
1. 订单超时自动取消的技术实现方案
在电商系统中,订单超时自动取消是一个经典的技术需求场景。想象一下这样的场景:用户下单后,如果30分钟内没有完成支付,系统需要自动取消订单并释放库存。这个看似简单的需求背后,涉及到分布式系统、定时任务、消息队列等多个技术要点。
作为经历过多次618、双11大促的老兵,我见过太多因为订单超时处理不当导致的系统问题。有的系统因为轮询数据库太频繁直接把数据库打挂,有的因为内存队列处理不当导致OOM,还有的因为分布式锁使用不当导致订单被重复取消。今天我就结合自己多年的实战经验,为大家详细剖析几种常见的实现方案。
2. 延时任务与定时任务的区别
2.1 核心概念解析
很多刚入行的同学容易混淆延时任务和定时任务,其实它们的区别非常明显:
-
定时任务:就像你每天早上7点的闹钟,不管你有没有睡醒,到点就会响。对应到系统中,就是固定周期执行的任务,比如每天凌晨统计前一天的销售数据。
-
延时任务:更像是烤箱的定时器,你放入蛋糕后设置30分钟,它会在30分钟后提醒你。对应到系统中,就是在某个事件触发后需要延迟执行的任务,比如下单后30分钟未支付则取消订单。
2.2 技术特性对比
从技术实现角度来看,它们的区别主要体现在:
| 特性 | 定时任务 | 延时任务 |
|---|---|---|
| 触发时机 | 固定时间点或周期 | 事件触发后的延迟时间 |
| 执行频率 | 周期性执行 | 单次执行 |
| 任务数量 | 通常批量处理多个任务 | 通常处理单个任务 |
| 典型场景 | 日报生成、数据统计 | 订单超时、短信提醒 |
| 实现复杂度 | 相对简单 | 相对复杂 |
| 资源占用 | 可控 | 突发性高 |
3. 数据库轮询方案
3.1 实现原理
数据库轮询是最朴素的实现方式,其核心思路是启动一个定时任务,定期扫描订单表,找出创建时间超过30分钟且状态为"待支付"的订单,将其状态更新为"已取消"。
java复制// Quartz定时任务示例
public class OrderCancelJob implements Job {
public void execute(JobExecutionContext context) {
// 查询超时订单
List<Order> timeoutOrders = orderMapper.selectTimeoutOrders(30);
// 批量取消订单
timeoutOrders.forEach(order -> {
order.setStatus(OrderStatus.CANCELLED);
orderMapper.update(order);
// 释放库存等后续操作
inventoryService.releaseStock(order);
});
}
}
3.2 优缺点分析
优点:
- 实现简单,适合小型项目快速上线
- 不需要引入额外中间件
- 支持集群部署(通过分布式锁避免重复执行)
缺点:
- 实时性差:如果每5分钟扫描一次,最坏情况下订单可能35分钟才被取消
- 数据库压力大:随着订单量增长,全表扫描会消耗大量IO
- 性能瓶颈:当订单量达到百万级时,查询性能急剧下降
3.3 优化建议
如果必须使用这种方案,可以考虑以下优化:
- 为订单创建时间字段和状态字段建立联合索引
- 采用分页查询避免一次性加载过多数据
- 根据业务量合理设置扫描间隔
- 将扫描任务放在业务低峰期执行
提示:在实际项目中,这种方案仅适用于订单量较小(日订单<1万)的场景。我曾在一个创业项目中用过这种方案,当订单量增长到每天5万单时,数据库CPU经常飙到90%以上,后来不得不重构。
4. JDK延迟队列方案
4.1 实现原理
JDK提供了DelayQueue,这是一个无界阻塞队列,只有在延迟期满时才能从中取出元素。我们可以将订单信息放入DelayQueue,由专门的线程消费。
java复制public class OrderDelay implements Delayed {
private String orderId;
private long expireTime; // 到期时间
public long getDelay(TimeUnit unit) {
return unit.convert(expireTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
public int compareTo(Delayed other) {
return Long.compare(this.expireTime, ((OrderDelay)other).expireTime);
}
}
// 使用示例
public class OrderCancelService {
private DelayQueue<OrderDelay> queue = new DelayQueue<>();
public void addOrder(String orderId, long delayMinutes) {
queue.put(new OrderDelay(orderId, delayMinutes));
}
@PostConstruct
public void init() {
new Thread(() -> {
while(true) {
try {
OrderDelay order = queue.take();
orderService.cancelOrder(order.getOrderId());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}).start();
}
}
4.2 优缺点分析
优点:
- 实现相对简单
- 延迟精度高(毫秒级)
- 性能较好(完全内存操作)
缺点:
- 单机内存有限,订单量大时容易OOM
- 重启后数据丢失
- 不支持分布式部署
- 代码复杂度较高
4.3 使用场景建议
这种方案适合:
- 订单量不大(万级以下)
- 允许重启后数据丢失
- 单机部署环境
我在一个内部管理系统中使用过这种方案,处理每天约2000个预约超时取消的场景,运行非常稳定。但绝对不要用在大流量的电商主站!
