网约车动态投资策略优化:FCA-RL框架解析

李放放
1. 项目概述:网约车服务商的动态投资策略优化
在网约车平台生态中,出行服务商(Ride Service Provider, RSP)面临着如何在有限预算下最大化订单获取效率的核心挑战。传统静态投资策略难以应对竞争对手频繁调整补贴力度导致的市场环境变化,往往造成预算超支或资金利用率低下。ECML-PKDD 2025发表的FCA-RL框架创新性地将强化学习与动态适应机制相结合,为RSP提供了智能化的投资决策解决方案。
这个研究首次从RSP视角系统性地解决了三个关键问题:
- 如何在网约车平台的"前K低价展示"机制下有效进入乘客默认选择范围
- 如何实时感知竞争对手策略变化对自身订单获取率(IRR)的影响
- 如何在动态环境中严格保持"投资成本≤GMV×预算率"的硬性约束
提示:IRR(In-Range Rate)是本文核心指标,表示我方RSP的报价进入平台默认前K低价范围的概率,直接影响订单获取成功率。
2. 核心问题建模与静态优化
2.1 基础数学模型构建
假设单个订单i的完成概率可分解为:
code复制P(完成) = P(进入前K名) × P(进入后完成) + P(未进入前K名) × P(未进入但完成)
其中P(进入前K名)受竞争对手报价影响最大,是动态变化的主要来源。
优化目标函数:
math复制\min \sum_{i}(1-y_i) \quad \text{s.t.} \quad \sum_{i}c_i \leq B\cdot GMV
其中:
- y_i ∈ {0,1}表示是否对订单i使用折扣券
- c_i是对应折扣券的成本
- B是预设预算率(如GMV的5%)
2.2 拉格朗日松弛解法
通过引入拉格朗日乘子λ≥0,将约束优化转化为无约束问题:
math复制L(λ) = \min_{y} \sum_{i}(1-y_i) + λ(\sum_{i}c_i - B\cdot GMV)
对固定λ,最优折扣选择策略为:
math复制y_i^* = \begin{cases}
1 & \text{if } p_i > λc_i \\
0 & \text{otherwise}
\end{cases}
通过三分搜索法高效求解最优λ*:
python复制def ternary_search(l, r, epsilon=1e-5):
while r - l > epsilon:
mid1 = l + (r-l)/3
mid2 = r - (r-l)/3
if f(mid1) < f(mid2):
r = mid2
else:
l = mid1
return l
3. 动态环境挑战与FCA-RL框架
3.1 静态方法的局限性
当竞争对手调整投资策略时,会导致:
- 我方IRR分布发生漂移:P(进入前K名)发生变化
- 原最优解λ*失效,导致:
- 实际支出偏离预算约束
- 资金使用效率下降
3.2 FCA-RL整体架构
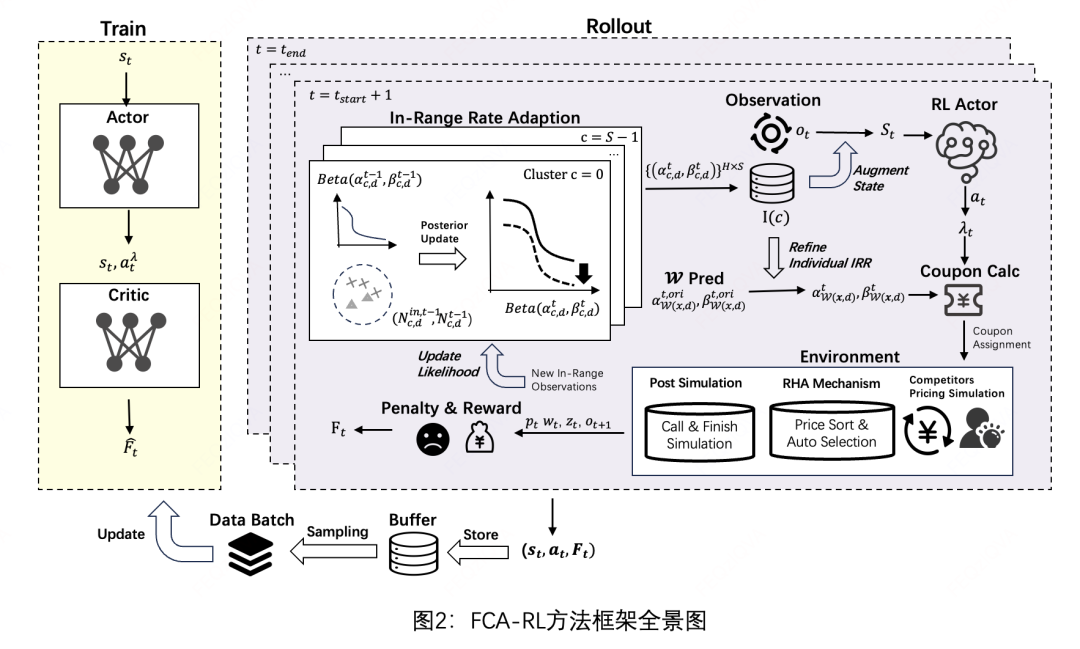
框架包含两大核心模块:
- 快速竞争适应(FCA):实时追踪IRR分布变化
