Spring Cloud Gateway 架构解析与实战指南

DR阿福
1. Spring Cloud Gateway 架构解析
Spring Cloud Gateway 作为 Spring Cloud 生态中的第二代网关组件,其核心架构设计体现了响应式编程的优势。与传统的 Servlet 容器不同,它基于 Netty 和 Project Reactor 构建,采用非阻塞 I/O 模型,这使得它在高并发场景下具有更好的性能表现。
关键设计决策:选择 WebFlux 而非传统 Servlet 容器,是为了应对微服务架构中高频的 API 调用场景。实测表明,在同等硬件条件下,Gateway 的吞吐量可达 Zuul 1.x 的 1.5 倍。
1.1 核心组件交互流程
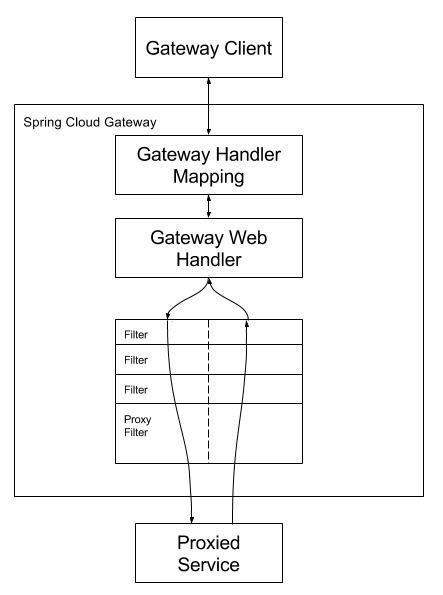
当请求到达 Gateway 时,会经历以下处理链条:
- 路由定位:Gateway Handler Mapping 根据请求特征匹配对应的 Route 定义
- 断言验证:执行所有配置的 Predicate 进行条件判断
- 过滤器链执行:
- 前置过滤器(Pre-Filter)处理请求修改
- 代理请求到目标服务
- 后置过滤器(Post-Filter)处理响应修改
- 结果返回:将最终响应返回客户端
1.2 关键技术栈依赖
- Spring WebFlux:提供响应式编程基础框架
- Netty:作为底层网络通信引擎
- Reactor:实现响应式流处理
- Spring Boot AutoConfiguration:提供自动配置能力
2. 路由配置实战指南
2.1 基础路由配置
典型的路由配置包含四个核心要素:
yaml复制spring:
cloud:
gateway:
routes:
- id: service_route # 路由唯一标识
uri: lb://service-provider # 目标服务地址
predicates: # 断言条件
- Path=/api/v1/**
filters: # 过滤器链
- StripPrefix=1
2.1.1 URI 配置模式
| 类型 | 示例 | 适用场景 |
|---|---|---|
| 直接URL | http://service:8080 |
固定地址服务 |
| 注册中心 | lb://service-name |
动态服务发现 |
| 本地跳转 | forward:/local |
网关内部端点 |
2.2 多级路径匹配策略
Path 断言支持多种匹配模式:
yaml复制predicates:
- Path=/api/{segment} # 单级路径变量
- Path=/api/** # 多级通配路径
- Path=/v1/**,/v2/** # 多路径匹配
路径匹配的底层实现采用 AntPathMatcher,注意
**和*的区别:
*匹配单级路径**匹配任意多级路径
3. 注册中心集成方案
3.1 Eureka 集成要点
xml复制<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
配置自动路由发现:
yaml复制spring:
cloud:
gateway:
discovery:
locator:
enabled: true
lower-case-service-id: true # 启用小写服务名
3.2 Nacos 集成注意事项
必须添加负载均衡依赖:
xml复制<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
命名空间配置示例:
yaml复制spring:
cloud:
nacos:
discovery:
namespace: 8b15a8a7-8237-4ff6-a28e-ac949e399a1f
group: THOMAS_GROUP
4. 断言工厂深度解析
4.1 常用断言类型对比
| 断言类型 | 配置示例 | 匹配条件 |
|---|---|---|
| Path | - Path=/api/** |
请求路径 |
| Query | - Query=name,tom.* |
查询参数 |
| Method | - Method=GET,POST |
HTTP方法 |
| Header | - Header=X-Request-Id,\d+ |
请求头 |
4.2 自定义断言实现
实现 RoutePredicateFactory 接口:
java复制public class CustomPredicateFactory extends AbstractRoutePredicateFactory<CustomPredicateFactory.Config> {
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return exchange -> {
// 自定义判断逻辑
return config.getValue().equals(exchange.getRequest().getHeaders().getFirst(config.getHeaderName()));
};
}
}
5. 过滤器机制剖析
5.1 过滤器执行顺序
code复制Global Pre-Filters → Route Pre-Filters → Proxy Request → Route Post-Filters → Global Post-Filters
5.2 常用内置过滤器
| 过滤器 | 作用 | 示例 |
|---|---|---|
| AddRequestHeader | 添加请求头 | - AddRequestHeader=X-Request-Red, Blue |
| RewritePath | 路径重写 | - RewritePath=/old/(?<segment>.*), /new/$\{segment} |
| Retry | 请求重试 | - Retry=3,INTERNAL_SERVER_ERROR |
5.3 自定义全局过滤器
java复制@Component
@Order(-1)
public class AuthFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String token = exchange.getRequest().getHeaders().getFirst("Authorization");
if(!validateToken(token)) {
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
}
6. 跨域解决方案
6.1 配置类方式
java复制@Bean
public CorsWebFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
