水光互补系统优化调度:粒子群算法与Python实现

1. 项目概述
在可再生能源领域,水光互补系统正成为解决光伏发电间歇性和波动性问题的有效方案。作为一名长期从事能源系统优化的工程师,我最近复现了一篇关于梯级水光互补系统优化调度的EI论文,采用Python实现了基于粒子群算法的求解方案。这个项目让我深刻体会到水电调节能力对光伏消纳的关键作用,也验证了智能算法在复杂能源系统优化中的实用价值。
传统水光互补研究多以电站为调度单元,而本次复现的模型创新性地以机组为最小调度单位,精细考虑了电站、机组和电网的多重约束。通过西南地区某流域梯级水电站与光伏电站的实际数据测试,模型成功将光伏消纳量提升了10%以上,同时将出力波动控制在3%以内,达到了工程实用水平。
2. 核心问题与解决思路
2.1 光伏出力的不确定性处理
光伏发电受天气影响显著,直接采用预测值进行调度会导致实际运行时出现偏差。在本次复现中,我采用了模糊C均值聚类方法构建典型出力场景:
python复制from sklearn.cluster import KMeans
# 历史光伏出力数据预处理
historical_data = np.loadtxt('pv_history.csv')
scaler = StandardScaler()
scaled_data = scaler.fit_transform(historical_data)
# 使用肘部法则确定最佳聚类数
distortions = []
K_range = range(1,10)
for k in K_range:
kmeans = KMeans(n_clusters=k)
kmeans.fit(scaled_data)
distortions.append(kmeans.inertia_)
# 确定3个典型场景(晴/阴/雨)
optimal_k = 3
scenarios = KMeans(n_clusters=optimal_k).fit_predict(scaled_data)
每个场景赋予不同的发生概率,在优化时以期望值最大化为目标,既考虑了不确定性,又避免了过于保守的调度方案。
2.2 水电精细化建模挑战
梯级水电站包含不同类型机组,各具独特的运行特性:
- 振动区约束:机组在某些出力区间运行会产生有害振动
- 爬坡速率限制:机组出力不能突变,需满足最大变化率要求
- 启停次数限制:频繁启停会加速设备老化
在Python实现中,我采用二进制变量表示机组状态(0停机,1运行),通过惩罚函数处理约束:
python复制def penalty_function(solution):
total_penalty = 0
# 检查振动区约束
for unit in range(N_units):
if P_min_vib[unit] < solution[unit] < P_max_vib[unit]:
total_penalty += 1e6 # 大惩罚系数
