
1. Kafka再平衡:从救火到优雅控场的全链路解析
凌晨三点,监控大屏突然亮起刺眼的红色警报。消费者组每小时触发17次再平衡,消息堆积量突破10万条,整个订单处理系统濒临崩溃。这不是虚构的场景,而是我去年在某电商平台亲身经历的"Kafka惊魂夜"。经过这次教训,我花了三个月时间系统研究Kafka再平衡机制,终于从被动救火转变为主动控场。本文将分享这段从血泪教训到游刃有余的实战历程。
Rebalance(再平衡)是Kafka消费者组的核心调度机制,就像交响乐团的指挥家。当乐团成员变动时(比如有小提琴手迟到或离场),指挥需要重新分配乐谱,确保每个声部都有且只有一个乐手负责。同样地,当消费者组内成员或Topic分区发生变化时,GroupCoordinator会触发再平衡,重新分配分区所有权,保证每个Partition始终只有一个消费者在处理。
2. 再平衡触发机制深度解析
2.1 五大触发场景与底层原理
在实际生产环境中,再平衡主要会在以下五种情况下被触发:
-
消费者实例上下线:这是最常见的触发原因。当消费者因GC停顿、网络抖动或主动下线时,GroupCoordinator通过心跳机制(默认session.timeout.ms=10秒)感知到成员变化。我曾遇到一个典型案例:某服务因Full GC停顿30秒,被误判为下线,导致整个消费者组进入再平衡。
-
Topic分区数变更:当运维执行
kafka-topics --alter --partitions 20命令扩容分区时,元数据变更会立即触发再平衡。去年双11前,我们一个核心Topic从50分区扩容到200分区,引发了长达2分钟的全局停顿。 -
订阅Topic列表变化:使用正则表达式订阅(如
consumer.subscribe(Pattern.compile("order.*")))时,新建匹配的Topic会自动触发再平衡。某次灰度发布时,新创建的order_test Topic意外触发了生产环境的再平衡。 -
消费者组规模变化:无论是手动扩缩容还是K8s滚动更新,组内成员数量变化都会触发再平衡。关键是要遵循"先扩后缩"原则——新增实例稳定后再下线旧实例。
-
GroupCoordinator迁移:当负责协调的Broker节点宕机时,会选举新的Coordinator,此时所有消费者需要重新加入组。这种情况虽然少见,但影响范围最大。
血泪教训:配置
session.timeout.ms时,必须确保它大于消费者的最大可能停顿时间(包括GC时间)。我们现在的标准是:session.timeout.ms ≥ 最大预期GC时间 × 3
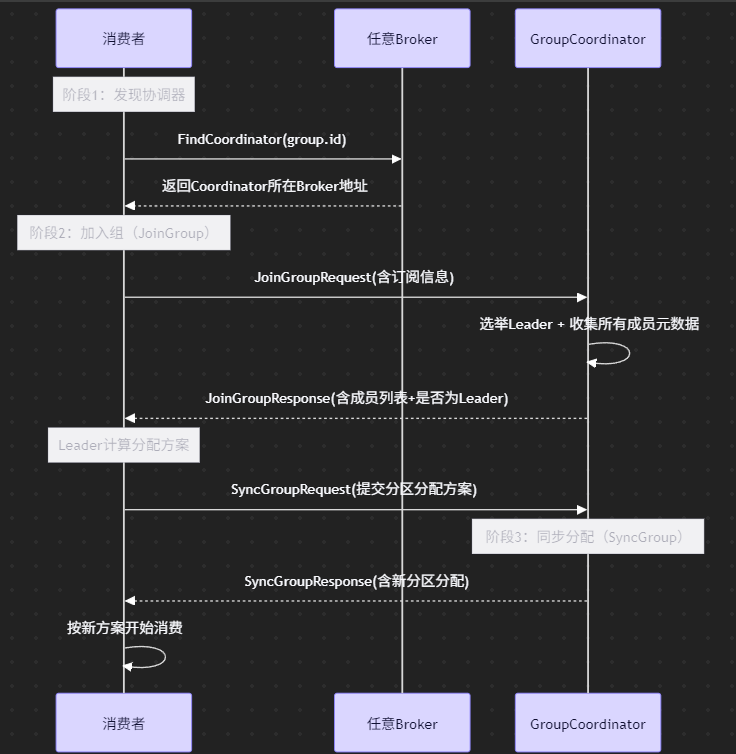
2.2 再平衡三阶段流程详解
再平衡过程可以分为三个关键阶段,每个阶段都可能成为性能瓶颈:
-
JoinGroup阶段:所有消费者向Coordinator发送JoinGroup请求,第一个加入的成员自动成为Leader。这个阶段最危险的是"羊群效应"——所有消费者同时重试可能导致Coordinator过载。我们曾因此遭遇过长达30秒的JoinGroup超时。
-
SyncGroup阶段:Leader消费者计算分配方案(如Range或RoundRobin),其他成员等待同步结果。当分区数达到500+时,这个计算过程可能消耗数秒CPU时间。解决方案是使用更高效的StickyAssignor策略。
-
稳定阶段:各消费者开始从分配到的分区拉取消息。此时如果某些消费者无法及时提交offset,可能触发新一轮再平衡,形成恶性循环。
3. 再平衡引发的四大生产问题
3.1 消费停顿(STW)效应
再平衡期间,所有消费者会暂停消息拉取,直到新分配方案生效。对于高吞吐场景,这种"全局停顿"可能造成严重积压。我们监控系统曾记录到一次15秒的再平衡导致50万条消息堆积。
解决方案:
- 升级到Kafka 2.4+使用增量式再平衡
- 调优
max.poll.interval.ms防止误判 - 实现ConsumerRebalanceListener优雅处理
3.2 消息重复消费
当消费者在onPartitionsRevoked回调中未能及时提交offset时,新分配的消费者会从最后提交位置重新消费。某金融场景下,这导致了重复扣款的严重事故。
根治方案:
java复制consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 同步提交确保offset落盘
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 初始化本地状态
initState(partitions);
}
});
3.3 分区分配不均
默认的RangeAssignor策略可能导致严重的数据倾斜。例如3个消费者消费5个分区时,分配结果可能是2-2-1,而理想状态应该是2-2-1。当分区数达到数百时,这种不均衡会被放大。
策略对比:
| 策略名称 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RangeAssignor | 实现简单 | 容易产生数据倾斜 | 测试环境 |
| RoundRobin | 分配均匀 | 重平衡时变动大 | 小规模稳定集群 |
| StickyAssignor | 变动最小+相对均衡 | 实现复杂度高 | 生产环境首选 |