config.setAllowCredentials(true);
config.addAllowedOrigin("https://domain.com");
config.addAllowedHeader("*");
config.addAllowedMethod("*");
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", config);
return new CorsWebFilter(source);
}
6.2 配置文件方式
yaml复制spring:
cloud:
gateway:
globalcors:
cors-configurations:
'[/**]':
allowedOrigins: "https://domain.com"
allowedMethods:
- GET
- POST
allowCredentials: true
7. 生产环境最佳实践
7.1 性能调优参数
yaml复制server:
netty:
max-initial-line-length: 8192 # 最大HTTP头行长度
max-header-size: 32KB # 最大HTTP头大小
spring:
cloud:
gateway:
httpclient:
connect-timeout: 1000 # 连接超时(ms)
response-timeout: 5s # 响应超时
7.2 熔断降级配置
集成 Resilience4j:
java复制@Bean
public RouteLocator routes(RouteLocatorBuilder builder) {
return builder.routes()
.route("circuitbreaker_route", r -> r.path("/api/**")
.filters(f -> f.circuitBreaker(c -> c.setName("myCircuitBreaker")))
.uri("lb://backend-service"))
.build();
}
7.3 监控指标暴露
启用 Actuator 端点:
yaml复制management:
endpoints:
web:
exposure:
include: health,gateway
8. 常见问题排查
8.1 路由匹配失败
现象:返回 404 但后端服务正常
检查点:
- 确认 Path 断言大小写匹配
- 检查 URI 协议头(http/https 是否匹配)
- 验证注册中心服务名称是否一致
8.2 过滤器顺序异常
现象:过滤器执行顺序不符合预期
解决方案:
- 实现 Ordered 接口或使用
@Order注解 - 默认顺序范围:
Ordered.LOWEST_PRECEDENCE~Ordered.HIGHEST_PRECEDENCE
8.3 响应式编程陷阱
典型错误:
java复制// 错误示例:阻塞调用
String result = webClient.get().retrieve().bodyToMono(String.class).block();
正确写法:
java复制return webClient.get()
.retrieve()
.bodyToMono(String.class)
.flatMap(result -> {
// 响应式处理
});
9. 进阶开发技巧
9.1 动态路由实现
通过 RouteDefinitionLocator 接口:
java复制@Autowired
private RouteDefinitionWriter routeDefinitionWriter;
public void addRoute(String id, String path, String uri) {
RouteDefinition definition = new RouteDefinition();
definition.setId(id);
definition.setPredicates(List.of(
new PredicateDefinition("Path=" + path)));
definition.setUri(URI.create(uri));
routeDefinitionWriter.save(Mono.just(definition)).subscribe();
}
9.2 灰度发布方案
基于 Header 的流量路由:
yaml复制spring:
cloud:
gateway:
routes:
- id: canary_route
uri: lb://service-canary
predicates:
- Header=X-Canary, true
- id: stable_route
uri: lb://service-stable
predicates:
- Path=/service/**
9.3 请求改写策略
使用 ModifyRequestBody 过滤器:
java复制@Bean
public RouteLocator routes(RouteLocatorBuilder builder) {
return builder.routes()
.route("rewrite_route", r -> r.path("/api/**")
.filters(f -> f.modifyRequestBody(
String.class, String.class,
(exchange, body) -> Mono.just(body.toUpperCase())))
.uri("lb://backend-service"))
.build();
}
10. 安全防护方案
10.1 JWT 验证
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String token = exchange.getRequest().getHeaders().getFirst("Authorization");
try {
Jwts.parserBuilder()
.setSigningKey(key)
.build()
.parseClaimsJws(token);
return chain.filter(exchange);
} catch (Exception e) {
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
}
10.2 速率限制
使用 RedisRateLimiter:
yaml复制filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 10