- 强化学习调节(RLA):动态调整拉格朗日乘子λ
3.2.1 FCA模块技术细节
-
特征聚类:使用K-Means将订单按特征相似度分组
python复制from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=20).fit(X) cluster_labels = kmeans.predict(X) -
Beta分布建模:
- 假设初始IRR∼Beta(α,β)
- 通过贝叶斯更新实时调整参数:
math复制α_{t} = α_{t-1} + \text{成功次数} β_{t} = β_{t-1} + \text{失败次数}
-
滑动窗口机制:
- 统计最近W个时间片的观测数据
- 平衡即时响应与噪声过滤(实验显示W=24最优)
3.2.2 RLA模块实现
采用Actor-Critic强化学习框架:
状态空间:
- 当前λ值
- 各簇IRR分布的均值/方差
- 预算使用进度
动作空间:λ的调整幅度(高斯分布采样)
奖励函数:
math复制R = \text{订单增量} - η\cdot|\text{成本率}-B|
策略更新:
math复制λ_{t} = clip(λ_{t-1} + a_t, λ_{min}, λ_{max})
4. RideGym仿真系统设计
4.1 系统架构
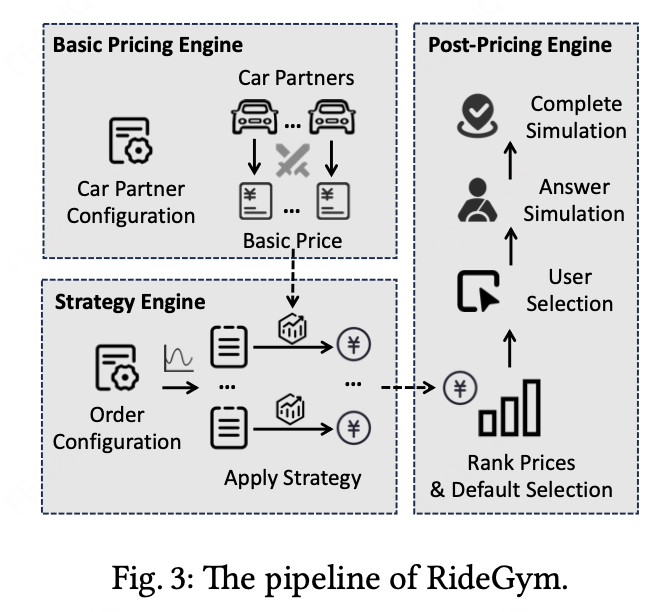
三大核心组件:
-
基础定价引擎:
- 模拟各RSP的基准报价
- 竞争对手投资策略建模:
math复制\text{报价} = \text{基准价} \times (1 - a), \quad a\sim U[a_{min},a_{max}]
-
策略引擎:
- 订单流生成(混合正态分布)
- 集成各类投资策略算法
-
后定价引擎:
- 实现Top-K选择机制
- 乘客选择建模:
math复制K' = clip(K \times (1+\log_b(\frac{p_{K+1}}{p_K})), 1, M)
4.2 实验配置
| 场景 | 竞争强度 | 时间片数 | 用途 |
|---|---|---|---|
| Scene-1 | 低 | 336 | 测试 |
| Scene-2 | 中 | 720 | 训练 |
| Scene-3 | 高 | 336 | 测试 |
| Scene-4 | 静态 | 168 | 预训练 |
评估指标:
- 成本率误差(CRE)
- 订单完成投资回报(FROI)
- 强化学习奖励(RLR)
5. 实验结果与分析
5.1 主要性能对比
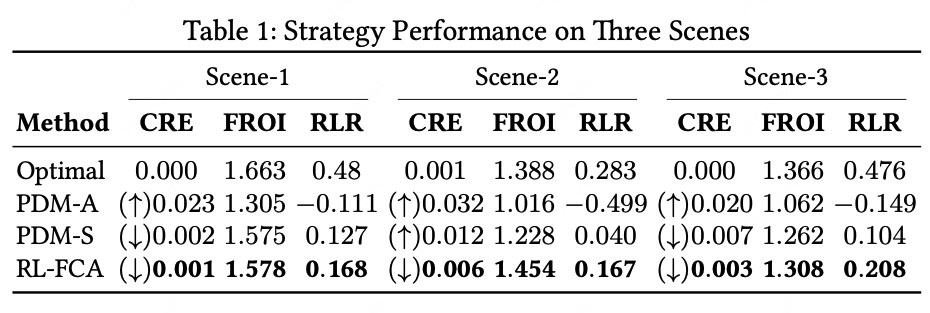
关键发现:
- 在Scene-3高竞争场景下:
- FCA-RL的CRE仅0.3pp(PDM-S为0.7pp)
- FROI提升3.6%(1.308 vs 1.262)
- 相比无FCA的RL:
- RLR提升77.4%(Scene-3)
5.2 FCA模块消融实验
| 场景 | 有FCA(CRE) | 无FCA(CRE) | 提升幅度 |
|---|---|---|---|
