Python地理空间分析:geopandas矢量数据处理实战

十一爱吃瓜
1. 矢量数据空间分析基础与geopandas环境配置
作为一名长期从事地理信息处理的开发者,我深刻理解矢量数据空间分析在实际项目中的重要性。无论是城市规划、自然资源管理还是商业选址分析,正确处理矢量数据的空间关系都是基础中的基础。Python生态中的geopandas库将地理空间数据处理能力与pandas的数据操作优势完美结合,成为我们日常工作的利器。
1.1 为什么选择geopandas进行空间分析
传统GIS软件如ArcGIS虽然功能强大,但在自动化处理和批量操作方面存在明显局限。geopandas基于Python生态,具有以下不可替代的优势:
- 脚本化操作:可记录和复现整个分析流程
- 无缝衔接数据科学生态:与numpy、pandas、matplotlib等库完美配合
- 开源免费:避免商业软件授权问题
- 高性能处理:底层依赖shapely和fiona等高性能库
提示:geopandas本质上是pandas的扩展,所以熟悉pandas的数据框操作会极大提升geopandas的使用效率。
1.2 环境安装与配置要点
建议使用conda管理地理空间分析环境,可以避免依赖冲突:
bash复制conda create -n geo python=3.8
conda activate geo
conda install -c conda-forge geopandas matplotlib descartes
实测中发现,从conda-forge渠道安装比pip安装更稳定,特别是处理空间投影相关操作时。descartes库虽然不是必须的,但它能优化matplotlib绘制几何图形的效果。
2. 投影转换:空间分析的首要步骤
2.1 理解坐标系的核心概念
在进行任何空间分析前,确保所有数据在同一坐标系下是基本要求。常见坐标系主要分为两类:
-
地理坐标系(Geographic CRS)
- 以经纬度表示位置(如WGS84)
- 单位是度,不适合直接测量距离和面积
-
投影坐标系(Projected CRS)
- 将球面投影到平面(如Web墨卡托)
- 单位是米,可进行精确测量
python复制# 查看当前投影
print(gdf.crs) # 输出示例:EPSG:4326(WGS84地理坐标系)
2.2 实战投影转换流程
以下是一个完整的重投影案例,包含了我工作中总结的最佳实践:
python复制import geopandas as gpd
# 路径处理建议使用pathlib更安全
from pathlib import Path
shp_path_tar = Path(r'data/上海市行政区划矢量文件/上海市.shp')
shp_path = Path(r'data/vector/road.shp')
out_put = Path(r'output/road_proj.shp')
# 读取时指定编码可避免中文乱码
gdf_tar = gpd.read_file(shp_path_tar, encoding='gbk')
gdf = gpd.read_file(shp_path, encoding='gbk')
# 检查并统一坐标系
if gdf.crs != gdf_tar.crs:
print(f'需要进行投影转换:{gdf.crs} -> {gdf_tar.crs}')
gdf_proj = gdf.to_crs(gdf_tar.crs)
else:
print('坐标系一致,无需转换')
gdf_proj = gdf.copy()
# 保存时创建父目录
out_put.parent.mkdir(parents=True, exist_ok=True)
gdf_proj.to_file(out_put, encoding='utf-8')
关键注意事项:
- 实际项目中应先检查CRS是否为空(
gdf.crs is None),空CRS需要先定义 - 跨大区域数据转换应考虑使用适当的投影(如Albers等面积投影)
- 转换后建议验证几何有效性:
gdf_proj.geometry.is_valid.all()
3. 矢量裁剪:精准提取区域数据
3.1 裁剪的两种典型场景
-
硬裁剪(Hard Clip):完全保留裁剪区域内的要素
python复制
road_clip = gpd.clip(gdf=road, mask=mask) -
软裁剪(Soft Clip):保留与裁剪区域相交的要素
python复制
