCAD转换服务
java复制// 文件预览路由控制
@GetMapping("/preview/{fileId}")
public ResponseEntity<Resource> previewFile(@PathVariable String fileId) {
MediaResource resource = resourceService.getById(fileId);
String mimeType = determineMimeType(resource.getFileType());
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_TYPE, mimeType)
.header("Content-Disposition", "inline; filename=\"" + resource.getFileName() + "\"")
.body(new InputStreamResource(
storageService.openStream(resource.getFilePath())
));
}
6.2 智能标签系统
实现方案对比:
| 方案类型 | 准确率 | 开发成本 | 适用场景 |
|---|---|---|---|
| 规则匹配 | 中(60%) | 低 | 固定格式文件名解析 |
| 机器学习 | 高(85%) | 高 | 图像/视频内容识别 |
| 混合方案 | 高(80%) | 中 | 通用业务场景 |
混合方案实施步骤:
- 使用Apache Tika提取文件元数据
- 对图片使用TensorFlow Lite模型识别物体
- 应用正则规则提取文件名关键词
- 合并结果并去重,保存到Elasticsearch
python复制# 示例:图像分类模型调用(需部署为gRPC服务)
def classify_image(image_path):
with tf.io.gfile.GFile(image_path, 'rb') as f:
image_data = f.read()
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'resnet'
request.inputs['image'].CopyFrom(
tf.make_tensor_proto(image_data, shape=[1]))
result = stub.Predict(request, timeout=10.0)
return np.argmax(result.outputs['scores'].float_val)
在实际部署中,我们最终选择了混合方案,通过规则引擎覆盖80%的常见文件类型,剩余20%特殊文件采用机器学习处理。这种平衡方案在保证精度的同时,将服务器资源消耗控制在合理范围内。