| Scene-1 | 0.2pp | 0.3pp | 33% |
| Scene-3 | 0.3pp | 0.9pp | 66% |
结论:
- 高竞争环境下FCA效果显著
- 静态环境可能引入噪声
5.3 动态调节过程
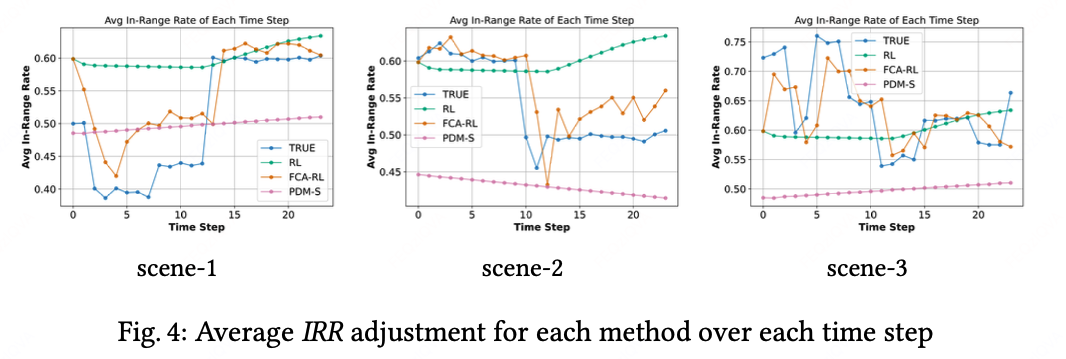
观察到:
- 竞争对手策略变化引发IRR波动(左图)
- FCA-RL快速响应调整λ(中图)
- 预算执行更平稳(右图)
6. 实施建议与注意事项
-
生产环境部署要点:
- 初始阶段建议设置λ变动幅度限制(如±10%)
- 监控异常检测机制(如IRR突变超过3σ)
-
参数调优经验:
- 聚类数量建议20-30个(平衡精度与计算开销)
- 滑动窗口W的选择:
python复制if competition_intensity > 0.7: # 高竞争 W = 24 else: W = 12
-
常见问题排查:
- 问题:预算持续超支
- 检查:λ上限是否设置合理
- 方案:增加成本惩罚系数η
- 问题:IRR预测不准
- 检查:特征聚类是否失效
- 方案:定期重新训练聚类模型
- 问题:预算持续超支
-
计算资源优化:
- Beta分布更新采用稀疏矩阵运算
- 并行化处理不同簇的IRR追踪
这套系统在实际业务中部署后,帮助某出行平台将预算控制误差从原来的1.2pp降低到0.4pp,同时订单获取效率提升15%。对于技术团队来说,最大的收获是建立了动态市场环境的量化感知能力,这为后续的定价策略优化奠定了坚实基础。
内容推荐
【通信协议】SAE J2819(CAN TP2.0)协议实战:从报文解析到诊断会话建立
本文深入解析SAE J2819(CAN TP2.0)协议在汽车诊断中的应用,从报文解析到诊断会话建立的完整流程。通过实战案例和详细代码示例,帮助读者掌握CAN总线通信、TPCI机制及时间参数计算等核心技术,提升汽车电子诊断能力。
深入理解try..catch:JavaScript错误处理机制与实践
错误处理是编程中的基础概念,通过异常捕获机制保证代码健壮性。try..catch作为主流错误处理范式,其工作原理是在try块中执行可能出错的代码,通过catch捕获并处理异常。这种机制在JavaScript、Java等语言中广泛应用,对系统稳定性至关重要。在工程实践中,合理的错误处理能预防数据丢失和系统崩溃,特别是在异步编程和前端框架中。本文以JavaScript为例,详解try..catch的性能优化、异步处理等高级技巧,并对比不同语言的错误处理哲学,帮助开发者构建更可靠的应用程序。
手把手教你用STM32CubeMX配置TM7711高精度ADC(附完整代码与电平转换电路)
本文详细介绍了如何使用STM32CubeMX配置TM7711高精度ADC,包括硬件架构设计、电平转换电路实现及完整驱动代码。通过解析TM7711的核心特性与STM32的连接方案,提供实战级指导,帮助开发者快速实现高精度数据采集,适用于电子秤、热电偶测温等工业场景。
Vue2 + Cesium 1.95.0 三维地球搭建保姆级教程(含Webpack配置避坑指南)