road_intersect = road[road.intersects(mask.unary_union)]
3.2 完整裁剪案例与性能优化
python复制import geopandas as gpd
from time import time
def efficient_clip(input_gdf, mask_gdf, attribute=None, value=None):
"""带属性筛选的高效裁剪函数"""
t_start = time()
# 先进行属性筛选减少数据量
if attribute and value:
mask = mask_gdf[mask_gdf[attribute] == value]
else:
mask = mask_gdf
# 确保mask是单一几何体
if len(mask) > 1:
mask = mask.unary_union
# 执行裁剪
result = gpd.clip(input_gdf, mask)
print(f'裁剪完成,耗时:{time()-t_start:.2f}秒')
return result
# 使用示例
boundary = gpd.read_file('data/上海市行政区划矢量文件/上海市.shp')
roads = gpd.read_file('data/vector/roads/gis_osm_roads_free_1.shp')
# 只裁剪闵行区的道路
minhang_roads = efficient_clip(
roads, boundary,
attribute='district',
value='闵行区'
)
minhang_roads.to_file('output/road_clip.shp')
性能优化技巧:
- 大文件裁剪前先用
boundary.envelope创建最小外包矩形进行初步筛选 - 对多个区域循环裁剪时,预先构建空间索引:
python复制from rtree import index idx = index.Index() for pos, geom in enumerate(boundary.geometry): idx.insert(pos, geom.bounds)
4. 矢量融合:聚合地理要素
4.1 融合操作的业务意义
矢量融合不仅是几何合并,更是属性聚合的过程。典型应用场景包括:
- 行政区划合并(多个乡镇合并为县)
- 土地利用类型汇总
- 统计相同类型POI的分布区域
4.2 高级融合技巧
python复制import geopandas as gpd
sh = gpd.read_file('data/上海市行政区划矢量文件/上海市.shp')
# 多字段组合+不同聚合方式
dissolve_dict = {
'area': 'sum', # 面积求和
'population': 'mean', # 人口取平均
'name': 'first' # 保留第一个名称
}
sh_province = sh.dissolve(
by=['Id', 'citycode'],
aggfunc=dissolve_dict,
as_index=False # 将by字段保留为列
)
# 处理融合后可能出现的多部件几何体
sh_province['geometry'] = sh_province.geometry.buffer(0)
sh_province.to_file('output/shanghai.shp')
常见问题处理:
- 融合后出现无效几何体:
.buffer(0)可以修复大部分问题 - 保留所有属性字段:
aggfunc='first'或aggfunc='last' - 融合边界缝隙:先执行
buffer(0.0001)再融合
5. 叠置分析:空间关系深度挖掘
5.1 五种叠置操作对比
| 操作类型 | 方法 | 描述 | 图示示例 |
|---|---|---|---|
| 联合(Union) | how='union' |
所有输入几何的并集 | 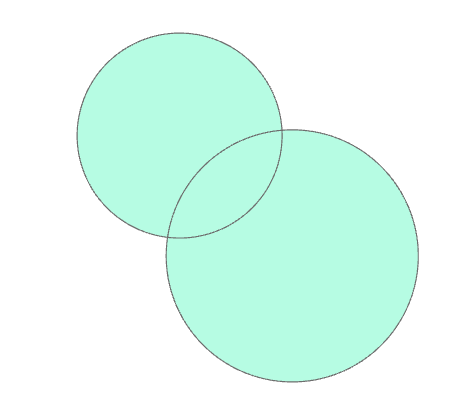 |
| 相交(Intersection) | how='intersection' |
几何的交集部分 |  |
| 差异(Difference) | how='difference' |
df1有而df2没有的部分 |  |
| 对称差(Symmetric Diff) | how='symmetric_difference' |
只在一个几何中的部分 | 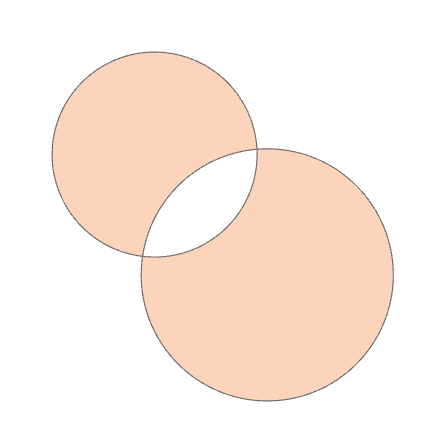 |