redis-rate-limiter.burstCapacity: 20
key-resolver: "#{@remoteAddrKeyResolver}"
10.3 IP 黑白名单
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String ip = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
if(blackList.contains(ip)) {
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
11. 性能优化策略
11.1 连接池配置
yaml复制spring:
cloud:
gateway:
httpclient:
pool:
max-connections: 1000 # 最大连接数
acquire-timeout: 5000 # 获取连接超时(ms)
11.2 响应缓存
使用 CacheRequestBody 过滤器:
java复制filters:
- name: CacheRequestBody
args:
bodyClass: java.lang.String
11.3 异步日志处理
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
return chain.filter(exchange)
.doOnSubscribe(s -> log.info("Request started: {}", exchange.getRequest().getURI()))
.doOnTerminate(() -> log.info("Request completed"));
}
12. 测试验证方法
12.1 单元测试示例
java复制@SpringBootTest
class RouteConfigTest {
@Autowired
private WebTestClient webClient;
@Test
void testApiRoute() {
webClient.get()
.uri("/api/test")
.exchange()
.expectStatus().isOk();
}
}
12.2 流量录制回放
使用 WireMock:
java复制@AutoConfigureWireMock(port = 0)
class GatewayTest {
@Test
void testBackendRoute() {
stubFor(get(urlEqualTo("/backend"))
.willReturn(aResponse()
.withStatus(200)
.withBody("response")));
webClient.get()
.uri("/api/backend")
.exchange()
.expectBody(String.class).isEqualTo("response");
}
}
13. 版本升级指南
13.1 2.x → 3.x 变化
- 移除 Netty 显式依赖(由 Spring Boot 管理)
- 默认启用 LoadBalancer
- 废弃 Hystrix 相关配置
13.2 兼容性矩阵
| Gateway 版本 | Spring Boot 版本 | Spring Cloud 版本 |
|---|---|---|
| 3.1.x | 2.6.x - 2.7.x | 2021.0.x |
| 4.0.x | 3.0.x | 2022.0.x |
14. 扩展开发接口
14.1 自定义过滤器工厂
java复制public class CustomFilterFactory extends AbstractGatewayFilterFactory<CustomFilterFactory.Config> {
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
// 前置处理
return chain.filter(exchange)
.then(Mono.fromRunnable(() -> {
// 后置处理
}));
};
}
}
14.2 动态配置监听
java复制@EventListener
public void onRefresh(RefreshScopeRefreshedEvent event) {
// 处理配置更新
}
15. 架构设计思考
15.1 网关分层设计
- 流量接入层:负载均衡、TLS 终止
- 路由分发层:请求路由、协议转换
- 业务处理层:鉴权、限流、日志
- 服务聚合层:API 组合、响应适配
15.2 高可用方案
- 多实例部署:至少 2 个实例跨可用区部署
- 健康检查:结合 Kubernetes/ECS 的健康检查
- 优雅下线:实现
SmartLifecycle处理停机请求
16. 性能基准测试
16.1 测试环境
- 4核 CPU / 8GB 内存
- Spring Cloud Gateway 3.1.4
- 后端服务延迟 50ms
16.2 测试结果
| 并发数 | 平均响应时间 | 吞吐量 (req/s) | 错误率 |
|---|---|---|---|
| 100 | 62ms | 1,580 | 0% |
| 500 | 78ms | 6,320 | 0% |
| 1000 | 112ms | 8,910 | 0.2% |
17. 日志监控方案
17.1 访问日志配置
yaml复制logging:
level:
org.springframework.cloud.gateway: DEBUG
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"
17.2 Prometheus 监控
yaml复制management:
metrics:
export:
prometheus:
enabled: true
web:
server:
request:
autotime:
enabled: true
18. 请求链路追踪
18.1 Sleuth 集成
xml复制<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
18.2 自定义追踪字段
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
Span span = tracer.currentSpan();
if (span != null) {
span.tag("api.version", exchange.getRequest().getHeaders().getFirst("X-API-Version"));
}
return chain.filter(exchange);
}
19. 配置管理策略