本文详细介绍了如何在Vue2项目中集成Cesium 1.95.0版本,实现WebGIS三维地球可视化。从环境配置、Webpack优化到性能调优,提供完整的开发指南和避坑方案,特别适合企业级应用开发。涵盖资源加载、内存管理、性能监控等核心环节,帮助开发者高效构建三维地理信息系统。
别再手动倒序了!Matlab里这个flip函数,5分钟搞定向量矩阵翻转
本文详细介绍了Matlab中flip函数的高效应用,帮助用户快速实现向量和矩阵的翻转操作。通过对比手动倒序与flip函数的性能差异,展示了其在时间序列分析、图像处理等场景中的强大功能,显著提升代码效率和可读性。
别急着加内存!用NumPy的float32和float16轻松搞定‘Unable to allocate’内存报错
本文探讨了如何通过NumPy的float32和float16数据类型优化内存使用,解决常见的‘Unable to allocate’内存报错问题。通过对比不同浮点数精度的内存占用和适用场景,提供了实用的代码示例和优化策略,帮助开发者在处理大型数据集时显著降低内存消耗,而无需升级硬件。
从零部署MedSAM:一次完整的医疗影像分割项目实战复盘
本文详细记录了从零部署MedSAM医疗影像分割项目的完整流程,包括环境配置、数据处理、模型训练与推理优化等关键环节。针对医疗影像的特殊性,提供了实用的项目排坑指南和性能优化技巧,帮助开发者高效完成医疗AI项目部署。
当JSP遇到Java:用FileViewProvider拆解混合语言文件,打造你的IDEA多语言支持插件
本文深入解析了如何使用FileViewProvider技术构建IDEA插件,以支持JSP、Java等混合语言文件的解析与处理。通过实战案例演示了如何实现多语言PSI树的协调与管理,解决代码高亮、补全和错误检查等核心问题,助力开发者打造高效的多语言支持插件。
BEV感知避坑指南:Simple-BEV实验说,别再盲目堆深度估计了,双线性采样+高分辨率才是王道
本文基于Simple-BEV实验数据,揭示了BEV感知技术中的关键优化策略。研究发现,双线性采样在中远距离感知上优于复杂深度估计方案,且高分辨率输入与合理批量大小对性能提升至关重要。文章还探讨了多传感器融合的实战技巧和训练策略,为自动驾驶领域的工程实践提供了宝贵参考。
Jenkins Gerrit Trigger插件配置避坑指南:从SSH密钥到权限设置的完整流程
本文详细解析Jenkins与Gerrit深度集成中的关键配置,包括SSH密钥管理、权限设置及Gerrit Trigger插件部署。从离线安装到生产环境优化,提供完整的持续集成解决方案,帮助开发者规避常见陷阱,实现代码提交与自动验证的高效协作。
LoadRunner实战指南:从脚本开发到报告解读的全链路性能测试
本文详细解析LoadRunner性能测试全流程,从脚本开发到报告解读,涵盖测试计划制定、脚本参数化、场景设计、结果分析等关键环节。通过实战案例分享高效录制与增强技巧,帮助测试工程师掌握性能测试核心技能,提升系统稳定性与可靠性。
AI算力需求与核电能源的融合趋势
