
1. 外卖特征平台建设背景与挑战
外卖业务作为本地生活服务的重要场景,其算法策略需要平衡用户、商家和平台三方的利益诉求。用户希望获得精准的推荐结果,商家追求最大化的曝光和转化,而平台则需要实现营收增长。这种复杂的三角关系,使得外卖场景下的特征工程面临独特挑战。
随着业务规模扩大,美团外卖平台日均处理特征数据已达几十TB级别,特征维度近50种,日调度任务数百个。这种量级的数据处理,对特征平台提出了三大核心要求:
- 快速迭代能力:新特征从开发到上线需要缩短周期
- 高效计算能力:千亿级特征数据的实时处理性能
- 配置化样本生成:降低算法同学使用门槛
实践经验:在特征平台建设初期,我们曾遇到特征上线周期长达2周的情况。通过后续的平台化改造,现在新特征的平均上线时间已缩短到3天内,紧急需求甚至可以实现当日上线。
2. 特征平台架构演进
2.1. 初始架构的局限性
早期特征处理框架由三部分组成:
- 特征统计:基于Hive的批处理计算
- 特征推送:Hive到KV存储的数据同步
- 特征获取:在线服务从KV读取特征
这套框架在业务初期表现良好,但随着业务复杂度提升,逐渐暴露出三个关键问题:
- 迭代成本高:新特征需要同时修改离线和在线代码
- 复用困难:跨业务线特征共享机制缺失
- 管理缺失:缺乏特征全生命周期的追踪能力
2.2. 新一代平台架构设计
新平台采用三层架构设计,实现了特征处理的完整闭环:
2.2.1. 离线样本生成层
- 支持配置化的训练样本生产
- 提供特征统计分析能力
- 实现TFRecord等格式转换
2.2.2. 近线特征生产层
- 特征语义化抽取
- 多租户资源隔离
- 智能任务调度
2.2.3. 在线特征服务层
- 高性能特征获取
- 动态特征计算
- 多版本管理
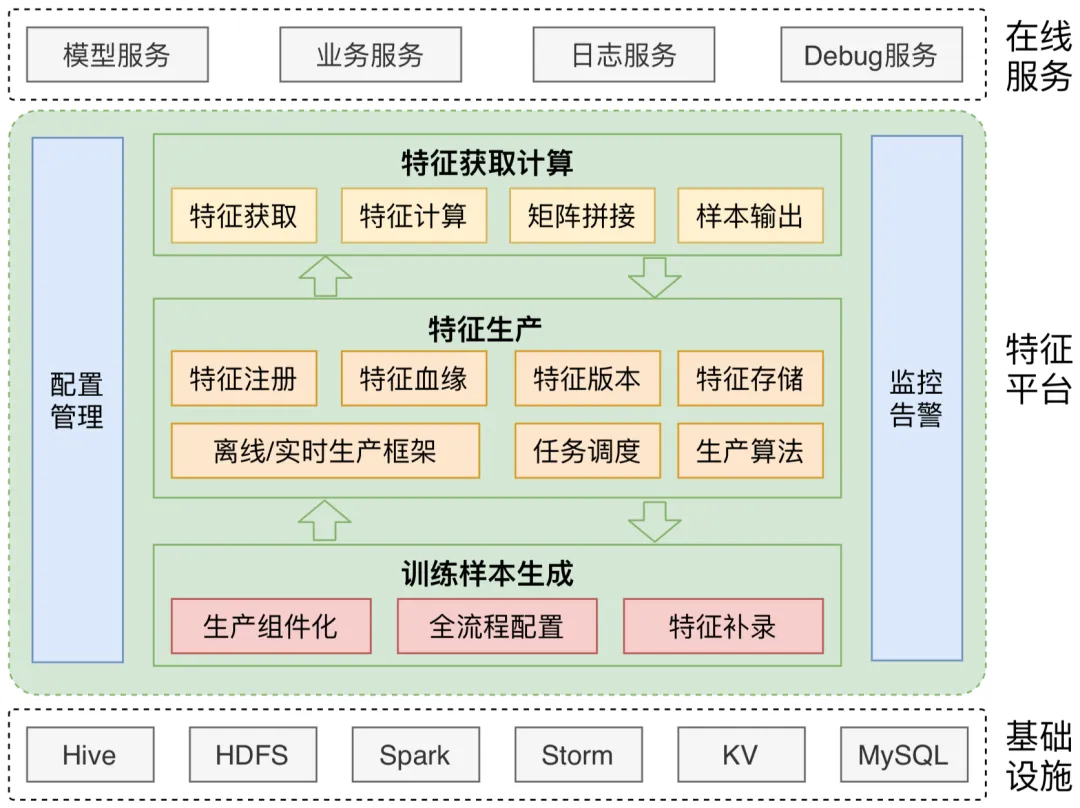
技术选型考量:
- 存储层选用HBase+Redis组合,平衡吞吐与延迟
- 计算引擎采用Spark+Flink,满足批流一体需求
- 序列化协议选用Protobuf,优化网络传输效率
3. 核心技术创新点
3.1. 特征语义化机制
传统特征拉取方式存在两个极端:
- 按特征拉取:任务数量爆炸
- 按表拉取:逻辑耦合严重
我们创新性地提出"特征语义"概念,将特征抽取过程抽象为:
sql复制SELECT {key}, {features}
FROM {table}
WHERE {condition}
GROUP BY {dimension}
通过语义自动合并技术,相同查询条件的特征可以合并处理。例如:
sql复制-- 原始两个特征