| 标识(Identity) | how='identity' |
df1几何与df2的并集 | - |
5.2 叠置分析实战案例
python复制import geopandas as gpd
def overlay_analysis(df1_path, df2_path, output_dir):
"""执行全套叠置分析并保存结果"""
df1 = gpd.read_file(df1_path)
df2 = gpd.read_file(df2_path)
# 确保坐标系一致
if df1.crs != df2.crs:
df2 = df2.to_crs(df1.crs)
# 执行所有叠置操作
operations = {
'union': gpd.overlay(df1, df2, how='union'),
'intersection': gpd.overlay(df1, df2, how='intersection'),
'difference_A-B': gpd.overlay(df1, df2, how='difference'),
'difference_B-A': gpd.overlay(df2, df1, how='difference'),
'symmetric_difference': gpd.overlay(df1, df2, how='symmetric_difference')
}
# 保存结果
output_dir = Path(output_dir)
output_dir.mkdir(exist_ok=True)
for name, result in operations.items():
if not result.empty: # 过滤空结果
result.to_file(output_dir / f'{name}.shp')
print(f'分析结果已保存至:{output_dir}')
# 使用示例
overlay_analysis(
'data/vector/circle/circle1.shp',
'data/vector/circle/circle2.shp',
'output/overlay_results'
)
高级应用技巧:
- 叠置前使用
prepare方法提升性能:python复制
df1.geometry = df1.geometry.prepare() df2.geometry = df2.geometry.prepare() - 处理大型数据时考虑分块处理
- 叠置结果属性表会自动保留两个输入图层的字段,建议重命名避免混淆
6. 常见问题排查与性能优化
6.1 典型错误与解决方案
| 错误类型 | 可能原因 | 解决方案 |
|---|---|---|
| CRS不匹配 | 未统一坐标系 | 检查并转换CRS:gdf1.crs == gdf2.crs |
| 无效几何 | 数据源问题 | gdf.geometry = gdf.geometry.buffer(0) |
| 内存不足 | 数据量太大 | 使用分块处理或Dask-GeoPandas |
| 属性丢失 | 融合参数不当 | 明确指定aggfunc参数 |
| 裁剪异常 | 几何类型不一致 | 确保裁剪mask为面,被裁剪数据为点/线/面 |
6.2 性能优化实战建议
-
空间索引加速查询:
python复制import rtree idx = rtree.index.Index() for pos, geom in enumerate(gdf.geometry): idx.insert(pos, geom.bounds) -
并行处理大型操作:
python复制from multiprocessing import Pool def parallel_overlay(args): gdf1_chunk, gdf2 = args return gpd.overlay(gdf1_chunk, gdf2, how='intersection') # 分块处理 chunks = [gdf1.iloc[i:i+1000] for i in range(0, len(gdf1), 1000)] with Pool(4) as p: results = p.map(parallel_overlay, [(chunk, gdf2) for chunk in chunks]) final_result = gpd.GeoDataFrame(pd.concat(results), crs=gdf1.crs) -
