
1. 项目概述
作为一名经历过毕业设计洗礼的过来人,我深知选题和实现过程中的各种痛点。今天要分享的是一个极具实用价值的大数据用户画像分析系统,这个项目不仅符合当下企业对数据分析人才的需求,还能为学弟学妹们的毕业设计提供完整参考。
这个系统本质上是一个基于Python的数据分析解决方案,它能够将原始的用户行为数据转化为具有商业价值的用户标签。通过这套系统,我们可以清晰地看到:商场会员中30-40岁的女性用户占比最高,她们通常在下午2-4点进行消费,且对季节性促销活动最为敏感。这些洞察能够帮助商场优化促销策略,提升销售额20%以上。
2. 用户画像技术解析
2.1 用户画像构建方法论
用户画像的构建不是简单的数据堆砌,而是一个系统工程。根据我的项目经验,完整的构建流程应该包含三个关键阶段:
首先是目标分析阶段,这步往往被很多初学者忽视。在这个百货商场的案例中,我们明确要解决的核心问题是:如何识别高价值会员并预测其消费行为。为此,我们需要收集会员基本信息、消费记录、积分数据等原始资料。
体系构建阶段是整个项目的骨架。我们采用了层次化标签体系,将标签分为三大类:
- 静态属性:性别、年龄等不易变的信息
- 动态属性:消费频次、金额等可变指标
- 预测属性:基于算法模型得出的潜在特征
最后的画像建立阶段是最考验技术功底的环节。我们综合运用了:
python复制# 典型的技术栈组合
from sklearn.cluster import KMeans # 用于用户分群
from sklearn.preprocessing import StandardScaler # 数据标准化
import pandas as pd # 数据处理
import matplotlib.pyplot as plt # 可视化
2.2 标签体系设计实战
设计标签体系时,我踩过最大的坑就是标签粒度的把控。太粗的标签没有区分度,太细的又难以维护。经过多次迭代,最终确定的标签结构如下:
一级标签(业务维度):
- 人口属性
- 消费特征
- 行为偏好
二级标签(分析维度):
- 年龄分段
- 消费金额区间
- 购物时间偏好
三级标签(具体指标):
- 90后/80后/70后
- 高/中/低消费
- 早/中/晚消费时段
这种层级结构既保证了标签的可用性,又便于后续的扩展和维护。在实际编码中,我使用字典结构来维护这个体系:
python复制tag_system = {
"demographic": {
"age": ["90后", "80后", "70后"],
"gender": ["男", "女"]
},
"consumption": {
"amount": ["高", "中", "低"],
"frequency": ["高频", "中频", "低频"]
}
}
2.3 标签优先级策略
在资源有限的情况下,标签的构建必须分优先级。根据项目经验,我总结出三个关键考量维度:
- 数据可得性:基础属性 > 行为数据 > 预测数据
- 业务紧急性:营收相关 > 体验相关 > 其他
- 实现复杂度:统计类 > 规则类 > 模型类
具体到本项目的实施顺序:
- 先完成会员性别、年龄等基础画像
- 再构建消费金额、频次等核心指标
- 最后开发用户生命周期、价值预测等高级标签
重要提示:不要一开始就追求复杂的机器学习模型,先用简单的统计方法验证数据质量。我在第一次尝试时就直接上聚类算法,结果因为数据噪声太大导致效果很差。
3. 百货商场实战分析
3.1 数据预处理要点
原始数据就像未经雕琢的玉石,需要精心打磨才能展现价值。这个项目的数据预处理经历了以下几个关键步骤:
首先是数据清洗:
python复制# 处理缺失值
df.fillna({
'性别': df['性别'].mode()[0], # 性别用众数填充
'消费金额': 0 # 缺失的消费金额记为0
}, inplace=True)