# 检查爬坡速率
for t in range(1, T):
delta = abs(solution[t] - solution[t-1])
if delta > max_ramp_rate:
total_penalty += 1e5 * (delta - max_ramp_rate)
return total_penalty
3. 优化模型构建
3.1 目标函数设计
最大化系统可消纳电量期望值:
$$
\max \sum_{s=1}^{S} \pi_s \left[ \sum_{t=1}^{T} \left( \sum_{i=1}^{I} P_{i,t}^{hydro} + \sum_{j=1}^{J} P_{j,t,s}^{pv} \right) \Delta t \right]
$$
其中$\pi_s$为场景s的概率,$P^{hydro}$和$P^{pv}$分别为水电和光伏出力。
3.2 主要约束条件
-
水量平衡约束:
$$ V_{i,t} = V_{i,t-1} + (I_{i,t} - Q_{i,t} - S_{i,t}) \Delta t $$ -
电站出力约束:
$$ P_{i,t}^{min} \leq P_{i,t}^{hydro} \leq P_{i,t}^{max} $$ -
电网断面约束:
$$ \left| \sum_{i \in G_g} P_{i,t}^{hydro} + \sum_{j \in G_g} P_{j,t}^{pv} \right| \leq P_{g,t}^{max} $$
4. 粒子群算法实现
4.1 算法参数设置
python复制class PSO:
def __init__(self, n_particles, dimensions, bounds):
self.n_particles = n_particles
self.dimensions = dimensions # 决策变量维度
self.bounds = bounds # 变量上下界
# 算法参数
self.w = 0.729 # 惯性权重
self.c1 = 1.49445 # 认知系数
self.c2 = 1.49445 # 社会系数
# 初始化粒子群
self.position = np.random.uniform(
low=bounds[0], high=bounds[1],
size=(n_particles, dimensions))
self.velocity = np.zeros((n_particles, dimensions))
self.pbest_pos = self.position.copy()
self.pbest_val = np.full(n_particles, np.inf)
self.gbest_pos = None
self.gbest_val = np.inf
4.2 适应度函数设计
适应度函数需考虑目标函数值和约束违反程度:
python复制def fitness_function(position, scenarios):
total_fitness = 0
# 计算各场景下的期望发电量
for s, prob in enumerate(scenarios['probability']):
scenario_fitness = 0
for t in range(T):
# 计算水电出力
hydro_power = calculate_hydro_power(position, t)
# 获取当前场景下光伏出力
pv_power = scenarios['power'][s][t]
# 累计时段发电量
scenario_fitness += (hydro_power + pv_power) * dt
# 加权求和
total_fitness += prob * scenario_fitness
# 减去约束惩罚项
penalty = penalty_function(position)
return total_fitness - penalty
4.3 算法优化技巧
-
自适应惯性权重:随迭代次数线性递减,平衡探索与开发
python复制self.w = w_max - (w_max - w_min) * (iter/iter_max) -
变异操作:避免早熟收敛
python复制if np.random.rand() < mutation_rate: particle_pos += np.random.normal(0, 0.1*range) -
约束处理:采用修复策略保证解可行性
python复制def repair_solution(solution): # 处理振动区约束 for i in range(N_units): if P_min_vib[i] < solution[i] < P_max_vib[i]: # 调整到最近的安全区间 if abs(solution[i] - P_min_vib[i]) < abs(solution[i] - P_max_vib[i]): solution[i] = P_min_vib[i] else: solution[i] = P_max_vib[i] return solution
5. 工程实践与结果分析
5.1 案例系统参数
基于西南某流域4个梯级水电站(共15台机组)和2个光伏电站的实际数据:
| 电站 | 机组数 | 装机容量(MW) | 调节库容(万m³) |
|---|---|---|---|
| 1 | 3 | 600 | 12,000 |
| 2 | 4 | 695 | 8,500 |
| 3 | 3 | 600 | 6,200 |
| 4 | 5 | 1250 | 15,800 |
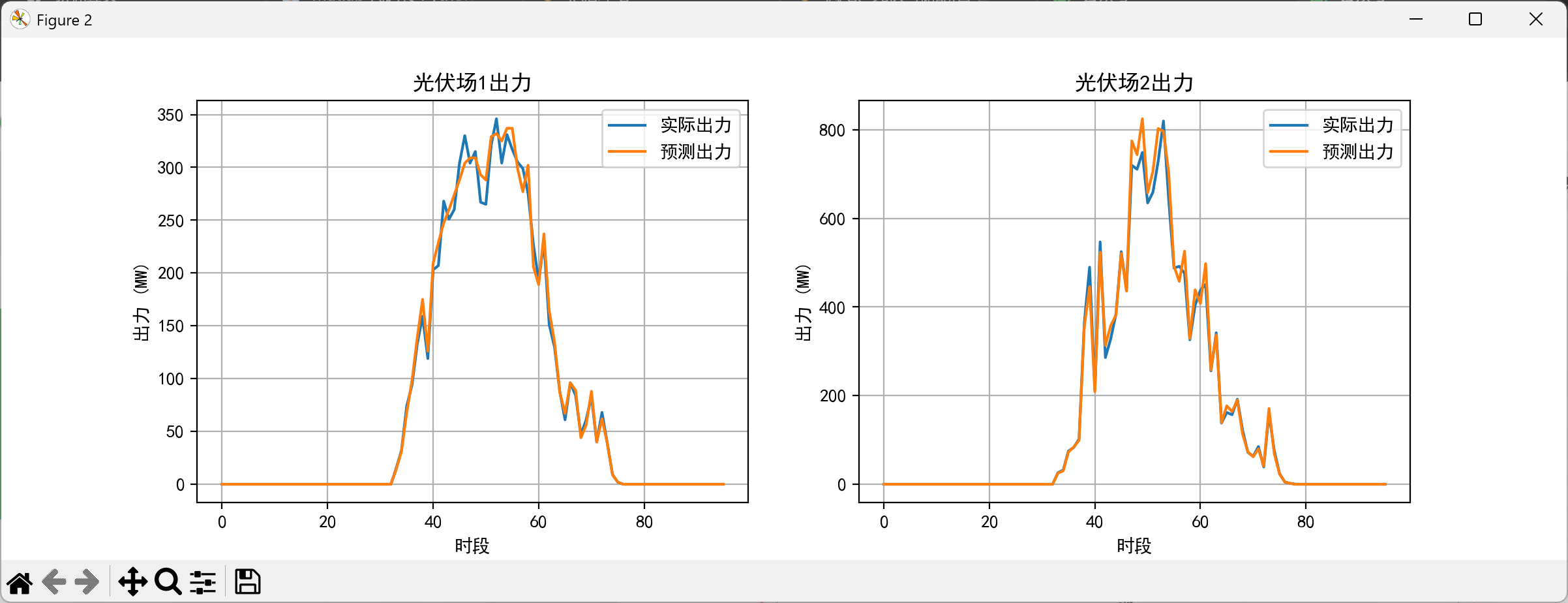
光伏电站总装机容量为580MW,典型日预测出力曲线如图:
5.2 优化结果对比