使用Dask加速大数据处理:
python复制import dask_geopandas as dgpd ddf = dgpd.from_geopandas(gdf, npartitions=4) result = ddf.clip(mask).compute()
在实际项目中,我通常会先对小样本数据测试流程,确认无误后再应用这些优化策略处理完整数据集。记住,空间分析既是科学也是艺术,需要根据具体数据和业务需求灵活调整方法。
内容推荐
H800 SXM与PCIe性能差异解析及AI训练优化
GPU间通信效率是AI模型训练的关键瓶颈,特别是在大规模参数模型如GPT-3中。NVLink作为专用高速互连技术,通过高带宽和全连接拓扑显著提升性能,而PCIe则因共享总线和协议转换开销存在局限。实测数据显示,SXM架构在ResNet50训练和GPT-3 175B训练中分别提升27%和52%性能。对于大模型训练和高频通信负载,SXM架构更具优势,而PCIe适用于成本敏感型项目。合理配置NVLink固件和拓扑感知调度可最大化SXM性能,而NUMA绑定和PCIe Lane分配则优化PCIe系统。未来NVLink-C2C和PCIe 6.0技术将进一步提升带宽,但SXM架构在未来兼容性上更具优势。
React项目国际化实战:i18next快速实现多语言支持
国际化(i18n)与本地化(l10n)是现代Web开发中的重要技术,通过分离UI文本与业务逻辑,使应用能适配不同语言和地区。其核心原理包括翻译资源管理、动态加载和区域格式处理,技术价值在于提升产品全球可用性。常见应用场景包括电商平台、SaaS系统等需要多语言支持的场景。本文以React项目为例,详细介绍如何使用i18next框架快速实现国际化功能,涵盖从基础配置到RTL语言支持等进阶技巧。通过i18next的模块化设计和react-i18next的深度集成,开发者可以轻松处理文本翻译、复数形式和日期本地化等需求,同时利用i18next-http-backend实现翻译资源的按需加载。
SSM+Vue考研服务平台架构设计与实现
现代Web应用开发中,SSM(Spring+SpringMVC+MyBatis)与Vue.js的组合已成为主流技术栈,尤其适合构建数据驱动的中大型系统。其核心原理在于前后端分离架构,通过RESTful API实现数据交互,利用Vue的响应式特性和SSM的IoC容器管理,显著提升开发效率和系统可维护性。在考研服务这类信息聚合场景下,该技术组合能有效解决数据异构性和实时交互需求,例如通过Redis缓存热点院校数据,结合WebSocket实现低延迟咨询。典型应用还包括采用混合推荐算法(内容过滤+协同过滤)提升匹配精度,以及利用Docker容器化部署保证环境一致性。这些实践充分体现了现代Web技术在高并发、高可用系统中的工程价值。
SpringBoot+Vue高校选课系统设计与高并发优化
选课系统是教务管理中的核心模块,其本质是通过分布式事务保证数据一致性的在线事务处理系统。传统系统常面临高并发下的性能瓶颈,现代方案通常采用前后端分离架构,结合Redis缓存和数据库锁机制解决资源竞争问题。SpringBoot凭借自动配置和嵌入式容器特性,能快速构建RESTful服务;Vue.js通过响应式数据绑定实现流畅交互。在高校选课场景中,关键技术点包括:基于JWT的认证授权、乐观锁防止超选、令牌桶算法限流等。典型优化手段如MySQL索引优化、连接池配置、读写分离等,可将系统吞吐量提升5倍以上。该架构同样适用于其他需要强一致性的预约类系统开发。
2026年AI论文降重工具实测与学术写作优化方案
随着自然语言处理技术的进步,AI生成文本检测已成为学术诚信领域的重要课题。基于深度学习的语义分析技术通过文本指纹比对和写作模式识别,能有效区分人工写作与AI生成内容。以维普为代表的检测系统已实现89.7%的识别准确率,这对学术写作提出了新的技术要求。在实际应用中,结合BERT变体模型的语义重构引擎和学术特征强化模块,可显著降低文本的AI特征值。测试数据显示,专业降重工具能使AI生成内容识别率从60%降至10%以下,尤其在法学、医学等专业领域效果显著。合理运用分阶段处理、参数优化等技巧,配合最终人工润色,是确保学术论文通过检测的关键策略。
热电联产系统选址定容优化与Matlab实现
