
1. 项目背景与核心问题
工业用电成本居高不下一直是困扰制造业企业的痛点问题。以江苏省某工业园区为例,三家典型工业用户(金属加工、纺织印染、食品制造)的月度电费支出占到总运营成本的35%-45%。传统解决方案是各自配置独立储能系统,但存在投资回报周期长、容量利用率低等问题。
共享储能电站的商业模式应运而生——就像共享充电宝一样,多个用户可以按需使用同一座储能电站的资源。但与简单的设备共享不同,电力储能涉及更复杂的优化问题:
- 容量配置与运行调度的耦合:电站建设容量直接影响调度灵活性,而调度策略又反过来影响容量需求
- 多用户利益协调:需要公平分配各时间段的充放电权限
- 非线性约束处理:充放电状态互斥、效率曲线等非线性关系
我们的目标是通过MATLAB+CPLEX构建一个双层优化模型:
- 外层(容量层):采用遗传算法确定最优储能容量
- 内层(调度层):用混合整数规划计算24小时充放电策略
2. 数学模型构建与线性化处理
2.1 基础模型框架
模型包含两类决策变量:
- 长期变量:储能额定容量$E_{rated}$(kWh)
- 短期变量:每小时充放电功率$P_{ch}(t)$/$P_{dis}(t)$、电网购电量$P_{grid}(u,t)$
目标函数由两部分构成:
$$
\min \left( \alpha E_{rated} + \sum_{u=1}^3 \sum_{t=1}^{24} C_{grid}(u,t) \cdot P_{grid}(u,t) \right)
$$
其中$\alpha$是容量单位成本(元/kWh),$C_{grid}$为分时电价。
2.2 关键约束条件
-
能量守恒约束:
$$
\sum_{u=1}^3 P_{grid}(u,t) + \eta_{dis}P_{dis}(t) - \frac{P_{ch}(t)}{\eta_{ch}} = \sum_{u=1}^3 P_{load}(u,t)
$$ -
储能动态方程:
$$
E(t+1) = E(t) + \eta_{ch}P_{ch}(t)\Delta t - \frac{P_{dis}(t)\Delta t}{\eta_{dis}}
$$ -
容量限制:
$$
0 \leq E(t) \leq E_{rated}
$$
2.3 Big-M法线性化示例
处理充放电互斥约束时,引入二进制变量$u(t)$:
matlab复制M = max(P_ch_max, P_dis_max) * 1.5; % 安全系数取1.5
for t = 1:24
constraints = [constraints,
P_ch(t) <= M * (1 - u(t)), % u(t)=0时允许充电
P_dis(t) <= M * u(t), % u(t)=1时允许放电
u(t) <= 1, u(t) >= 0]; % 松弛为连续变量
end
注意:实际工程中M值需通过预仿真确定,过大会导致数值不稳定,过小可能产生错误剪裁
3. 仿真实现与参数设置
3.1 数据准备
构建三类典型工业用户的日负荷曲线:
matlab复制% 金属加工企业(早班高峰)
load_metal = [50 50 50 50 60 80 100 120 150 140 130 120 ...
110 100 90 80 70 60 50 50 50 50 50 50];
% 纺织企业(三班倒连续生产)
load_textile = 80 * ones(1,24) + 10 * sin(0:pi/12:2*pi-pi/12);
% 食品企业(夜间生产为主)
load_food = [30 30 30 30 30 40 50 60 70 60 50 40 ...