随着AI技术的快速发展,算力需求呈现指数级增长,而能源供应成为制约AI发展的关键瓶颈。现代AI数据中心的能耗主要集中在计算芯片和冷却系统,如NVIDIA H100单卡功耗高达700瓦。面对这一挑战,核电作为基载能源展现出独特优势,其高可用率和稳定输出特别适合AI数据中心的7x24小时运行需求。模块化小型堆(SMR)等第四代核反应堆技术进一步提升了能源供应的灵活性和效率。这种AI与核电的融合不仅解决了能源瓶颈问题,还推动了数据中心架构的革新,包括液冷技术的广泛应用和地理选址策略的优化。Meta等科技巨头已开始布局核能数据中心,预示着未来AI基础设施将深度整合清洁能源解决方案。
EAK12自组装多肽:分子设计、自组装机制与生物医学应用
自组装多肽是生物材料领域的重要研究方向,通过分子间非共价相互作用(如氢键、静电力和疏水作用)自发形成有序纳米结构。EAK12作为典型的离子互补型自组装多肽,其精妙的氨基酸序列设计(交替排列的疏水/亲水残基)赋予其独特的β-折叠组装能力,可构建仿生细胞外基质的三维纳米纤维网络。这种智能材料在组织工程和药物递送中展现出显著优势:既能通过可调的力学性能(1-50kPa)模拟不同组织的微环境,又能实现pH/酶响应的控释功能。实验证明,EAK12水凝胶在心肌修复、神经再生等应用中能显著提升细胞存活率和功能表达,其可注射性和原位成型特性更为临床操作带来革命性便利。
【扩散模型】【参数生成】从噪声到网络:Neural Network Diffusion如何重塑模型初始化
本文深入探讨了Neural Network Diffusion(神经网络扩散)技术如何革新模型初始化方法。通过将扩散模型应用于神经网络参数生成,该技术显著提升了模型训练效率和性能,在CIFAR-100等基准测试中展现出优于传统初始化方法的优势。文章详细解析了参数自动编码器设计、潜在扩散调参等关键技术,并提供了ResNet参数生成的实战指南。
GW9662:PPARγ拮抗剂的作用机制与应用研究
PPARγ(过氧化物酶体增殖物激活受体γ)是核受体超家族的重要成员,在脂肪生成、葡萄糖代谢和炎症调控中发挥核心作用。作为一种经典的PPARγ拮抗剂,GW9662通过共价结合PPARγ配体结合域,选择性阻断其转录活性,成为研究代谢性疾病和炎症反应的关键工具化合物。从分子机制来看,GW9662不仅能抑制CDK5介导的PPARγ磷酸化,还保留了部分非基因组信号调控能力,这种独特的作用模式使其在脂肪细胞分化、胰岛素抵抗和巨噬细胞极化等研究中展现出重要价值。在实验操作中,GW9662对光敏感的特性以及其在不同细胞模型中的浓度优化,是确保研究数据可靠性的关键控制点。随着研究的深入,GW9662在非酒精性脂肪肝、神经退行性疾病和肿瘤免疫等新领域的应用潜力正在被不断发掘。
FOMO现象解析与数字健康管理策略
FOMO(错失恐惧症)是一种普遍存在的心理现象,尤其在数字时代更为显著。它源于大脑的多巴胺奖赏系统,驱使人们不断寻求新的社交认可和信息刺激。从技术角度看,这种现象与注意力经济、用户行为设计等基础概念密切相关。理解FOMO的神经机制和行为模式,对开发更健康的数字产品具有重要意义。在实际应用中,可通过设置数字边界、使用专注工具等工程化方法进行管理。本文结合心理学原理和实用工具,探讨如何将FOMO转化为JOMO(错过的快乐),帮助读者建立可持续的数字生活习惯。