5. 时间轮算法方案
5.1 时间轮原理
时间轮算法是定时任务的高效实现方式,Netty的HashedWheelTimer是其典型实现。它就像一个时钟,指针每隔固定时间(tickDuration)转动一格,每格对应一个任务槽。
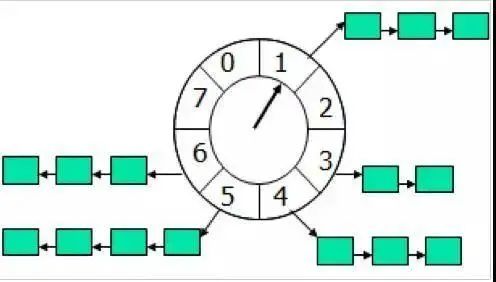
当我们需要延迟执行任务时,计算任务应该放在哪个槽:
- 当前指针在1,任务需要4秒后执行 → 放在(1+4)=5槽
- 任务需要20秒后执行,时间轮共8槽 → 放在(20%8+1)=5槽(指针转2圈后)
5.2 实现示例
java复制public class OrderCancelTimer {
private HashedWheelTimer timer = new HashedWheelTimer(1, TimeUnit.SECONDS, 60);
public void scheduleCancel(String orderId, long delayMinutes) {
timer.newTimeout(timeout -> {
orderService.cancelOrder(orderId);
}, delayMinutes, TimeUnit.MINUTES);
}
}
5.3 优缺点分析
优点:
- 性能极高(时间复杂度O(1))
- 实现比DelayQueue更简单
- 延迟精度较高
缺点:
- 仍然是内存方案,存在OOM风险
- 重启后数据丢失
- 不支持分布式
5.4 适用场景
适合对性能要求高但数据可丢失的场景,如:
- 客户端超时控制
- 连接保活检测
- 本地缓存过期
6. Redis实现方案
6.1 基于ZSet的实现
Redis的ZSet(有序集合)可以完美实现延迟队列。我们将订单ID作为member,超时时间戳作为score,启动一个线程不断检查第一个元素是否到期。
java复制public class RedisOrderCancel {
private static final String DELAY_QUEUE = "order:delay";
public void addOrder(String orderId, long delayMinutes) {
long score = System.currentTimeMillis() + delayMinutes * 60 * 1000;
redisTemplate.opsForZSet().add(DELAY_QUEUE, orderId, score);
}
@Scheduled(fixedDelay = 5000)
public void checkTimeoutOrders() {
Set<String> orders = redisTemplate.opsForZSet().rangeByScore(DELAY_QUEUE, 0, System.currentTimeMillis(), 0, 1);
if(!orders.isEmpty()) {
String orderId = orders.iterator().next();
Long removed = redisTemplate.opsForZSet().remove(DELAY_QUEUE, orderId);
if(removed != null && removed > 0) {
orderService.cancelOrder(orderId);
}
}
}
}
关键点:
- 使用ZADD添加订单,score=当前时间+延迟时间
- 使用ZRANGEBYSCORE查询已到期的订单
- 使用ZREM删除订单(配合返回值判断避免并发问题)
6.2 基于Key过期通知的实现
Redis的Keyspace Notifications可以在key过期时触发事件,我们可以利用这个特性:
- 修改redis.conf:
code复制notify-keyspace-events Ex
- 实现监听:
java复制public class RedisKeyExpirationListener extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
if(message.startsWith("order:")) {
String orderId = message.substring(6);
orderService.cancelOrder(orderId);
}
}
}
// 订阅
jedis.psubscribe(new RedisKeyExpirationListener(), "__keyevent@0__:expired");
注意: 这种方式消息不可靠,客户端断开期间的通知会丢失。
6.3 Redis方案优缺点
优点:
- 支持分布式部署
- 性能较好
- 数据持久化,重启不丢失
- 集群扩展方便
缺点:
- ZSet方案需要轮询
- 过期通知不可靠
- 需要额外维护Redis
7. 消息队列方案
7.1 RabbitMQ实现
RabbitMQ可以通过死信队列实现延迟队列:
- 创建延迟交换机和队列:
java复制Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "order.cancel.exchange");
args.put("x-dead-letter-routing-key", "order.cancel");
channel.queueDeclare("order.delay.queue", true, false, false, args);
- 发送延迟消息:
java复制AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.expiration("1800000") // 30分钟
.build();
channel.basicPublish("", "order.delay.queue", props, orderId.getBytes());
- 消费取消消息:
java复制channel.basicConsume("order.cancel.queue", true, (consumerTag, delivery) -> {
String orderId = new String(delivery.getBody());
orderService.cancelOrder(orderId);
}, consumerTag -> {});
7.2 其他消息队列
- RocketMQ:原生支持延迟消息,18个固定级别
- Kafka:需要自行实现时间轮+外部存储
- Pulsar:支持任意精度的延迟消息
7.3 消息队列方案优缺点
优点:
- 高可靠、高可用
- 支持分布式
- 性能好
- 天然解耦
缺点:
- 系统复杂度增加
- 需要额外维护消息队列
- 某些MQ的延迟功能有限制
8. 方案选型建议
根据不同的业务场景,我建议这样选择:
| 场景特征 | 推荐方案 | 原因 |
|---|---|---|
| 小型项目,订单量小 | 数据库轮询 | 简单,无需额外组件 |
| 中型项目,允许少量数据丢失 | JDK延迟队列/时间轮 | 性能好,实现简单 |
| 分布式系统,要求高可靠 | RabbitMQ/RocketMQ | 支持分布式,可靠性高 |
| 已有Redis,要求快速实现 | Redis ZSet | 利用现有组件,开发速度快 |
| 超大规模,超高并发 | 分片+专用延迟服务 | 可水平扩展,性能极高 |
9. 生产环境注意事项
在实际项目中,除了核心功能外,还需要考虑:
- 幂等性处理:网络抖动可能导致取消操作重复执行
- 监控报警:对取消失败的情况要有监控
- 补偿机制:定期核对未支付订单状态
- 压力测试:模拟大流量下的表现
- 降级方案:当延迟服务不可用时如何应对
我曾经遇到过一个线上事故:因为网络分区导致Redis集群故障,延迟队列停止工作,8小时后才发现有大量超时订单未处理。后来我们增加了以下保护措施:
- 每小时运行一次补偿Job核对未支付订单
- 实现双写机制(Redis+数据库)
- 增加仪表盘监控延迟队列积压情况
10. 高级优化思路
对于超大规模电商系统,还可以考虑:
- 分片设计:按订单ID哈希分片到不同队列
- 分级延迟:先入短时间队列,快到期时转入精确队列
- 外部存储:将任务信息存入数据库,队列只存ID
- 专用延迟服务:如阿米的Timer、美团的Hourglass
这些方案实现复杂度较高,一般只有当日订单量超过百万时才需要考虑。在我参与过的一个跨境电商项目中,我们基于RocketMQ+分片Redis实现了一套分级延迟系统,可以支撑每天500万订单的超时处理,P99延迟控制在3秒内。
11. 常见问题排查
在实际使用中,可能会遇到以下问题:
问题1:订单取消了但库存没释放
- 原因:事务未正确处理
- 解决:将订单状态更新和库存释放放在同一事务中
问题2:大量订单同时超时导致系统卡顿
- 原因:处理逻辑太重,没有限流
- 解决:引入批处理+速率限制
问题3:分布式环境下重复取消
- 原因:没有做好幂等
- 解决:在取消前先检查当前状态
问题4:延迟时间不准确
- 原因:系统时钟不同步
- 解决:使用NTP服务同步时间
12. 性能测试数据参考
以下是我们压测某方案的性能数据(仅供参考):
| 方案 | 吞吐量(订单/秒) | P99延迟 | CPU占用 | 内存占用 |
|---|---|---|---|---|
| 数据库轮询 | 120 | 5-10s | 高 | 低 |
| JDK延迟队列 | 8500 | <100ms | 中 | 高 |
| Redis ZSet | 4200 | 1-3s | 中 | 中 |
| RabbitMQ | 3200 | 2-5s | 低 | 低 |
| 时间轮 | 15000 | <50ms | 中 | 中 |
13. 最佳实践建议
根据我的经验,给出以下建议:
- 中小项目:直接使用Redis ZSet方案,配合Lua脚本保证原子性
- 中大型项目:使用RabbitMQ死信队列,可靠性有保障
- 超大型系统:考虑自研分片延迟服务或使用商业中间件
- 关键业务:一定要实现补偿机制和监控报警
- 新项目启动:优先考虑云服务商提供的延迟消息服务
最后提醒一点:任何技术方案都要结合团队的技术栈和业务特点来选择,没有放之四海而皆准的完美方案。