热电联产(CHP)系统通过同时产生电能和热能实现能源梯级利用,是提升能源效率的关键技术。其核心原理在于将发电余热回收利用,使综合能效可达70%以上,远高于传统分供系统。在工程实践中,CHP系统的选址定容优化涉及负荷预测、设备建模、管网设计和多目标优化等关键技术,需要解决空间布局、容量配置和运行策略等耦合问题。Matlab凭借其强大的数值计算和优化工具箱,成为实现CHP系统量化分析的重要工具,可通过遗传算法、混合整数规划等方法求解复杂优化问题。典型应用场景包括工业园区、医院和区域能源站等,其中负荷特性分析、管网成本计算和不确定性处理是项目落地的关键环节。
宏智树AI助力学术写作:从文献检索到论文成稿
在学术写作领域,文献检索与数据可视化是研究者面临的两大核心挑战。传统方法需要手动筛选海量文献,并掌握SPSS、R等专业工具,学习曲线陡峭。AI技术的引入改变了这一局面,通过自然语言处理与机器学习算法,智能工具能自动对接核心期刊数据库,实现精准文献推荐;同时支持多种数据格式导入,自动生成符合学术规范的图表。宏智树AI作为专业学术辅助工具,其核心优势在于整合了SCI/SSCI文献库与动态图表生成功能,显著提升研究效率。该工具特别适合学位论文写作与SCI投稿场景,通过全流程智能化支持,帮助研究者将更多精力投入创新性思考。
字符频次统计的7种实现方法与面试技巧
字符频次统计是编程基础中的经典问题,通过哈希表等数据结构实现高效计数。其核心原理是利用键值对存储字符与出现次数的映射关系,时间复杂度通常为O(n)。该技术在数据处理、文本分析等领域有广泛应用,如日志分析、词频统计等场景。针对不同编程语言,Python可用collections.Counter优化,Java适合HashMap实现,JavaScript可采用reduce方案。面试时需注意处理Unicode字符、并行计算等进阶问题,同时要关注defaultdict等工具类对代码简洁度的提升。
快速选择算法:高效查找第K大元素的原理与实践
选择算法是计算机科学中解决查找问题的关键技术,其中快速选择算法(Quickselect)因其高效性被广泛应用。该算法基于快速排序的分区思想,通过每次迭代缩小搜索范围,将平均时间复杂度优化至O(n)。其核心在于分区操作,通过随机化pivot选择避免最坏情况,适用于大数据量场景下的Top K问题求解。在工程实践中,快速选择常用于统计分析和数据处理,如查找中位数或百分位数。与堆排序相比,它在内存使用上更具优势,特别适合资源受限环境。算法优化技巧包括三路分区处理重复元素、尾递归消除栈溢出风险等,这些方法显著提升了实际应用性能。
莫凡电视:地方台全覆盖与高清播放的技术实现
在数字电视和流媒体技术快速发展的今天,信号处理和终端适配成为提升用户体验的关键技术。通过双模块信号处理架构(DTMB地面波和IPTV流媒体),莫凡电视实现了全国范围内省、市、县三级地方电视台的全覆盖,并保证了高清流畅的播放体验。其核心技术包括多协议解码引擎和智能切换逻辑,支持硬件加速和软件解码优化,显著降低了功耗并提升了播放流畅度。这些技术在智能电视和电视盒子等终端设备上得到广泛应用,特别适合需要地方台节目资源的用户群体。莫凡电视项目还通过Docker容器化部署和自动化频道管理,确保了服务的高可用性和易维护性。
信号处理中的边际谱分析与HHT实现详解
边际谱作为希尔伯特-黄变换(HHT)的核心分析工具,在非平稳信号处理领域展现出独特优势。不同于传统傅里叶变换的全局基函数,HHT通过经验模态分解(EMD)将信号自适应分解为本征模态函数(IMF),再结合希尔伯特变换获取瞬时频率特征。这种时频分析方法特别适用于机械振动、生物医学信号等非线性场景。边际谱通过积分希尔伯特谱得到能量-频率分布,有效解决了传统方法对瞬态特征捕捉不足的问题。在Python实现中,关键步骤包括EMD分解的筛选过程、希尔伯特瞬时频率计算以及频率bin统计,配合适当的端点处理和模态混叠解决方案,可显著提升工程信号分析的准确性。
Spring AI对话记忆持久化实战与优化
对话系统作为人工智能的重要应用场景,其核心在于上下文记忆能力的实现。通过JDBC持久化技术,可以将Spring AI框架中的对话记录从内存存储转为数据库存储,有效解决服务重启导致数据丢失的问题。这种技术方案不仅提升了系统的可靠性,还能支持对话历史查询、分析等进阶功能。在实际工程实践中,需要结合MySQL等关系型数据库的特性进行表结构设计、索引优化和连接池配置。对于高并发场景,可进一步引入Redis缓存和读写分离架构。本文以Spring AI与MySQL的集成为例,详细展示了从环境搭建到生产部署的全流程实现,特别适合需要长期维护对话状态的客服系统、智能助手等应用场景。
SQLite3数据库核心特性与应用实践指南