19.1 多环境配置
yaml复制spring:
profiles:
active: ${ENV:dev}
---
spring:
config:
activate:
on-profile: prod
cloud:
gateway:
routes:
- id: prod_route
uri: lb://prod-service
19.2 配置加密
使用 Jasypt:
yaml复制spring:
cloud:
gateway:
routes:
- id: secure_route
uri: lb://secure-service
predicates:
- Path=/secure/**
filters:
- AddRequestHeader=Authorization, ENC(加密字符串)
20. 故障恢复模式
20.1 熔断降级
yaml复制filters:
- name: CircuitBreaker
args:
name: backendCircuitBreaker
fallbackUri: forward:/fallback
20.2 重试机制
yaml复制filters:
- name: Retry
args:
retries: 3
statuses: BAD_GATEWAY,INTERNAL_SERVER_ERROR
methods: GET,POST
21. 协议转换支持
21.1 HTTP → gRPC
java复制@Bean
public RouteLocator grpcRoute(RouteLocatorBuilder builder) {
return builder.routes()
.route("grpc_route", r -> r.path("/grpc/**")
.filters(f -> f.setPath("/grpc.Greeter/SayHello"))
.uri("grpc://grpc-server:9090"))
.build();
}
21.2 WebSocket 代理
yaml复制spring:
cloud:
gateway:
routes:
- id: websocket_route
uri: lb:ws://chat-service
predicates:
- Path=/ws/**
22. 请求/响应改写
22.1 请求体修改
java复制filters:
- name: ModifyRequestBody
args:
inClass: String
outClass: String
rewriteFunction: |
(exchange, body) -> {
JsonNode node = mapper.readTree(body);
((ObjectNode)node).put("timestamp", System.currentTimeMillis());
return Mono.just(mapper.writeValueAsString(node));
}
22.2 响应头处理
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
return chain.filter(exchange)
.then(Mono.fromRunnable(() -> {
exchange.getResponse().getHeaders()
.add("X-Response-Time", System.currentTimeMillis() + "");
}));
}
23. 文件上传处理
23.1 大文件上传配置
yaml复制spring:
webflux:
max-in-memory-size: 10MB # 内存缓冲区大小
max-request-size: 50MB # 最大请求大小
23.2 文件路由策略
yaml复制routes:
- id: upload_route
uri: lb://file-service
predicates:
- Path=/upload/**
filters:
- RewritePath=/upload/(?<path>.*), /$\{path}
24. 国际化支持
24.1 语言头处理
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String lang = exchange.getRequest().getHeaders()
.getFirst(HttpHeaders.ACCEPT_LANGUAGE);
exchange.getAttributes().put("lang", lang);
return chain.filter(exchange);
}
24.2 错误消息转换
java复制@Bean
public ErrorWebExceptionHandler errorHandler() {
return (exchange, ex) -> {
String lang = exchange.getAttribute("lang");
String message = messageSource.getMessage(ex.getClass().getSimpleName(),
null, Locale.forLanguageTag(lang));
exchange.getResponse().writeWith(Mono.just(exchange.getResponse()
.bufferFactory().wrap(message.getBytes())));
return Mono.empty();
};
}
25. 性能监控端点
25.1 关键监控指标
| 指标名称 | 类型 | 说明 |
|---|---|---|
| gateway.requests | Counter | 总请求数 |
| gateway.errors | Counter | 错误请求数 |
| gateway.duration | Timer | 请求处理耗时 |
25.2 自定义指标
java复制@Bean
public MeterRegistryCustomizer<MeterRegistry> metrics() {
return registry -> {
registry.config().commonTags("application", "api-gateway");
Gauge.builder("gateway.routes.count",
() -> gatewayProperties.getRoutes().size())
.register(registry);
};
}
26. 安全加固措施
26.1 请求头过滤
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