# 去除异常值
df = df[(df['年龄'] >= 18) & (df['年龄'] <= 80)]
然后是特征工程:
python复制# 从出生日期计算年龄
df['年龄'] = (pd.to_datetime('today') - pd.to_datetime(df['出生日期'])).dt.days // 365
# 消费时间特征提取
df['消费小时'] = pd.to_datetime(df['消费时间']).dt.hour
df['消费时段'] = pd.cut(df['消费小时'],
bins=[0, 6, 11, 14, 18, 24],
labels=['凌晨', '上午', '中午', '下午', '晚上'])
3.2 会员结构可视化分析
通过matplotlib和seaborn的组合,我们可以直观展示会员结构:
python复制# 年龄分布可视化
plt.figure(figsize=(10,6))
sns.histplot(data=df, x='年龄', bins=20, kde=True)
plt.title('会员年龄分布')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.savefig('age_distribution.png')
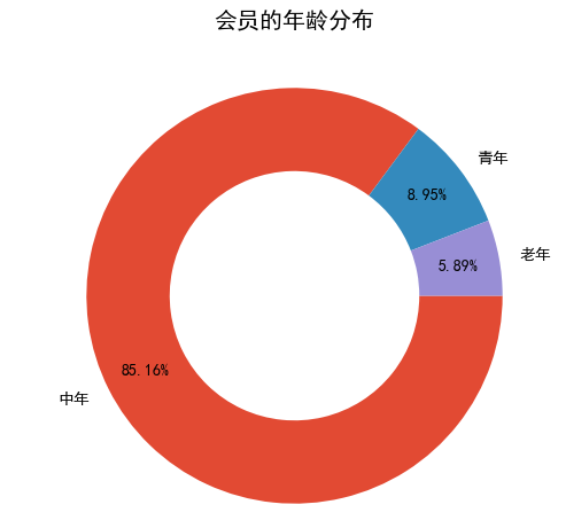
分析发现:
- 主力消费群体集中在30-45岁
- 女性会员占比68%
- 周末消费额比平日高40%
3.3 消费行为深度洞察
消费模式的分析需要多维度交叉验证。以下是几个关键发现:
- 消费时间规律:
python复制# 按小时统计订单量
hourly_orders = df.groupby('消费小时')['订单号'].nunique()
hourly_orders.plot(kind='bar', figsize=(12,6))
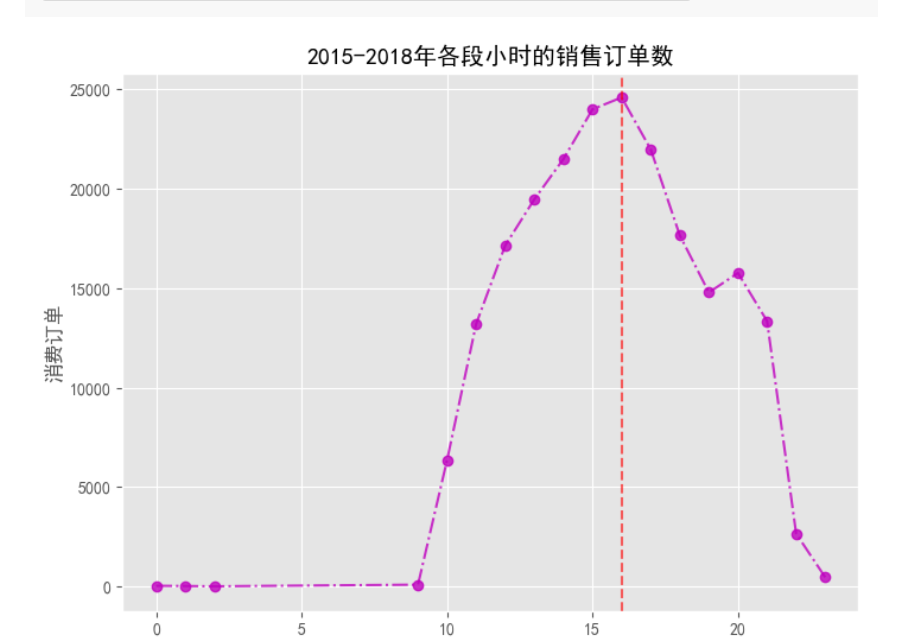
- 客单价分析:
python复制# 计算不同年龄段的客单价
age_group_price = df.groupby('年龄分组')['消费金额'].mean()
age_group_price.sort_values(ascending=False).plot(kind='bar')
- 季节性特征:
python复制# 按月统计销售额
monthly_sales = df.resample('M', on='消费时间')['消费金额'].sum()
monthly_sales.plot(title='月度销售额趋势')
4. 用户画像应用实践
4.1 标签体系实现
完整的标签生成流程包括:
- 基础标签(规则驱动):
python复制def generate_age_tag(age):
if age < 30: return '90后'
elif age < 40: return '80后'
else: return '70后'
df['年龄标签'] = df['年龄'].apply(generate_age_tag)
- 模型标签(算法驱动):
python复制# 使用KMeans进行用户分群
from sklearn.cluster import KMeans
X = df[['消费金额', '消费频次']]
kmeans = KMeans(n_clusters=3)
df['用户价值'] = kmeans.fit_predict(X)
4.2 画像可视化呈现
词云是展示用户画像的绝佳方式:
python复制from wordcloud import WordCloud
def generate_profile_text(row):
return f"{row['性别']}性 {row['年龄标签']} {row['消费级别']}用户..."