关系型数据库作为数据持久化的核心技术,通过SQL语言实现数据的结构化存储与高效查询。SQLite3作为轻量级嵌入式数据库引擎,采用无服务器架构将整个数据库存储在单一磁盘文件中,支持完整的ACID事务特性。这种设计使其在移动开发、桌面应用和小型Web系统中展现出独特优势,特别是在资源受限环境下性能表现优异。通过合理的索引设计和事务批处理等优化手段,SQLite3能够处理大多数中小规模数据存储需求,其跨平台兼容性更简化了开发部署流程。在实际工程中,SQLite3常被用于移动端本地存储、应用配置管理以及快速原型开发等场景,结合JSON扩展和自定义函数等高级功能,可以灵活应对半结构化数据处理需求。
SpringBoot智能阅读推荐系统开发与优化实践
推荐系统作为信息过滤的核心技术,通过分析用户历史行为构建个性化推荐模型。其技术原理主要基于协同过滤和内容相似度计算,结合用户画像实现精准匹配。在实际工程中,Java+Python混合架构能有效平衡开发效率与系统性能,其中SpringBoot提供稳定的Web服务支撑,Python微服务则擅长处理算法密集型任务。教育信息化场景下的智能阅读推荐,需要特别关注冷启动问题和响应速度优化,典型方案包括Redis缓存策略和MySQL索引优化。本案例展示的TF-IDF用户画像构建与混合推荐策略,在高校图书馆数字化转型中具有显著应用价值,实测点击率提升27%。
Scikit-learn管道模型:原理、实战与优化技巧
机器学习管道(Pipeline)是工程化落地中的关键技术组件,其核心原理是通过链式封装将数据预处理、特征工程和模型训练等步骤标准化串联。基于有向无环图(DAG)的设计模式,Pipeline不仅实现了数据流转的原子性操作和接口统一,还能有效防止数据泄露问题。在Scikit-learn框架中,通过继承BaseEstimator和TransformerMixin基类,开发者可以构建支持内存缓存、参数隔离的高级管道系统。典型应用场景包括自动化特征工程(如PolynomialFeatures)、异构数据处理(通过ColumnTransformer)以及与GridSearchCV结合的超参数搜索。工程实践中需特别注意内存管理策略(如稀疏矩阵转换)和部署时的版本兼容性问题,这些技巧能显著提升机器学习工作流的可靠性和效率。
从SEO到GEO:AI时代搜索引擎优化的范式转移
搜索引擎优化(SEO)是提升网站在搜索结果中排名的关键技术,通过关键词优化、内容质量提升等手段获取流量。随着生成式AI的崛起,传统SEO正经历向生成引擎优化(GEO)的范式转移。GEO的核心在于让内容成为AI生成答案的可靠来源,涉及结构化数据标记、E-E-A-T原则实践等技术。官网作为权威信源,通过Schema.org结构化数据和深度内容工程,能显著提升被AI引用的概率。在医药、金融等行业,GEO优化已带来200%的AI引用率提升。掌握从关键词融合到知识图谱构建的GEO方法论,将成为企业数字营销的新竞争力。
基于Docker的轻量化CI/CD实施方案详解
持续集成与持续部署(CI/CD)是现代软件开发的核心实践,通过自动化构建、测试和部署流程显著提升交付效率。Docker容器技术凭借其轻量级和隔离性,成为构建CI/CD系统的理想选择。本文详细介绍如何在CentOS7环境下,利用Docker搭建一套资源占用低、部署快速的轻量化CI/CD系统。该方案特别适合中小型团队,包含Docker引擎调优、Portainer可视化运维、Drone核心引擎集成等关键组件,以及Node.js项目实战示例。通过容器化部署和合理的资源限制,可在1核2G服务器上实现稳定运行,为敏捷开发团队提供高性价比的自动化解决方案。
跨境电商商品生命周期管理实战策略
商品生命周期管理(PLM)是跨境电商运营中的核心环节,涉及从产品导入到退市的全过程价值优化。其核心原理是通过数据驱动的阶段策略,动态调整营销、库存和渠道配置,实现利润最大化。在跨境电商场景下,PLM需要应对多平台规则、国际物流和文化差异等独特挑战。典型应用包括导入期的A/B测试、成长期的流量矩阵构建、成熟期的动态定价以及衰退期的创新清仓策略。通过Helium10等工具进行关键词分析,结合RepricerExpress实现智能调价,卖家可显著提升库存周转率并降低退货率。有效的PLM系统能将滞销品占比控制在12%以下,是跨境卖家提升经营效率的关键引擎。
Git SSL证书错误排查与解决方案全指南