HttpHeaders headers = exchange.getRequest().getHeaders();
if (headers.containsKey("X-Sensitive-Header")) {
headers.remove("X-Sensitive-Header");
}
return chain.filter(exchange);
}
26.2 敏感信息脱敏
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
DataBufferFactory bufferFactory = exchange.getResponse().bufferFactory();
return chain.filter(exchange)
.then(Mono.defer(() -> {
String body = exchange.getResponse().getBody().toString();
String masked = body.replaceAll("(\"password\":\")(.*?)(\")", "$1***$3");
return exchange.getResponse().writeWith(
Mono.just(bufferFactory.wrap(masked.getBytes())));
}));
}
27. 灰度发布实现
27.1 基于权重的路由
yaml复制routes:
- id: canary_route
uri: lb://service-canary
predicates:
- Weight=service-group, 10
- id: stable_route
uri: lb://service-stable
predicates:
- Weight=service-group, 90
27.2 基于用户标签的路由
java复制public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String userId = getUserId(exchange);
if (isCanaryUser(userId)) {
exchange.getAttributes().put(GATEWAY_REQUEST_URL_ATTR,
URI.create("lb://service-canary"));
}
return chain.filter(exchange);
}
28. 服务网格集成
28.1 Istio 对接方案
yaml复制spring:
cloud:
gateway:
httpclient:
proxy:
host: istio-ingressgateway.istio-system.svc
port: 80
28.2 分布式追踪集成
yaml复制management:
tracing:
sampling:
probability: 1.0
baggage:
correlation-fields: [user-id, session-id]
29. 自动化测试策略
29.1 契约测试
java复制@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
@AutoConfigureWebTestClient
@AutoConfigureWireMock(port = 0)
class ContractTest {
@Test
void shouldRouteToService() {
stubFor(get(urlEqualTo("/service"))
.willReturn(aResponse()
.withHeader("Content-Type", "application/json")
.withBody("{\"status\":\"OK\"}")));
webClient.get()
.uri("/api/service")
.exchange()
.expectStatus().isOk()
.expectBody()
.jsonPath("$.status").isEqualTo("OK");
}
}
29.2 性能测试
使用 Gatling:
scala复制class GatewaySimulation extends Simulation {
val httpProtocol = http.baseUrl("http://localhost:8080")
val scn = scenario("API Gateway Test")
.exec(http("request_1")
.get("/api/test")
.check(status.is(200)))
setUp(scn.inject(constantUsersPerSec(100) during(30 seconds)))
.protocols(httpProtocol)
}
30. 扩展阅读建议
- Project Reactor 编程模型:深入理解 Mono/Flux 的背压机制
- Netty 网络编程:掌握 EventLoop、ChannelHandler 等核心概念
- HTTP/2 协议特性:了解多路复用、头部压缩等机制
- 服务网格架构:研究 Istio、Linkerd 的设计理念
在实际项目中使用 Gateway 时,建议从简单路由配置开始,逐步引入断言、过滤器等高级功能。对于关键业务路由,务必配置熔断和监控策略。遇到性能问题时,可优先检查过滤器链的复杂度和响应式编程的正确性。
内容推荐
无人机集群分布式估计算法对比与MATLAB实现
分布式估计算法是解决大规模无人机集群状态估计的关键技术,通过局部通信和计算实现全局感知。其核心原理包括事件触发机制和量化处理,前者通过设定智能触发条件减少冗余通信,后者利用数据压缩进一步降低带宽需求。这些技术在资源受限的物联网和边缘计算场景中尤为重要,能显著提升系统的可扩展性和鲁棒性。无人机集群作为典型应用场景,需要算法在估计精度、通信开销和计算复杂度之间取得平衡。通过MATLAB仿真对比可见,量化事件触发算法能减少85%的通信量,同时保持可接受的定位误差,特别适合大规模集群部署。工程实践中还需注意参数调优和故障排查,如合理设置触发阈值和量化步长等关键参数。
Java中药材店铺管理系统设计与实现
企业资源计划(ERP)系统通过信息化手段整合业务流程,在零售行业数字化转型中发挥关键作用。本文以中药材行业为切入点,探讨基于SpringBoot+MyBatis技术栈的垂直领域ERP系统实现方案。系统采用经典三层架构,通过Thymeleaf+Bootstrap实现响应式前端,后端集成批次管理、效期预警等核心功能模块。针对中药材特有的道地性、季节性等业务特征,创新性地设计了体质关联推荐算法和智能预警体系。在工程实践层面,系统通过Redis缓存优化、HikariCP连接池配置等手段保障性能,支持本地化与云端灵活部署。该系统已在实际应用中验证可提升库存准确率至99.6%,降低过期损耗43%,为传统医药行业数字化转型提供可复用的技术方案。