3.4 滚动发布引发的连锁反应
在K8s环境中,当Pod批量重启时,如果所有实例同时下线,会导致消费者组需要完全重建。更糟糕的是,新启动的消费者可能因为冷启动耗时过长,再次触发再平衡。
发布规范:
- 先扩容新实例(scale up)
- 等待新实例完全加入并稳定运行
- 再缩容旧实例(scale down)
- 整个过程监控
kafka.consumer:type=consumer-coordinator-metrics指标
4. 再平衡优化三重奏
4.1 预防性配置调优
这是减少再平衡的第一道防线。以下是我们经过上百次压测得出的黄金配置:
properties复制# 心跳检测相关(单位毫秒)
session.timeout.ms=30000 # 会话超时时间
heartbeat.interval.ms=10000 # 心跳间隔(≤session.timeout.ms/3)
max.poll.interval.ms=300000 # 最大拉取间隔
# 分配策略与其它
partition.assignment.strategy=org.apache.kafka.clients.consumer.StickyAssignor
enable.auto.commit=false # 必须关闭自动提交
参数调优原则:
session.timeout.ms要大于最大预期GC停顿heartbeat.interval.ms通常设为session.timeout.ms的1/3max.poll.interval.ms根据业务处理耗时设定
4.2 增量式再平衡(Kafka 2.4+)
这是革命性的改进,将再平衡从"全局停顿"变为"渐进式切换"。其核心原理是:
- 消费者在收到再平衡通知时,不需要立即释放分区
- 新分配方案会标注哪些分区需要释放
- 消费者在处理完当前消息后,才释放旧分区并获取新分区
效果对比:
- 传统再平衡:全组停顿2-10秒
- 增量式再平衡:单消费者停顿<100ms
4.3 业务层容错设计
即使再平衡无法完全避免,也可以通过业务设计降低影响:
-
幂等处理:
- 为每条消息生成唯一ID
- 使用Redis SETNX或数据库唯一索引去重
- 实现业务状态机(如订单状态流转)
-
本地缓存加速:
java复制// 在onPartitionsAssigned时预热缓存 public void onPartitionsAssigned(Collection<TopicPartition> partitions) { partitions.forEach(partition -> { long offset = consumer.position(partition); loadCache(partition, offset); }); } -
监控体系:
- 告警规则:
rebalance.rate.per.hour > 5 - 关键指标:
bash复制# 再平衡频率 kafka.consumer:type=consumer-coordinator-metrics,name=rebalance-rate-per-hour # 再平衡耗时 kafka.consumer:type=consumer-coordinator-metrics,name=rebalance-latency-avg
- 告警规则:
5. 生产环境Checklist
5.1 开发规范
- [ ] 消费逻辑中禁止同步RPC调用
- [ ] 实现ConsumerRebalanceListener
- [ ] 单条消息处理超时需小于
max.poll.interval.ms - [ ] 关闭自动提交(auto.commit=false)
5.2 运维规范
- [ ] 变更分区数前确保无消费者在线
- [ ] 滚动发布遵循"先扩后缩"原则
- [ ] 监控再平衡频率和耗时
- [ ] Broker版本≥2.4以支持增量再平衡
5.3 紧急处理流程
- 确认触发原因(查看Broker日志)
- 临时方案:重启消费者组恢复服务
- 长期修复:根据原因调整参数或修改代码
- 验证:通过压测确认问题解决
6. 实战经验分享
在金融级场景中,我们通过以下组合拳将再平衡频率从每小时20次降至0.1次:
-
参数精细化调优:
- 根据GC日志分析设置
session.timeout.ms=45s - 按业务峰值设置
max.poll.interval.ms=5min
- 根据GC日志分析设置
-
架构改造:
- 将大消费者组拆分为多个小组
- 使用静态成员资格(static membership)减少抖动影响
-
全链路监控:
prometheus复制# 再平衡告警规则 - alert: HighRebalanceRate expr: rate(kafka_consumer_rebalance_total[1h]) > 5 for: 10m labels: severity: critical annotations: summary: "High rebalance rate ({{ $value }} times/hour)"
最终我们实现了即使在K8s集群滚动更新期间,消息处理延迟也不超过500ms的SLA目标。这证明只要深入理解机制,再平衡完全可以成为可控的常规操作,而非令人闻风丧胆的"午夜凶铃"。