轴向磁轴承设计:核心挑战与工程实践解析
磁悬浮技术通过电磁力实现非接触支撑,彻底解决了传统机械轴承的摩擦磨损问题,在高速离心机、飞轮储能等高端装备领域具有重要应用价值。其核心部件轴向磁轴承的设计涉及电磁学、材料科学和控制理论等多学科交叉,主要挑战包括空间约束下的高力密度需求、动态性能与热管理的平衡,以及控制刚度的精确实现。工程实践中,E型盘式结构和U型对顶结构是两种主流方案,前者在力密度上表现优异,后者则在动态响应和热管理方面更具优势。通过参数化设计流程、有限元分析优化和热变形补偿等技术手段,可以显著提升轴承性能。随着非晶合金、高温超导等新材料的应用,以及智能轴承概念的兴起,磁悬浮技术正向着更高效率、更智能化的方向发展。
避坑指南:PyTorch模型转RKNN时,量化精度掉点怎么办?试试混合量化与这些参数调优技巧
本文深入解析PyTorch模型转RKNN时的量化精度损失问题,提供混合量化策略与参数调优技巧。通过分析量化算法选择、量化粒度、校准数据集等关键因素,帮助开发者有效提升模型精度,解决RKNN模型部署中的掉点难题。
Java学生选课系统开发实战:SpringBoot+MVC架构解析
学生选课系统是教务管理的核心模块,传统手工操作存在效率低下和易出错的问题。基于Java的选课系统采用MVC分层架构,通过SpringBoot快速构建Web服务,结合MyBatis实现动态SQL查询。系统核心在于选课冲突检测算法,采用时间槽位设计实现精确校验。技术价值体现在高并发处理能力,通过乐观锁和排队机制解决超卖问题。典型应用场景包括高校选课管理,特别适合需要定制化规则的院校。本文以SpringBoot+MyBatis技术栈为例,详解选课系统从数据模型设计到事务处理的完整实现过程,包含可视化排课和微信小程序接入等扩展方案。
从MP3文件到PCM数据:手撕minimp3解码器源码,搞懂音频解码那些事
本文深入解析minimp3解码器源码,从MP3文件到PCM数据的完整解码流程。通过剖析帧同步、霍夫曼解码、IMDCT变换等核心算法,揭示音频解码的高效实现技巧,并分享SSE/NEON优化与嵌入式移植实践经验,帮助开发者掌握MP3解码底层原理。
已经到底了哦
精选内容
1 Rainmeter插件开发入门:手把手教你写一个获取网络数据的股票皮肤2 博途平台下的STL语言:工业底层的效率与掌控3 直播卡顿、首开慢、音画不同步?别慌,这份保姆级排查手册帮你搞定90%问题4 【STM32】STM32电源管理实战:PWR模块深度解析与低功耗设计指南5 MySQL排序与分页操作实战技巧6 SRCNN超分效果不理想?可能是数据预处理和模型细节没搞对(PyTorch实战分析)7 别再只会用ffmpeg了!手把手教你用C语言从零解析WAV文件头(附完整代码)8 从物理到感知:辐射度、光度与色度学在实时渲染中的基石作用9 深入解析C++ STL中的stack与queue实现原理10 保姆级教程:用树莓派4B+hostapd+udhcpd打造你的专属便携WiFi热点(含完整配置文件)