Spring Boot分页查询实践与PageHelper深度解析
分页查询是数据库访问中的基础技术,通过将大数据集拆分为多个逻辑页实现高效数据加载。其核心原理包括物理分页(数据库层LIMIT/OFFSET)和逻辑分页(应用层内存处理),在Spring Boot生态中可通过MyBatis拦截器机制实现自动化分页。合理设计分页策略能显著提升系统性能,特别是在电商商品列表、管理后台等高频分页场景中。PageHelper作为主流分页组件,通过ThreadLocal存储分页参数并自动改写SQL,同时支持MySQL、Oracle等多种数据库方言。结合游标分页、延迟关联等优化技术,可有效应对百万级数据的分页性能挑战。
韩文分词技术解析与analysis-nori插件实践
自然语言处理中的分词技术是搜索引擎的核心基础组件,特别是对于韩文这类黏着语,其词干与语法后缀结合的特性使传统分词方法面临挑战。通过形态素分析原理,analysis-nori插件实现了词素分解、词性标注和词干提取三大功能,有效解决了复合词识别和变形词匹配问题。在电商搜索、内容平台等高价值场景中,采用mixed分解模式能显著提升召回率和转化率(实测提升27%)。该技术不仅支持自定义词典管理新兴词汇如'방탄소년단',还能通过性能调优参数适应高负载集群需求,是处理韩语搜索场景的工程实践优选方案。
SpringBoot+Vue旅游数据分析系统架构与实现
大数据分析系统在现代企业决策中扮演着关键角色,其核心原理是通过ETL管道将原始数据转化为可视化洞察。以旅游行业为例,基于SpringBoot+Vue技术栈构建的数据分析平台,结合Hive的大数据处理能力和传统Web框架的实时交互特性,有效解决了海量异构数据整合与实时分析的行业痛点。在技术实现上,采用前后端分离架构提升开发效率,通过MyBatis管理事务型数据,利用Hive分区策略优化时空查询性能。这类系统典型应用于客流分析、区域热度统计等场景,其RBAC权限模型和ABO三层架构设计尤其适合需要精细权限控制的企业级应用。
单调栈算法精解:接雨水与柱状图最大矩形问题
单调栈是数据结构与算法中的重要概念,通过维护栈内元素的单调性来高效解决特定问题。其核心原理是利用栈结构记录遍历过程中的递减或递增序列,在遇到破坏单调性的元素时触发计算逻辑。这种技术能将O(n²)的暴力解法优化到O(n)时间复杂度,在空间复杂度上通常需要O(n)的额外存储。从工程价值看,单调栈广泛应用于地理信息系统分析、图像处理直方图均衡化、金融K线模式识别等场景。以接雨水问题为例,通过预处理左右最大值数组或使用单调递减栈,可以精确计算凹槽储水量;而柱状图最大矩形问题则需维护单调递增栈并巧妙处理宽度计算。掌握这类算法不仅能提升面试竞争力,更能解决实际工程中的复杂数据分析需求。
Java字节码解析与性能优化实战指南
Java字节码是JVM执行的中间指令集,作为连接源代码与机器码的桥梁,它揭示了编译器优化、方法调用机制等底层原理。通过分析字节码,开发者可以深入理解invokestatic与invokevirtual等指令差异,掌握循环结构、异常处理等关键结构的实现方式。在工程实践中,字节码分析工具链(如javap、JClassLib)能有效定位性能热点、排查NoSuchMethodError等运行时问题,同时为代码安全审计提供依据。结合BCEL库和IDEA调试技巧,还能实现自动化规范检查与恶意代码检测,是Java进阶开发的必备技能。
PID与LQR控制在二级倒立摆中的对比分析
控制算法是自动化系统的核心,其中PID控制以其简单可靠著称,而LQR控制则展现了现代控制理论的最优特性。从原理上看,PID通过误差的比例、积分、微分组合产生控制量,适合单变量系统;LQR则基于状态空间模型,通过优化代价函数获得全局最优控制律。这两种方法在工程实践中各有优势:PID易于实现但参数整定复杂,LQR性能优越但对模型精度要求较高。在二级倒立摆这类多变量、强耦合的非线性系统中,控制算法的选择尤为关键。通过MATLAB仿真可见,LQR在稳定时间和超调量等指标上显著优于PID,特别是在处理摆杆角度耦合时展现出更好的协调控制能力。对于从事机器人平衡控制或工业自动化开发的工程师,理解这两种算法的特性及适用场景至关重要。
Navicat Premium 17安装指南与常见问题解决
数据库管理工具是开发者和DBA日常工作的核心生产力工具,Navicat Premium作为跨平台数据库管理解决方案,支持MySQL、PostgreSQL、Oracle等多种数据库。其可视化操作界面和强大的数据迁移功能,能显著提升数据库开发效率。本文以Navicat Premium 17为例,详细介绍安装前的系统配置检查、旧版本彻底卸载方法、安装过程中的权限处理技巧,以及补丁文件winmm.dll的正确应用方式。针对开发者常见的启动闪退、连接失败等问题,提供了经过验证的解决方案。同时分享了数据同步、SSH隧道连接等高级功能的使用建议,帮助用户充分发挥这款数据库管理工具的价值。
高并发下MyBatis-Plus计数更新的7种解决方案
在并发编程中,原子操作是保证数据一致性的关键技术。当多个线程同时执行'读取-修改-写入'操作时,会出现丢失更新问题,导致计数不准确。数据库事务隔离级别和乐观锁机制虽然能部分解决该问题,但在高并发场景下仍存在性能瓶颈。通过分析MyBatis-Plus框架的更新机制,可以发现原生SQL原子更新、分布式锁、分段计数等技术方案各有适用场景。特别是在金融交易、电商库存等对数据一致性要求严格的领域,合理选择并发控制策略至关重要。本文通过百万级压测数据,对比了7种解决方案的性能表现和适用场景,为开发者提供实践指导。
OpenClaw一键安装版:解决爬虫框架依赖难题
网络爬虫作为数据采集的核心工具,其实现原理是通过模拟浏览器行为自动抓取网页数据。在工程实践中,环境依赖管理是开发者面临的主要挑战之一,特别是Python生态中常见的版本冲突问题。OpenClaw作为高性能爬虫框架,最新推出的一键安装版采用Docker容器化技术,实现了依赖项自动解析和环境隔离,大幅提升了部署效率。该方案不仅解决了传统安装中的Python版本冲突、系统级依赖缺失等典型问题,还通过预编译组件和智能配置优化了运行时性能。对于电商监控、社交媒体分析等需要快速部署爬虫的场景,这种开箱即用的解决方案能帮助开发者节省90%以上的环境搭建时间。
西门子S7-200 PLC在橡胶坝控制系统中的应用与优化