SSL证书验证是保障Git HTTPS通信安全的核心机制,其工作原理涉及证书链验证、主机名匹配和有效期检查三个关键环节。在分布式开发和持续集成场景中,正确处理SSL证书问题对保障代码安全传输至关重要。当遇到常见的SSL certificate problem错误时,开发者需要掌握从系统级诊断到Git专属配置的全套解决方案。通过OpenSSL工具链分析证书链完整性、校准系统时间、合理配置http.sslCAInfo等技巧,可有效解决企业代理拦截、自签名证书、中间证书缺失等典型问题。本指南特别针对Windows证书存储权限、MacOS钥匙串冲突等平台特异性问题提供了实战解决方案,并包含自动化检测脚本等工程实践内容。
《龙珠超》动画制作技术解析:从分镜到特效合成
动画制作是一个复杂的技术流程,涉及分镜设计、原画创作、数字着色和特效合成等多个环节。在日式TV动画生产中,分镜阶段需要处理镜头动态和节奏控制,而原画制作则注重关键帧间距和特效预留。数字着色环节常使用定制化系统处理特殊效果,如赛亚人气焰的三层渐变方案。特效合成则依赖专业插件实现光效和碰撞效果。通过模块化分工和标准化模板,动画工业能够高效产出高质量内容。《龙珠超》作为典型案例,展示了如何通过Retas!和After Effects等工具实现复杂的战斗场景制作,其中Houdini预制的流体模拟和Substance Designer生成的地面破碎效果尤为突出。
已经到底了哦
精选内容
1 制造业报价中的五大隐形成本与数字化解决方案2 Python核心数据结构解析与应用实战3 CTF竞赛:计算机专业学生的实战成长之路4 鸿蒙应用开发:高性能列表组件RcList的设计与优化5 2026研究生必备AI学术工具测评与使用指南6 OpenCode插件AI一键安装与配置全攻略7 Spring MVC中@RequestBody与@RequestParam注解详解8 AI如何优化企业内部沟通:智能摘要与协作实践9 5分钟快速配置Nginx静态网站:从入门到优化10 HTML基础入门:从零开始构建网页结构
热门内容
1 HAProxy与Nginx负载均衡实战部署指南2 AI工具如何提升本科生论文写作效率与质量3 30米分辨率全球湿地数据集的技术实现与应用4 SpringBoot+Vue3+MyBatis构建电商系统实战5 CSS Subgrid实战:优化响应式布局的62%代码量6 Postman接口自动化测试实战与CI/CD集成指南7 Spring Boot与Hadoop构建手机销售数据分析系统8 本科生论文AI检测挑战与降AI率工具评测9 BigQuery对话式分析智能体:数据洞察新范式10 QtCreator调试模式下DLL加载问题解决方案
最新内容
Python实现工业设备预测性维护系统开发指南
预测性维护作为工业4.0的核心技术之一,通过实时监测设备状态数据,结合机器学习算法实现故障预警。其技术原理主要基于时序数据分析,包括振动信号采集、特征工程和异常检测等关键环节。相比传统定期维护,这种数据驱动方法可降低30%以上的维护成本。典型的应用场景包括轴承磨损检测、齿轮箱故障预警等旋转机械监测。本文介绍的Python实现方案,采用轻量级架构设计,整合了NumPy信号处理和Scikit-learn机器学习库,特别适合中小型制造企业的数字化转型需求。其中振动频谱分析和Z-Score异常检测算法,能有效识别70%以上的机械故障模式。
人生成长地图:可视化个人发展的动态导航系统
个人发展可视化工具是现代职业规划与自我管理的重要方法,其核心原理是通过多维坐标系统(如能力、资源、环境轴)实现精准定位,结合动态路径演算算法持续优化成长轨迹。这类工具的技术价值在于将抽象的成长目标转化为可量化的指标体系,并运用SMART原则与弹性缓冲带设计确保执行可行性。在应用场景上,特别适合面临职业转型、创业准备或技能升级的群体,能有效解决"知道要努力却找不到方向"的普遍困境。以"人生成长地图"为例,其三维坐标定位系统和里程碑体系设计,配合Notion等数字工具的动态更新功能,为个人发展提供了实时导航支持。实践中,该工具已帮助技术从业者优化技能投资决策,辅助创业者规避盲目转型风险,展现出强大的工程实践价值。
Web集群防火墙配置实战:从基础到高级防护
防火墙作为网络安全的核心组件,通过包过滤和状态检测技术构建网络边界防护体系。其工作原理基于预定义规则集对网络流量进行深度检查与控制,在保障业务连通性的同时有效抵御外部威胁。在Web集群架构中,合理配置防火墙能显著提升系统抗DDoS攻击能力,并通过端口敲门等高级技术实现服务隐蔽。本文以iptables为例,详细解析多网络区域环境下的访问控制策略配置,涵盖基础规则集构建、SYN洪水防御等实战技巧,并给出CentOS/Rocky Linux系统下的性能优化方案与日志监控实践。
SpringBoot+Vue构建农产品电商系统实战
