深入解析Linux进程状态及其调优实践

1. Linux进程状态全景解析
作为一名在Linux系统下摸爬滚打多年的开发者,我深刻理解进程状态对系统调优和问题排查的重要性。很多人对进程状态的理解停留在表面,今天我就结合内核源码和实际案例,带大家深入理解这个基础但至关重要的概念。
1.1 进程控制块(PCB)的核心地位
在Linux内核中,每个进程都由一个task_struct结构体表示,这就是我们常说的进程控制块(PCB)。它不仅是进程存在的唯一标识,更是状态管理的核心载体。通过源码可以看到(include/linux/sched.h):
c复制struct task_struct {
volatile long state; // -1不可运行, 0可运行, >0停止
void *stack;
unsigned int flags;
struct mm_struct *mm; //内存管理信息
pid_t pid; //进程标识符
struct list_head tasks; //所有task形成的链表
//...其他字段超过500行
};
关键点在于state字段,它直接决定了进程当前的生命周期状态。而进程状态变化的本质,其实就是内核通过调度器不断修改这个字段值,并将task_struct转移到不同的队列中。
经验之谈:调试进程问题时,用
p task->state命令可以直接查看进程状态值,比ps命令更接近内核真相
1.2 状态转换的底层逻辑
所有状态转换都围绕CPU时间片分配展开。当我在内核4.19版本中追踪schedule()函数时,发现其核心逻辑是:
- 从运行队列选取下一个进程
- 保存当前进程上下文
- 切换新进程的地址空间
- 恢复新进程的上下文
这个过程中涉及三种关键队列:
- 运行队列(runqueue):存放TASK_RUNNING状态的进程
- 等待队列(wait_queue):设备驱动使用的阻塞队列
- 僵尸队列(zombie_list):存放EXIT_ZOMBIE状态的进程
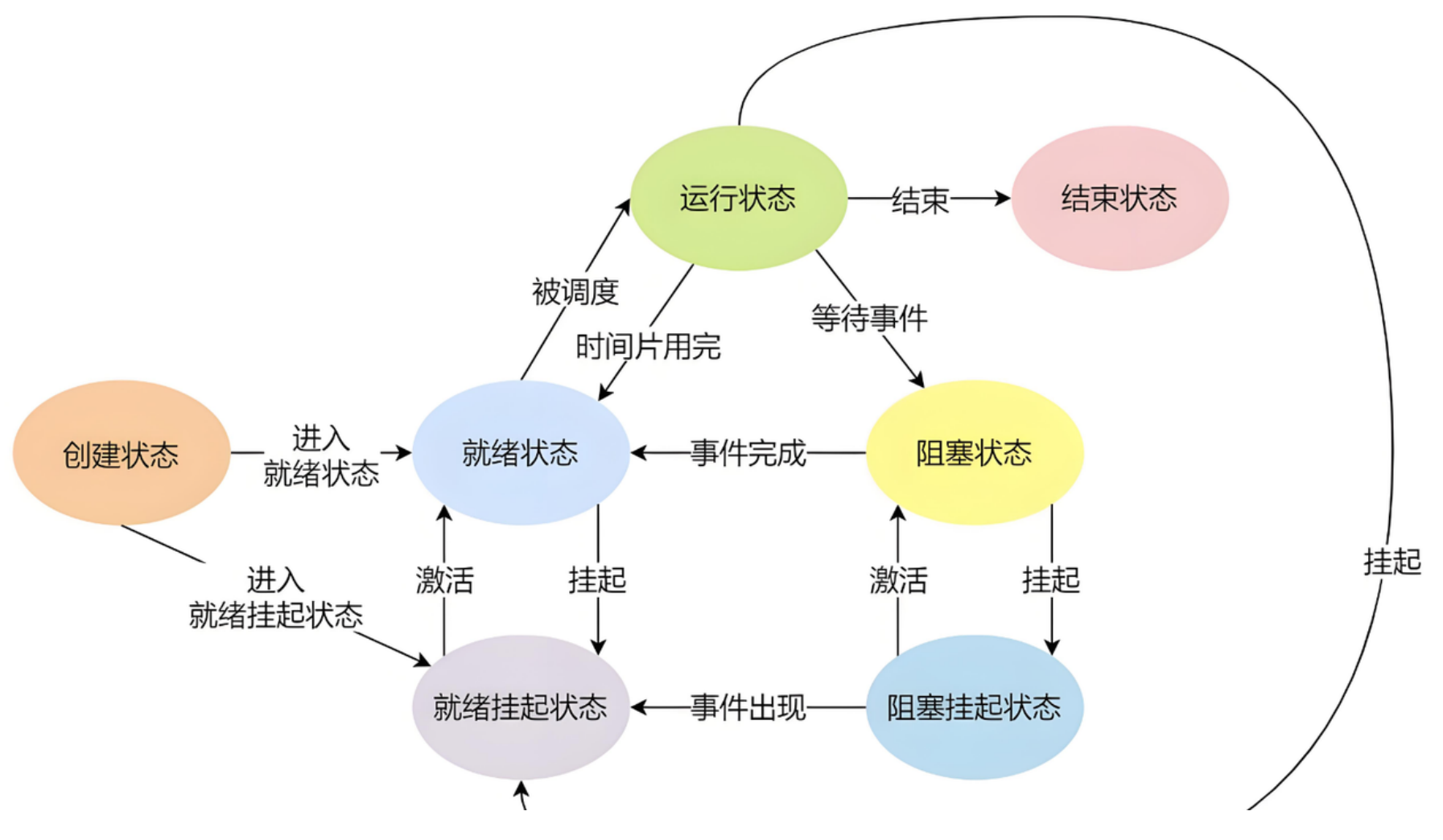
2. 运行状态(R)的深层机制
2.1 多核CPU的调度队列
现代Linux采用CFS(完全公平调度器)算法,其运行队列实现非常精妙。在我的8核服务器上观察调度情况:
bash复制$ watch -n 1 'cat /proc/sched_debug | grep "runnable tasks"'
输出显示每个CPU核心都有独立的运行队列,且负载均衡器会动态调整任务分配。这解释了为什么多核系统中R状态进程数可能大于CPU核心数。
2.2 就绪与执行的微妙区别
虽然ps命令统一显示为R,但内核其实区分两种子状态:
- TASK_RUNNING:在运行队列等待调度
- TASK_RUNNING | TASK_ON_RQ:正在CPU执行
通过perf工具可以观察到这种区别:
bash复制$ perf stat -e 'sched:sched_switch' -a sleep 1
3. 休眠状态(S/D)的实战分析
3.1 可中断休眠(S)的典型场景
开发网络服务时经常遇到S状态。例如Nginx worker进程在等待连接时:
bash复制$ ps -eo pid,state,cmd | grep nginx
1234 S nginx: worker process
这种休眠能被信号中断,所以服务重载时worker能快速响应HUP信号。
3.2 不可中断休眠(D)的危机处理
我在处理数据库备份时遇到过D状态卡死的情况。当时现象是:
- mysqldump进程状态变为D
- 磁盘IO利用率100%