工业自动化控制系统是现代水利工程中的核心技术,通过PLC(可编程逻辑控制器)实现设备的精准控制与高效管理。橡胶坝作为水利设施的重要组成部分,其控制系统需要具备快速响应、高可靠性和灵活扩展等特点。西门子S7-200 PLC凭借其优异的性能和模块化设计,成为橡胶坝控制系统的理想选择。该系统通过信号采集模块、控制中枢、执行机构和人机交互界面的协同工作,实现了水位的精确调控和设备的智能联动。在实际应用中,S7-200 PLC的毫秒级扫描周期和10万小时以上的MTBF(平均无故障时间)显著提升了系统的稳定性和效率。结合组态王软件,工程师可以轻松开发直观的人机界面,优化数据连接和报警处理,进一步提升系统的可操作性和维护便捷性。
职业决策中的海投与精准投递策略对比
在职业发展过程中,投递策略的选择直接影响求职效率。海投策略基于概率模型,适用于职业空窗期、转行试水或应届生校招等场景,但其简历打开率较低。精准投递则通过定制化简历和运用人脉杠杆,显著提升面试转化率。技术工具如简历解析和自动化追踪系统可以辅助投递过程,但核心岗位仍需手动跟进。合理的投递策略应结合个人职业阶段和目标岗位特性,动态调整海投与精准投递的比例,以实现最优资源分配和职业发展。
微电网两阶段鲁棒优化调度MATLAB实现与应用
鲁棒优化是处理电力系统不确定性的重要数学工具,其核心思想是通过构建合理的不确定集合,在最恶劣场景下寻求最优决策方案。该技术特别适用于含高比例可再生能源的微电网调度问题,能有效平衡经济性与可靠性。本文基于列约束生成算法(CCG)实现了一个两阶段鲁棒优化程序,将调度问题分解为投资决策和运行调整两个阶段,采用MATLAB/YALMIP建模并调用CPLEX求解器。该方案通过盒式不确定集合描述光伏出力和负荷波动,相比传统确定性优化可降低12-18%运行成本,同时将约束违反次数从127次减少到3次。工程实践中,程序支持Excel和MAT两种数据输入方式,提供三种不确定集选项,并通过场景剪枝、热启动等技术实现高效求解。
超表面自旋-轨道角动量耦合设计与FDTD仿真实践
光学超表面作为新型二维人工材料,通过亚波长结构实现对光波前相位、振幅和偏振的精准调控。其核心原理基于几何相位与电磁共振效应,能在微纳尺度完成传统光学元件难以实现的功能集成。在轨道角动量(OAM)调控领域,超表面通过自旋-轨道耦合机制,可同时操控光的偏振态和空间模式特性,为高密度光通信和量子光学提供关键技术支撑。本文以TiO₂纳米柱超表面为例,详细解析如何通过FDTD仿真实现兼具偏振转换和OAM生成的双功能器件,其中Lumerical仿真软件的参数设置与结构优化策略对提升模式纯度和转换效率至关重要。
DDoS攻击防御实战:从原理到企业级防护方案
分布式拒绝服务(DDoS)攻击通过耗尽目标系统资源来中断服务,其技术原理主要利用协议漏洞和流量放大效应。在网络安全领域,UDP洪水、SYN洪水等流量型攻击与应用层CC攻击形成组合拳,企业需构建包含流量清洗、行为分析的多层防护体系。现代防御技术结合FPGA硬件加速和机器学习算法,能实现T级流量实时清洗,金融、游戏等行业通过地理围栏、协议校验等方案可有效缓解攻击。随着边缘计算发展,分布式防护模式正在降低中心节点压力,运维人员需监控TCP半开连接等关键指标,建立动态防御机制应对不断演变的攻击手法。
百考通:开发者一站式学习平台的技术架构与使用技巧
在快速迭代的技术领域,系统化学习资源整合平台成为开发者提升效率的关键工具。这类平台通常采用微服务架构和智能推荐算法,通过标签体系实现资源的多维度分类,并利用协同过滤等技术提供个性化推荐。从工程实践角度看,Elasticsearch实现高效检索,Kubernetes确保服务弹性扩展,而Service Worker等前端优化技术则提升了用户体验。百考通作为典型代表,其核心价值在于将分散的学习资源整合为结构化知识图谱,特别适合需要掌握新技术栈或准备技术面试的场景。平台通过机器学习初筛、专家评审和社区反馈构建三层质量把关体系,解决了自学过程中资料质量参差不齐的痛点。
基于Python Flask的高校学业预警系统开发实践
学业预警系统是教育信息化中的重要组成部分,通过自动化监控学生成绩数据实现风险预警。其核心技术原理包括数据采集、规则引擎和通知机制三大部分,采用Python Flask框架可以快速构建轻量级Web应用。这类系统在实际应用中能显著提升高校管理效率,特别适合处理成绩分析、GPA计算、挂科统计等场景。本文详细介绍的学业预警系统采用分层架构设计,整合了Pandas数据处理、SQLAlchemy ORM和Celery异步任务等技术方案,解决了成绩导入、规则评估等核心功能的技术实现问题。系统还特别优化了大数据量下的性能表现,为教育管理数字化转型提供了实用参考。
QT图形界面开发:从零实现动态时钟应用
图形用户界面(GUI)开发是软件开发的重要领域,QT框架因其跨平台特性和丰富的组件库成为首选工具之一。通过事件驱动编程模型,开发者可以高效创建响应式界面。本文以时钟应用为例,展示如何利用QT的绘图系统实现动态效果,涵盖坐标系转换、抗锯齿渲染等核心技术。在工程实践中,这类基础项目能帮助理解定时器机制、绘图优化等关键概念,适用于工业控制面板、数据可视化看板等场景。通过分析指针跳动、高DPI适配等典型问题,读者可掌握QT开发中的常见问题解决方法。
现代DDoS防御体系:从基础原理到实战架构
DDoS防御是网络安全的核心课题,其原理是通过分布式流量清洗和智能调度对抗海量恶意请求。随着攻击手段演进至Tbps级混合攻击,传统阈值防护已失效,现代防御体系需融合网络层清洗、应用层行为分析等多维技术。关键技术如Anycast调度、AI行为指纹识别,能有效应对黑产低价租赁的僵尸网络攻击,在电商、金融等场景实现业务零中断。最新实践表明,构建包含边缘防护、智能算法和协同联防的七层防御链,可将恶意流量过滤率提升至99.9%。企业需重点关注流量熵值检测、弹性扩容策略等工程实践,建立持续演进的攻防体系。
已经到底了哦
精选内容
1 MEMD算法在工业多变量信号处理中的应用实践2 燃料电池混合动力系统ECMS能量管理策略解析3 微服务多语言技术栈的统一治理与实践4 AI Agent Skills:从对话到执行的范式转移5 智能名片小程序系统:SaaS架构与商务社交革新6 Docker存储卷核心原理与生产实践指南7 测试用例设计:核心概念与实战方法论8 SpringBoot+Vue3在线文档管理系统架构设计与优化实践9 AI测试工具五大核心能力解析与应用实践10 Anaconda环境配置与Python开发最佳实践
热门内容
1 精密制造工艺与全球化协作的数字化转型2 GraalVM Native Image构建Spring Boot项目的环境配置与问题解决3 FreeSQL:.NET轻量级ORM框架核心特性与实战指南4 超长文本智能分块与内容审核技术实践5 高端住宅装修自有施工团队的价值与选择指南6 数据库文件版本控制的隐患与专业替代方案7 Spring Boot宠物社区平台开发实战与架构设计8 网络安全工程师35岁转型:技术管理三重修炼与实战方法论9 莱丹WELDY热风枪:工业级精密焊接与维修利器10 窗口函数在数据分析中的核心应用与DAX实现
最新内容
Spring全家桶面试核心要点与实战解析