| 指标 | 单独运行 | 互补调度 | 提升幅度 |
|---|---|---|---|
| 光伏消纳量(MWh) | 5,820 | 6,453 | +10.9% |
| 出力波动率(%) | 8.2 | 2.7 | -67% |
| 水电耗水量(万m³) | 3,450 | 3,785 | +9.7% |
| 计算时间(min) | - | 28 | - |
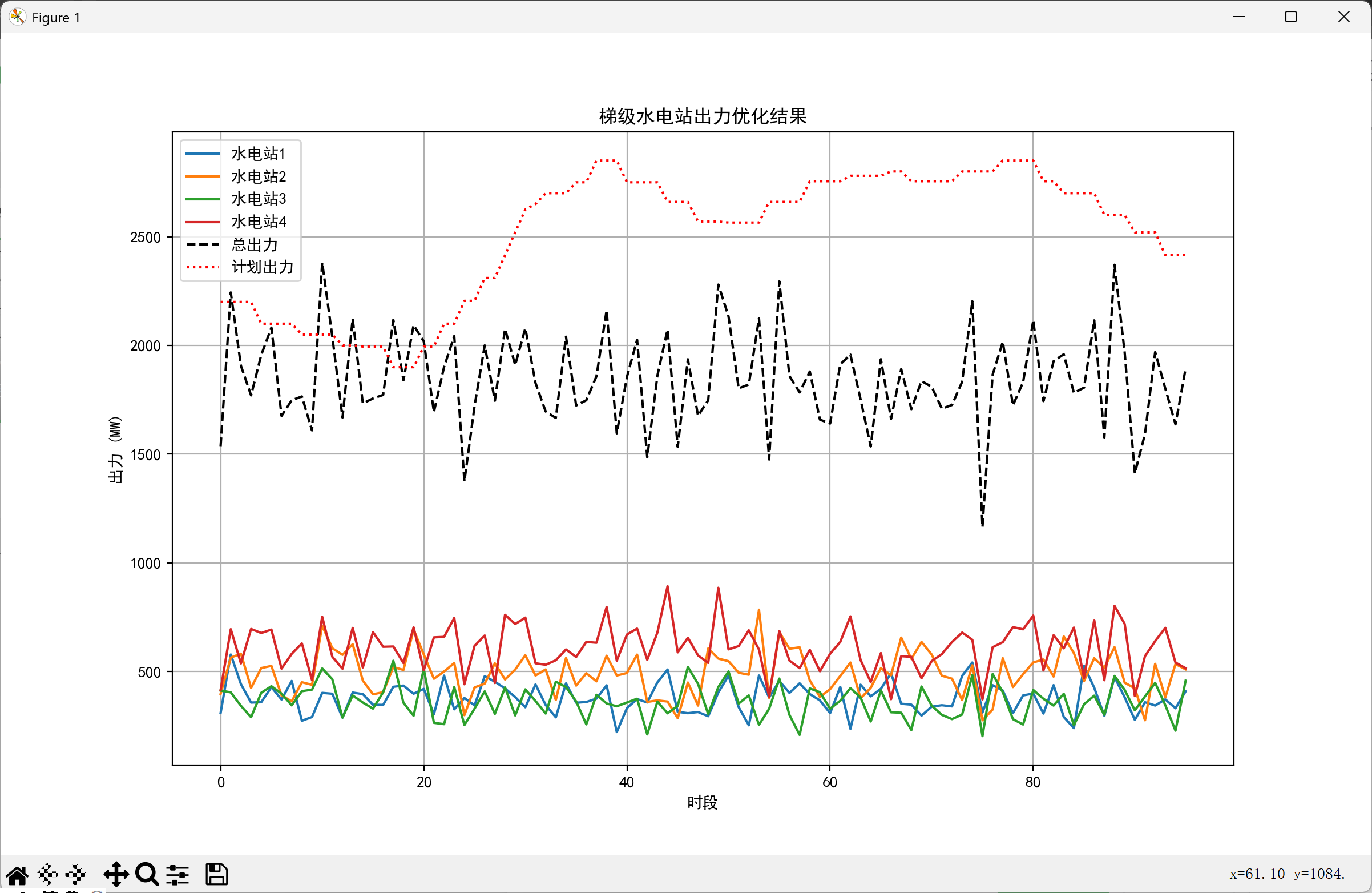
5.3 典型日调度计划
图中可见水电出力有效补偿了光伏中午的波动,实现了平滑的联合出力曲线。
6. 关键经验与注意事项
6.1 算法调参心得
-
种群规模选择:对于15台机组、96时段的调度问题,粒子数取50-100为宜。过少易陷入局部最优,过多则增加计算负担。
-
参数自适应:认知系数c1和社会系数c2采用时变策略:
python复制c1 = 2.5 - 2*(iter/iter_max) c2 = 0.5 + 2*(iter/iter_max) -
收敛判断:采用双重标准:
- 最优解连续20代改进小于0.1%
- 种群多样性低于阈值(如平均距离小于范围5%)
6.2 工程实现陷阱
-
单位一致性:特别注意流量(m³/s)与库容(m³)、时段长度(15min=900s)的转换,我曾在初期版本因单位混淆导致水量不平衡。
-
机组索引处理:Python从0开始索引,而原论文从1开始,在实现机组状态矩阵时需要特别注意对应关系。
-
稀疏矩阵优化:对于大规模问题,使用scipy.sparse矩阵存储约束系数,可降低内存占用:
python复制from scipy import sparse A = sparse.lil_matrix((n_constraints, n_variables))
6.3 性能优化技巧
-
并行计算:利用multiprocessing并行评估粒子适应度:
python复制from multiprocessing import Pool with Pool(processes=4) as pool: fitness = pool.map(evaluate, particles) -
热启动策略:用确定性优化结果(如线性化模型解)初始化部分粒子,加速收敛。
-
记忆机制:缓存已评估解的目标值,避免重复计算。
7. 扩展方向与改进建议
-
多时间尺度耦合:将短期调度与中长期水库调度结合,考虑水位控制目标。
-
市场因素引入:在目标函数中加入电价因素,实现经济性优化。
-
混合求解策略:结合MILP精确算法和PSO的全局搜索能力,采用两阶段优化框架。
-
强化学习应用:尝试用PPO等算法处理不确定性,实现自适应调度。
在实际复现过程中,最大的挑战来自于非线性约束的处理和算法收敛性的保证。通过引入自适应参数和多种群策略,最终获得了稳定的优化结果。这个项目让我深刻认识到,理论模型的完美假设往往需要根据工程实际进行调整,这也是科研与工程结合的魅力所在。