
1. Word图表目录生成全流程解析
作为一名经常需要处理长篇文档的编辑,我深知手动维护图表目录的痛苦。每次调整内容后,图表编号和页码都需要重新核对,费时费力还容易出错。其实Word自带的图表目录功能可以完美解决这个问题,下面我就把多年积累的完整操作流程和避坑经验分享给大家。
图表目录的核心原理是"题注+字段代码"。当你为图片或表格添加题注时,Word会自动记录这些元素的类型、编号和位置信息。生成目录时,Word只是把这些信息按特定格式提取出来而已。这种机制保证了目录与正文的实时联动——修改正文后只需更新字段,目录就会自动同步。
2. 详细操作步骤与技巧
2.1 题注设置关键操作
首先选中要添加编号的图片,在【引用】选项卡点击【插入题注】。这里有个重要细节:新建文档时建议先点击【新建标签】,创建"图"、"表"等自定义标签(如图1)。系统默认的"Figure"等英文标签在中文文档中会很突兀。
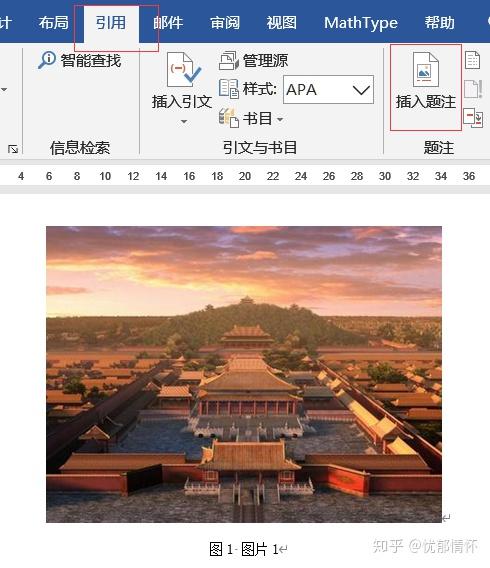
提示:建议在文档模板中预先设置好常用标签,这样后续插入时可以直接选用,避免重复创建。
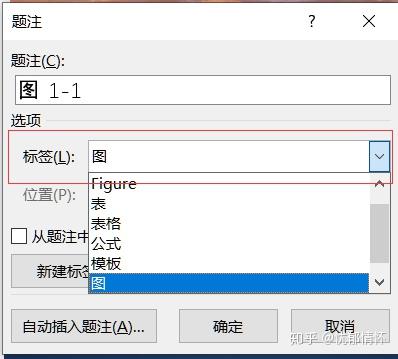
编号格式设置是另一个关键点。点击【编号】按钮后(如图2),你会看到两个重要选项:
- 包含章节号:需要文档已应用多级列表样式才有效
- 使用分隔符:建议选择"短横线"而非默认的句点,更符合中文排版习惯
2.2 批量处理现有图片
对于文档中已有的数十张图片,逐个添加题注太耗时。这里分享我的高效方法:
- 按Alt+F11打开VBA编辑器
- 插入新模块,粘贴以下代码:
vba复制Sub AddCaptionToAllShapes()
Dim shp As Shape
For Each shp In ActiveDocument.Shapes
shp.Select
Selection.Range.InsertCaption Label:="图", TitleAutoText:="", _
Title:="", Position:=wdCaptionPositionBelow
Next
End Sub
- 运行宏即可自动为所有图片添加题注
2.3 生成智能目录
在目标位置点击【引用】→【插入表目录】,关键设置有三处(如图3):
- 题注标签:选择要生成目录的对象类型(图/表)
- 格式:建议选"正式"样式更美观
- 制表符前导符:推荐使用虚线而非实线
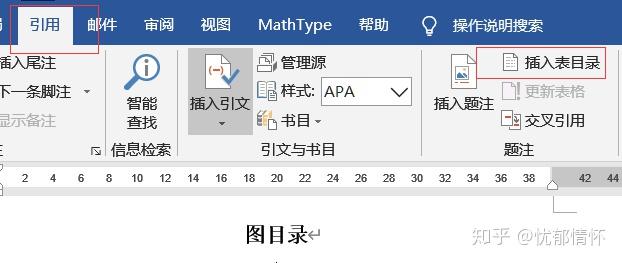
重要技巧:勾选"使用超链接"选项,这样生成的目录可以点击跳转,电子文档体验更好。
3. 高级应用与疑难解答
3.1 多级编号系统配置
如果需要"图1-1"这样的章节关联编号,必须提前做好三件事:
- 为标题应用多级列表样式
- 在【开始】→【多级列表】中配置好编号格式
- 题注编号设置中勾选"包含章节号"
常见问题:编号显示为"图0-1"?
这是因为该图片所在段落未被识别为正文内容。解决方法:
- 选中图片所在段落
- 在【开始】选项卡应用"正文"样式
- 更新目录字段
3.2 样式自定义技巧
默认生成的目录样式可能不符合要求,可以通过以下步骤调整:
- 右键点击目录→【编辑域】
- 点击【目录】→【修改】
- 分别设置"图表目录1"等样式的字体、间距
- 建议将目录项的行距设为1.5倍,便于阅读
3.3 文档协作注意事项
当多人协作编辑文档时,容易出现目录更新不同步的问题。建议:
- 发送文档前按Ctrl+A全选,然后F9更新所有字段
- 在【文件】→【选项】→【高级】中,勾选"打印前更新字段"
- 提醒协作者修改图片后按Alt+F9切换域代码视图检查
4. 实战问题排查指南
4.1 目录生成失败常见原因
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 目录显示"错误!未找到目录项" | 1. 未添加题注 2. 题注标签不匹配 |
1. 检查所有图片是否添加题注 2. 确认目录设置的标签与题注一致 |
| 编号不连续 | 1. 手动修改过编号 2. 图片被隐藏 |
1. 删除手动编号,重新插入题注 2. 取消图片隐藏状态 |
| 页码错误 | 1. 分节符影响 2. 页眉页脚设置问题 |
1. 检查分节符位置 2. 统一页码格式 |
4.2 目录格式混乱修复
当目录出现奇怪的缩进或换行时,可以:
- 选中整个目录按Ctrl+Q清除段落格式
- 手动调整制表位:在标尺上拖动制表符标记
- 检查是否混用了不同样式的题注
4.3 跨文档目录整合
需要合并多个文档的图表目录时:
- 在主文档使用【插入】→【对象】→"文件中的文字"合并内容
- 按Ctrl+Shift+F9将所有域转换为静态文本
- 重新插入题注并生成新目录
- 或者使用RD字段实现动态引用(需配置路径)
经过这些年的实践,我发现最稳妥的做法是:任何涉及图表编号的修改后,立即按Ctrl+A全选文档,然后F9更新所有字段。养成这个习惯可以避免90%的目录相关问题。另外建议定期将文档另存为PDF,既能固定排版,又能检查最终输出效果是否正常。