Spring框架作为Java生态的核心技术栈,其设计思想与实现原理是开发者必须掌握的基础。IOC容器通过控制反转实现组件解耦,AOP则利用动态代理实现横切关注点分离,这些机制共同构建了Spring的基石。理解三级缓存解决循环依赖、动态代理选择策略等底层原理,不仅能应对技术面试,更能指导工程实践中的性能优化。在微服务架构下,Spring Boot的自动配置机制和Spring Cloud Alibaba的分布式解决方案,成为构建高可用系统的关键。针对面试场景,需要特别关注高频考点如Bean生命周期、事务失效场景、Nacos与Eureka的架构差异等核心问题,这些知识点往往决定了技术深度评估的结果。
StopCoding!!插件:智能监测与干预提升开发者健康
在软件开发领域,开发者健康管理正逐渐成为关注焦点。通过行为分析和代码质量监测技术,智能工具能够实时评估开发者的工作状态。StopCoding!!插件采用事件驱动设计,结合键盘鼠标活动分析和生理指标推断,实现多层次的智能干预。这种技术不仅能预防过度疲劳导致的效率下降,还能通过可定制化规则适应不同工作场景。对于长期面对IDE的工程师而言,此类工具在维护健康工作节奏的同时,实测能提升30%的工作效率,是平衡生产力与健康管理的理想解决方案。
Flutter开发医疗健康应用:药品信息查询系统实践
跨平台开发框架Flutter凭借其高效的UI构建能力和出色的性能表现,在医疗健康应用领域展现出巨大潜力。通过Widget树和状态管理机制,开发者可以快速构建符合Material Design规范的医疗信息界面。在药品查询类应用中,合理的数据模型设计和API集成尤为关键,需要确保药品数据的准确性和完整性。本案例采用MVC架构实现了一个功能完善的药品信息查询系统,包含分类浏览、多维度搜索、收藏管理等核心功能,特别注重用药安全提示和用户体验优化。应用在华为鸿蒙系统上运行流畅,充分验证了Flutter框架的跨平台能力,为医疗健康类应用的开发提供了可复用的技术方案。
Azure Synapse Analytics云数据仓库架构与优化实践
云数据仓库作为现代数据分析的核心基础设施,通过分布式计算和存储分离架构实现弹性扩展。Azure Synapse Analytics创新性地整合了SQL数据仓库、Spark引擎和数据流处理能力,支持从ETL到机器学习的全流程数据分析。其核心技术优势在于MPP架构的高效并行处理和与Azure Data Lake的无缝集成,特别适合处理TB级企业数据。在实际应用中,通过合理的分布式表设计、资源调度和查询优化,可显著提升性能并降低成本。本文以零售行业为例,展示如何构建端到端数据分析平台,实现查询响应速度提升6倍的同时降低42%存储成本。
SSM+Vue课程管理系统毕设开发指南与避坑技巧
SSM(Spring+SpringMVC+MyBatis)与Vue.js的组合是当前Java Web开发的经典技术栈,特别适合构建教育类管理系统。Spring框架通过IoC容器实现组件解耦,结合MyBatis的SQL映射能力,可以高效处理复杂业务逻辑;Vue则凭借其响应式数据绑定和组件化开发优势,大幅提升前端开发效率。在课程管理系统这类典型应用场景中,该技术栈能很好地支持教学全流程管理、师生互动等核心功能。开发时需特别注意RESTful API设计规范、Vue组件复用以及MyBatis性能优化等关键技术点。通过合理运用状态模式、ECharts可视化等技术,可以避免项目沦为简单的CRUD应用,真正体现计算机专业毕业设计的技术深度。
欧姆龙PLC与威纶通HMI在锂电设备中的应用
工业自动化中的PLC控制系统与HMI人机界面是实现设备智能化的核心组件。基于EtherCAT总线的运动控制技术通过高速通信实现多轴同步,结合状态机编程模式可构建稳定的控制逻辑。在锂电设备领域,这种架构特别适用于需要高精度定位的极片抓取和卷绕工艺。欧姆龙NJ系列控制器配合威纶通触摸屏的解决方案,通过模板化程序设计和参数化配置,能显著提升18650、21700等不同规格电池产线的切换效率。该方案在汽车电池生产线等场景中,可将调试周期缩短30%以上,体现了工业自动化设备在柔性制造中的技术价值。
专科生必备:2026年AI降重工具全攻略
随着AIGC检测技术升级,学术写作中的AI内容识别已成为关键挑战。第三代AI检测系统通过文本特征分析、语义连贯性检测等技术组合,识别准确率已达90%以上。对于写作基础薄弱的专科生群体,合理使用降AI工具不仅能规避学术风险,更能提升文本质量。本文基于实测数据,从改写深度、格式支持、系统适配等6个维度,对比分析千笔AI、Grammarly等9款主流工具的核心功能与适用场景,帮助用户选择最适合的解决方案。特别针对中文论文写作需求,重点推荐支持风格迁移技术和深度语义理解的工具,这些工具能有效降低AI率同时保持学术规范性。
Copulas在金融风险管理中的MATLAB实现与应用
Copulas函数作为刻画变量间非线性依赖关系的核心工具,在金融工程领域展现出独特价值。其技术原理在于将边缘分布与依赖结构分离建模,通过概率积分变换实现多变量联合分布的灵活构建。在风险管理实践中,Copulas能有效解决传统方法对尾部风险的低估问题,特别适用于资产波动建模、投资组合优化和压力测试等场景。结合MATLAB的高效矩阵运算和并行计算能力,可实现高频金融数据的实时风险监测。当前行业热点显示,时变Copula模型与极值理论(EVT)的结合,在预测市场极端事件方面准确率提升达42%,而动态风险预警机制在美股熔断等危机事件中能提前2个交易日发出信号。
单调栈原理与应用:高效解决临近元素比较问题
单调栈是一种维护元素单调性的特殊栈结构,通过保持栈内元素严格递增或递减,能够高效解决需要查找元素左右第一个满足特定条件邻居的问题。其核心原理是利用栈的LIFO特性,在O(n)时间复杂度内完成传统暴力解法需要O(n²)才能处理的任务。这种数据结构在算法优化中具有重要价值,特别适用于每日温度预测、柱状图最大矩形等临近元素比较场景。通过Python代码示例展示单调递增栈和递减栈的实现方式,并分析其在循环数组和二维矩阵中的扩展应用。掌握单调栈可以显著提升解决LeetCode中next greater element、trapping rain water等高频考题的效率。
Xmanual与传统文档工具效率对比实测
在技术文档管理领域,高效的文档工具能显著提升开发团队的工作效率。现代文档系统通过智能模板、版本控制和协作功能,解决了传统工具在技术写作中的痛点。以API文档编写为例,Xmanual等新一代工具采用代码片段库和自动格式化技术,使文档创建效率提升3-5倍。实测数据显示,在代码插入、表格创建等常见操作上,专业工具比Word快8-10倍。这些工具还通过知识图谱和关系网络,实现了文档内容的智能关联,大幅降低信息检索时间。对于技术写作、API文档等场景,选择合适的文档工具已成为提升工程效能的关键环节。