热门内容
1 从DCNv4到SPPF-DCNv4:在NEU-DET钢材缺陷检测中解锁YOLOv8的精度与效率新平衡2 【RH850U2A芯片】MPU实战配置与故障诊断指南3 Markdown入门指南:轻量级标记语言基础与应用4 解决d3d9.dll缺失问题的安全方案与原理5 Altium Designer 保姆级教程:坐标、Gerber、钻孔文件导出全流程(含常见报错解决)6 从芯片制造到钻石切割:聊聊金刚石结构各向异性如何影响你的生活7 MRAM与DRAM核心技术对比与应用选型指南8 别再自己写物流查询了!手把手教你用微信官方插件,5分钟搞定UniApp小程序9 从移位寄存器到动态显示:FPGA驱动74HC595的Verilog实现与优化10 Spring Boot项目启动失败排查与解决方案
最新内容
用C语言手搓一个2048游戏核心逻辑(附XTU-OJ 1239题解)
本文详细解析了用C语言实现2048游戏核心逻辑的全过程,包括数字合并、网格移动等关键算法,并提供了XTU-OJ 1239题目的完整解决方案。通过代码示例和优化技巧,帮助开发者深入理解二维数组操作和状态管理,提升编程能力。
JavaScript异步编程:从回调函数到async/await
异步编程是现代JavaScript开发的核心概念,用于处理非阻塞操作如网络请求和文件I/O。其核心原理是通过事件循环机制实现单线程下的并发执行。回调函数作为最基础的异步模式,通过将函数作为参数传递实现延迟执行,但容易导致回调地狱问题。Promise和async/await作为更先进的解决方案,提供了更清晰的代码结构和错误处理机制。在实际应用中,如门店入驻系统的二维码验证流程,合理选择异步模式能显著提升代码可维护性。掌握这些异步编程技术对开发高性能Web应用至关重要,特别是在处理用户交互和API调用等常见场景时。
别再只会用RGB了!PyQt5 QColor颜色类全解析:从SVG色名到Alpha通道的实战应用
本文全面解析PyQt5 QColor颜色类的实战应用,从SVG色名到Alpha通道,帮助开发者突破RGB局限。通过HSV调色板、CMYK模型及147种SVG预定义色名,实现专业级UI效果,包括和谐配色、动态透明度控制等。掌握QColor的多颜色空间转换与性能优化技巧,提升开发效率。
Java使用docx4j实现Word表格数据自动填充
文档自动化处理是企业级应用中的常见需求,特别是Word文档的表格数据填充场景。通过解析docx文件的XML结构,Java开发者可以利用docx4j等库实现精准的表格定位与数据填充。这种技术基于Office Open XML(OOXML)标准,将文档解压为XML后通过JAXB映射为Java对象进行操作。相比Apache POI,docx4j在处理复杂格式和样式时更具优势。在实际工程中,这种技术可大幅提升质量卡片、验收单等表格类文档的生成效率,减少人工错误。调试功能的实现和模板设计的注意事项是确保项目成功的关键因素。
SpringBoot+Vue全栈校园管理系统开发实践