- 任何kill命令无效
解决方案是:
bash复制# 1. 找出阻塞的IO请求
$ cat /proc/1234/stack
# 2. 重启对应存储服务
$ systemctl restart storage-service
血泪教训:生产环境要避免大量同步磁盘IO,改用异步写入或内存缓冲
4. 停止状态(T/t)的调试应用
4.1 作业控制的实际运用
在编写自动化脚本时,常用到作业控制:
bash复制$ long-running-task &
$ jobs -l # 查看后台任务
$ kill -TSTP %1 # 暂停任务
$ bg %1 # 继续后台运行
4.2 调试状态(t)的底层原理
当用gdb调试时,断点触发其实是向进程发送SIGTRAP信号。观察这个过程:
bash复制$ gdb -p 1234
(gdb) break main
(gdb) continue
# 另一个终端观察
$ cat /proc/1234/status
State: t (tracing stop)
5. 僵尸进程(Z)的防治实战
5.1 僵尸进程的产生实验
通过这个C程序可以故意制造僵尸进程:
c复制#include <unistd.h>
int main() {
if(fork() > 0) {
while(1) sleep(1); //父进程不调用wait
}
return 0;
}
监控僵尸进程的增长:
bash复制$ watch -n 1 'ps -eo stat,pid,cmd | grep "^Z"'
5.2 生产环境的防治策略
在我维护的Web服务中,采用这些方法避免僵尸进程:
- 父进程安装SIGCHLD信号处理器
- 使用双重fork技巧
- 设置init进程接管孤儿进程
c复制// 可靠的信号处理示例
struct sigaction sa;
sa.sa_handler = reap_children;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART | SA_NOCLDSTOP;
sigaction(SIGCHLD, &sa, NULL);
6. 进程状态监控的高级技巧
6.1 实时状态监控工具
我常用的监控组合:
bash复制# 1. 整体状态概览
$ top -b -n 1 | head -15
# 2. 特定进程详细状态
$ cat /proc/1234/status
# 3. 内核级状态跟踪
$ perf trace -p 1234
6.2 状态异常排查流程
当发现进程状态异常时,我的排查步骤:
- 检查进程的stack trace
bash复制$ cat /proc/1234/stack - 分析系统调用
bash复制
$ strace -p 1234 - 检查资源限制
bash复制$ cat /proc/1234/limits
7. 内核参数调优经验
在高压力的生产环境中,这些调优很关键:
bash复制# 防止进程过多导致僵尸进程积累
$ sysctl -w kernel.threads-max=120000
# 调整进程回收频率
$ sysctl -w kernel.hung_task_timeout_secs=30
# 优化调度器响应
$ sysctl -w kernel.sched_min_granularity_ns=10000000
经过这些年的实践,我最大的体会是:理解进程状态不仅是掌握Linux的基础,更是诊断系统问题的关键技能。特别是在高并发场景下,对状态转换的敏锐观察往往能快速定位性能瓶颈。建议每位开发者都花时间用strace、perf等工具实际观察进程状态变化,这比单纯看书收获大得多。