SELECT user_id, COUNT(order_id) AS 7d_order_cnt
FROM orders
WHERE dt BETWEEN '20230101' AND '20230107'
GROUP BY user_id
SELECT user_id, SUM(amount) AS 7d_order_amount
FROM orders
WHERE dt BETWEEN '20230101' AND '20230107'
GROUP BY user_id
-- 合并后
SELECT user_id, COUNT(order_id) AS 7d_order_cnt, SUM(amount) AS 7d_order_amount
FROM orders
WHERE dt BETWEEN '20230101' AND '20230107'
GROUP BY user_id
这种优化使特征拉取任务数减少40%,资源消耗降低35%。
3.2. 智能任务调度系统
针对特征同步的三大痛点:
- 特征重复拉取
- 缺乏全局调度
- 存储方式僵化
我们设计了多级调度架构:
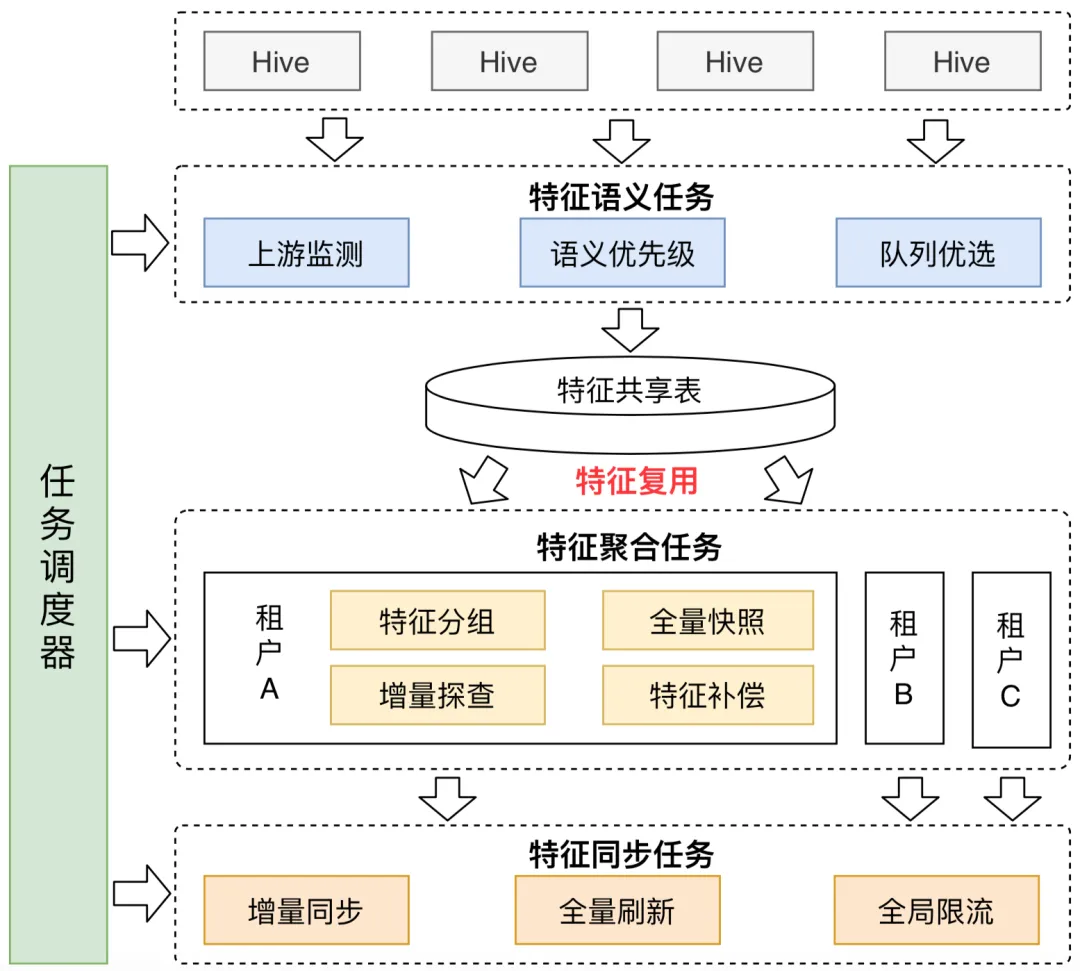
关键创新点:
- 语义优先级队列:重要特征优先处理
- 资源感知调度:动态选择最优队列
- 增量同步机制:仅同步变更特征
- 跨天补偿:保证数据连续性
实际运行效果:
- 特征同步时效性提升60%
- 集群资源利用率提高25%
- 失败重试成功率提升至99.9%
3.3. 动态序列化方案
传统Protobuf方案存在JAR包依赖问题,我们创新性地实现动态序列化机制:
- 元数据驱动:通过特征元数据描述字段类型
- 动态编解码:运行时根据元数据解析特征
- 版本兼容:支持新旧特征格式共存
序列化性能对比:
| 方案 | 吞吐量(QPS) | 延迟(ms) | 存储体积 |
|---|---|---|---|
| JSON | 12,000 | 2.5 | 100% |
| 静态Protobuf | 45,000 | 0.8 | 60% |
| 动态Protobuf | 42,000 | 0.9 | 62% |
虽然动态方案性能略低于静态方案,但换来了极大的灵活性,新特征上线无需发版。
3.4. 特征分组优化
针对KV存储的大Value问题,我们设计智能分组策略:
- 业务分组:专属特征独立存储
- 公共分组:共享特征统一管理
- 动态迁移:根据访问模式调整
分组合并算法伪代码:
python复制def merge_groups(feature_list):