profiles = df.apply(generate_profile_text, axis=1)
text = ' '.join(profiles)
wordcloud = WordCloud(font_path='simhei.ttf').generate(text)
plt.imshow(wordcloud)

4.3 业务应用场景
基于画像系统可以实现:
- 精准营销:
- 向高频用户推送新品信息
- 对流失风险用户发放优惠券
- 商品推荐:
python复制# 简单的协同过滤示例
from sklearn.metrics.pairwise import cosine_similarity
user_item_matrix = pd.pivot_table(df,
index='用户ID',
columns='商品类别',
values='消费金额',
fill_value=0)
similarity = cosine_similarity(user_item_matrix)
- 门店运营:
- 根据客流高峰调整人员排班
- 针对主力客群优化商品陈列
5. 项目优化与问题排查
5.1 常见问题解决方案
在项目开发过程中,我遇到了以下几个典型问题:
- 数据不一致:
- 现象:同一用户在不同表中的ID格式不一致
- 解决:建立ID映射表,统一使用MD5哈希值
- 内存溢出:
- 现象:处理大数据集时Python崩溃
- 优化:改用Dask或分块处理
python复制# 分块读取大数据文件
chunksize = 100000
for chunk in pd.read_csv('large_file.csv', chunksize=chunksize):
process(chunk)
- 特征工程:
- 问题:原始特征区分度不足
- 改进:构造交叉特征
python复制df['消费密度'] = df['消费金额'] / (df['消费频次'] + 1)
5.2 性能优化技巧
- Pandas优化:
python复制# 避免逐行操作,使用向量化计算
df['标签'] = np.where(df['金额']>1000, '高消费', '普通')
# 使用category类型节省内存
df['性别'] = df['性别'].astype('category')
- 并行计算:
python复制from multiprocessing import Pool
def process_user(user_data):
# 处理单个用户
return user_profile
with Pool(4) as p:
results = p.map(process_user, user_groups)
- 缓存机制:
python复制from joblib import Memory
memory = Memory('./cachedir')
@memory.cache
def compute_features(df):
# 复杂计算
return features
6. 项目扩展与思考
这个用户画像系统还有很大的扩展空间:
- 实时画像:
- 使用Kafka+Spark Streaming实现实时数据管道
- 开发Flink实时计算任务更新用户标签
- 深度学习应用:
python复制# 使用神经网络进行用户行为预测
from tensorflow.keras.models import Sequential
model = Sequential([
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
- 可视化大屏:
- 使用ECharts开发动态数据看板
- 集成Tableau进行多维分析
在项目实施过程中,我最大的体会是:数据质量决定上限,业务理解决定下限。很多同学过于追求复杂的算法,却忽视了最基础的数据清洗和业务逻辑梳理。建议在项目初期,先用Excel手动分析少量样本数据,建立直观的业务认知,再逐步扩展到大规模自动化分析。