电商系统在现代农业中扮演着重要角色,其核心技术架构通常采用前后端分离模式。SpringBoot作为Java领域的主流后端框架,通过自动配置和起步依赖简化了微服务开发;Vue.js则以其响应式数据绑定和组件化特性,成为前端开发的优选方案。这种技术组合特别适合农产品电商场景,能有效解决库存管理、订单处理等核心业务问题。在实际工程实践中,系统需要处理高并发库存扣减、微信支付对接等典型挑战。本案例展示的中小型果园预售系统,采用MySQL进行数据持久化,通过动态库存管理和采摘日历等特色功能,为农产品线上销售提供了完整解决方案。
Flask+Vue.js构建大学生记账系统全栈开发指南
Web全栈开发是当前企业级应用开发的主流模式,通过前后端分离架构实现高效协作。前端框架Vue.js以其渐进式特性和易用性广受欢迎,配合Element UI等组件库能快速构建响应式界面。后端框架Flask作为Python轻量级解决方案,特别适合快速开发RESTful API接口。JWT认证机制保障了现代Web应用的安全性,而ECharts等可视化库则大大提升了数据展示能力。本案例以大学生记账系统为场景,详细展示了从技术选型到部署上线的完整开发流程,特别适合想学习全栈开发的在校学生参考实践。
Java常用API深度解析:Math、BigDecimal与日期处理实战
在Java开发中,API类库是构建应用程序的基础工具。Math类提供了基础的数学运算功能,如绝对值计算、幂运算和随机数生成,但其浮点数精度问题需要注意。BigDecimal类通过十进制运算解决了浮点数精度问题,特别适用于金融计算等场景。日期时间处理从传统的Date、Calendar类到Java 8引入的新时间API(如LocalDate、LocalDateTime),提供了更安全、更直观的操作方式。理解这些API的设计原理和正确使用方式,能够帮助开发者避免常见陷阱,提升代码质量和性能。本文通过实际示例,深入解析了这些常用API的核心用法和最佳实践。
AI测试工具五大核心能力解析与应用实践
AI测试工具正通过机器学习与计算机视觉技术重塑软件测试流程。其核心技术原理包括智能用例生成、UI自愈测试等五大能力矩阵,通过理解需求文档语义和视觉特征,实现从脚本维护到自主决策的范式转变。这类工具在电商、金融等敏捷开发场景中展现出显著价值,能减少40%测试时间,同时提升测试覆盖率至82%。以TestGPT和Diffblue Cover为代表的开源方案,结合LLM和强化学习算法,为单元测试生成和接口自动化提供了工程实践新思路。
PostgreSQL连接失败排查与解决方案
数据库连接是应用与PostgreSQL交互的基础,其核心原理涉及网络协议、认证机制和服务监听配置。在工程实践中,连接失败可能由服务状态、网络配置或认证问题导致,直接影响系统可用性。通过检查pg_hba.conf访问控制、postgresql.conf监听设置以及系统日志,可以快速定位5432端口连接问题。特别是在容器化部署和云环境中,还需关注网络隔离与资源限制。掌握连接字符串规范和服务监控技巧,能有效预防和解决常见的'connection failed'错误,保障数据库高可用性。
Java+SSM与Flask构建智能就业管理系统实践
企业级应用开发中,混合架构技术选型是解决复杂业务场景的关键策略。Java生态的SSM框架(Spring+SpringMVC+MyBatis)以其稳定的IoC容器管理和强大的ORM能力,成为传统业务系统开发的首选,特别适合需要处理复杂数据关系和严格事务控制的场景。而Python生态的Flask框架凭借其轻量级特性和丰富的机器学习库支持,在智能推荐、NLP处理等AI应用场景中展现独特优势。本文介绍的毕业生就业管理系统正是这两种技术栈的典型结合案例,通过Java处理核心业务逻辑,Python实现智能推荐算法,既保证了系统稳定性,又满足了就业场景下的个性化服务需求。这种架构模式对教育行业信息化建设、人才服务平台开发等场景具有重要参考价值。
Spring Boot在汽车维修管理系统中的架构设计与实践
微服务架构和领域驱动设计(DDD)是现代企业级应用开发的核心方法论。通过Spring Boot框架的自动配置和起步依赖特性,开发者可以快速构建高可用的分布式系统。结合MySQL的分区表与JSON类型支持,既能处理海量结构化数据,又能灵活存储非结构化维修记录。在汽车后市场领域,这种技术组合显著提升了工单处理效率和库存周转率,实现了从客户预约到维修完成的全流程数字化管理。本文以真实案例展示如何通过Spring Cloud Alibaba实现服务治理,并利用Redis多级缓存解决高并发场景下的性能瓶颈问题。