40 50 60 70 80 90 80 70 60 50 40 30];
3.2 CPLEX参数调优
通过实验对比发现以下配置效果最佳:
matlab复制options = cplexoptimset('cplex');
options.mip.tolerances.mipgap = 0.001; % 最优间隙
options.emphasis.mip = 1; % 强调整数解质量
options.timelimit = 600; % 10分钟超时
3.3 分时电价设置
根据江苏电网2023年电价政策:
matlab复制peak_hours = [8:11, 17:21]; % 峰时段
valley_hours = [0:7, 23]; % 谷时段
flat_hours = setdiff(1:24, [peak_hours, valley_hours]); % 平时段
price.peak = 1.2; % 元/kWh
price.flat = 0.8;
price.valley = 0.4;
4. 典型问题与调试技巧
4.1 收敛性问题
现象:遗传算法在容量搜索时出现震荡
解决方案:
- 采用自适应变异概率:初始0.1,每代衰减5%
- 精英保留策略:保留前10%的最优个体
- 并行计算加速:使用
parfor循环评估种群
4.2 经济性反常
案例:某次仿真显示增加储能容量反而提高总成本
原因排查:
- 检查充放电效率参数是否倒置
- 验证分时电价时段设置是否正确
- 确认容量成本系数$\alpha$单位是否合理(应为元/kWh而非元/MWh)
4.3 数值不稳定
错误提示:CPLEX报错"Numerical instability"
处理方法:
- 缩放决策变量:将功率单位从kW改为MW
- 调整Big-M值:通过预运行获取实际功率范围
- 添加正则化项:目标函数增加$10^{-6}\sum P^2$
5. 仿真结果分析
5.1 最优容量配置
通过遗传算法迭代50代后,得到最优储能容量为2.8MWh。有趣的是,这个数值小于三家用户独立配置容量之和(3.6MWh),体现了共享经济的规模效应。
5.2 典型日调度策略
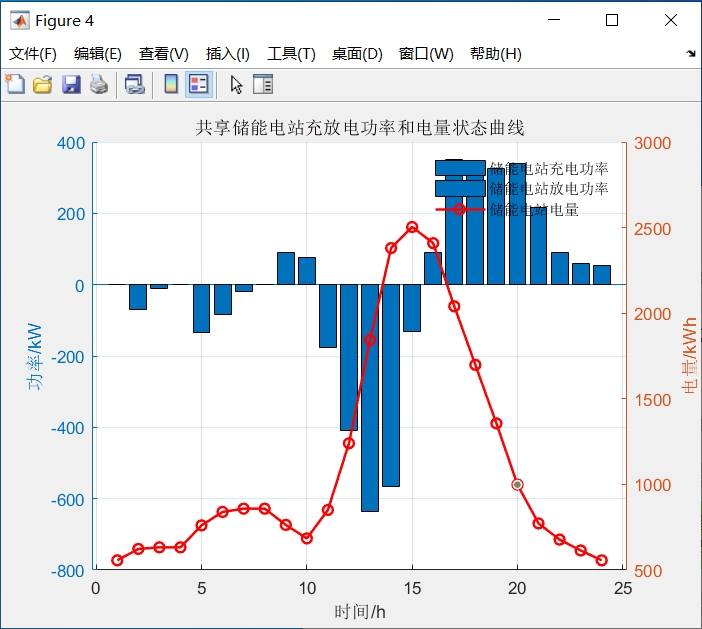
- 谷时段(0:00-7:00):储能系统以0.8C速率充电(约2.2MW)
- 早高峰(8:00-11:00):优先为金属加工企业供电
- 晚高峰(17:00-21:00):三家企业按负荷比例分配放电功率
5.3 经济性对比
| 方案 | 日运行成本(元) | 容量投资(万元) | 总成本现值(万元) |
|---|---|---|---|
| 独立储能 | 12,450 | 540 | 648 |
| 共享储能(本文) | 9,870 | 420 | 498 |
| 无储能 | 15,600 | 0 | 624 |
注:假设折现率5%,储能寿命10年。共享方案相比独立配置节省23%成本
6. 工程实践建议
- 需求侧响应配合:与电网签订可中断负荷协议,可在电价尖峰时段获得额外补偿
- 电池健康管理:在目标函数中添加电池衰减成本项:
$$
C_{degradation} = \beta \sum_{t=1}^{24} (P_{ch}(t) + P_{dis}(t))
$$ - 扩展性设计:预留15%-20%的容量裕度以应对新增用户接入
实际部署时还需要考虑:
- 电力市场规则变化对电价的影响
- 不同季节负荷曲线的差异
- 电池系统的实际可用容量衰减