# 构建特征-分组关系图
graph = build_feature_graph(feature_list)
# 寻找连通分量
components = find_connected_components(graph)
# 生成最优分组方案
return optimize_grouping(components)
优化效果:
- KV读取性能提升3倍
- 网络带宽消耗降低50%
- 集群稳定性显著提高
4. 特征计算与样本构建
4.1. MFDL语言设计
模型特征描述语言(MFDL)的创新点:
- 计算与转换分离:
yaml复制feature_calculation:
- expression: "user_click_cnt / (user_impression_cnt + 1)"
output: "ctr"
feature_transformation:
- type: "normalization"
input: "ctr"
params: {"min": 0, "max": 1}
- 多范式支持:
- 数值特征:算术运算
- 分类特征:OneHot编码
- 序列特征:Embedding
- 热更新机制:配置变更实时生效
4.2. 一致性样本构建
解决离在线不一致的方案:
- 特征快照:在线服务实时dump特征
- 统一算子库:线上线下共用相同代码
- 自动化校验:特征值差异检测
样本构建流水线示例:
code复制1. 获取Label数据(Hive)
2. 关联特征快照(HBase)
3. 应用MFDL转换
4. 生成TFRecord
5. 输出统计报告
5. 平台赋能业务实践
5.1. 特征复用体系
我们建立了特征价值评估模型:
code复制特征评分 = 0.4*复用度 + 0.3*效果增益 + 0.2*数据质量 + 0.1*时效性
通过特征市场促进复用:
- 特征检索:多维筛选
- 特征画像:可视化分析
- 效果追踪:AB测试反馈
5.2. 典型业务场景
-
搜索排序:
- 特征类型:CTR、CVR、价格敏感度
- 实时特征:搜索词与商家匹配度
-
推荐系统:
- 用户画像:消费能力、口味偏好
- 上下文特征:时间、地点、天气
-
广告投放:
- 商家质量分
- 竞价策略特征
6. 未来演进方向
- 特征版本治理:自动化特征下线
- 联邦学习支持:安全特征共享
- AutoFeature:自动特征生成
- 在线学习:实时特征更新
经过两年多的实践,美团外卖特征平台日均处理特征数据超50TB,支持数百个业务场景,特征迭代效率提升5倍,成为外卖算法体系的核心基础设施。这个建设过程给我们的启示是:好的特征平台不仅要解决技术问题,更要深入业务场景,建立从数据到价值的完整闭环。