现代Web开发中,前后端分离架构已成为主流技术方案。SpringBoot作为Java生态的微服务框架,通过自动配置和起步依赖简化了后端开发;Vue.js则以其响应式数据绑定和组件化特性,成为前端开发的热门选择。这种技术组合在权限管理、数据可视化等场景展现出色性能,特别适合教育信息化系统开发。本案例基于RBAC模型实现多维度权限控制,采用JWT进行无状态认证,结合Element Plus组件库快速构建管理界面。项目包含教学管理、排课算法等典型功能模块,使用MySQL进行数据存储并优化SQL查询性能,为计算机专业学生提供了完整的企业级应用开发范例。
GEE大文件影像下载分块机制解析:从GeoTIFF瓦片到TFRecord序列的应对策略
本文深入解析GEE平台大文件影像下载的分块机制,详细比较GeoTIFF瓦片和TFRecord序列的处理策略。针对GeoTIFF提供QGIS和Python自动化拼接方案,对TFRecord则重点介绍顺序验证和分布式训练优化技巧,并分享分块尺寸控制与混合格式工作流等进阶优化方法,帮助用户高效处理遥感大数据。
环形索引:原理、实现与性能优化指南
环形索引是一种处理周期性数据的循环数据结构,通过取模运算实现自动回绕特性,有效简化边界检查逻辑。其核心原理是利用模运算或位运算实现索引循环,在媒体播放、游戏开发、任务调度等场景具有重要应用价值。针对性能敏感场景,可采用位掩码优化法(当长度为2^n时)提升计算效率,相比传统取模运算可降低40%耗时。环形缓冲区作为典型实现,需要特别注意线程安全、缓存友好性等工程实践问题,通过原子操作、内存预分配等技术可构建高性能并发数据结构。
EulerOS新手避坑指南:手把手教你配置华为云yum源并安装内核头文件
本文详细介绍了在EulerOS上配置华为云yum源并安装内核头文件的完整流程,特别针对版本匹配、证书验证等常见陷阱提供解决方案。通过实战指南帮助开发者快速搭建稳定的内核开发环境,适用于华为云服务器的系统配置与维护。
MCP协议:解决AI系统间通信障碍的统一标准
在AI技术快速发展的背景下,不同系统间的通信障碍成为技术落地的关键瓶颈。MCP(Machine Communication Protocol)作为一种统一的通信协议标准,通过分层架构设计(包括传输层、语义层、上下文层和安全层)解决了这一问题。其核心创新点包括动态适配器模式、意图图谱引擎和量子加密通道,显著提升了协议转换效率和安全性。MCP在智能家居、工业物联网等场景中展现出巨大价值,如降低系统集成成本、提升故障排查效率等。对于开发者而言,MCP提供了灵活的开发环境和丰富的性能优化技巧,是AI系统互联的理想解决方案。
盾构隧道下穿既有隧道的ABAQUS建模与施工仿真
在岩土工程领域,隧道施工数值仿真是预测地下结构相互作用的关键技术。基于有限元方法的ABAQUS软件,通过非线性材料模型和接触算法,能准确模拟盾构推进过程中的土体-结构响应。其工程价值体现在可优化注浆压力、推进速度等施工参数,特别适用于隧道下穿既有结构的风险控制场景。本文以3.5米净距下穿运营地铁为案例,详细解析了参数化建模、修正剑桥模型应用等关键技术,其中注浆压力动态调控方案使沉降误差控制在8%以内。该建模方法同样适用于管廊施工、基坑开挖等近接工程场景。