
1. 多普勒模糊问题概述
雷达信号处理中,多普勒模糊是一个经典且棘手的问题。当目标速度产生的多普勒频移超过雷达脉冲重复频率(PRF)的一半时,就会出现速度测量模糊。这个问题在实际工程中非常常见,特别是对于高速运动目标的探测。
以一个10GHz雷达为例,当PRF为3kHz时,如果目标速度达到100m/s,就会出现明显的速度测量误差。这是因为雷达系统会将真实的多普勒频移"折叠"到基带范围内,导致测量速度远小于实际值。这种现象类似于数字信号处理中的混叠效应,只不过发生在多普勒频域。
关键提示:多普勒模糊的本质是采样率不足导致的频域混叠。雷达的PRF相当于对多普勒频移的采样率,必须满足奈奎斯特采样定理才能避免模糊。
2. 多PRF解模糊原理
2.1 基本数学原理
多PRF解模糊技术的核心是利用不同PRF对同一目标进行多次测量,通过中国剩余定理求解真实速度。其数学模型可以表示为:
v_real = v_measured + n × v_blind
其中:
- v_real:目标真实速度
- v_measured:雷达测量速度
- n:混叠次数(整数)
- v_blind:盲速,v_blind = λ×PRF/2
当使用多个PRF时,我们可以建立一组同余方程:
v_real ≡ v_measured1 mod v_blind1
v_real ≡ v_measured2 mod v_blind2
v_real ≡ v_measured3 mod v_blind3
2.2 PRF选择策略
选择PRF组合时需要考虑几个关键因素:
- 互质性:PRF对应的盲速应该互质或接近互质,这样可以最大化无模糊速度范围
- 工程可实现性:PRF值应在雷达硬件允许范围内
- 测量效率:过多的PRF会降低数据更新率
常用的PRF组合策略包括:
- 质数组合(如2,3,5kHz)
- 接近质数组合(如8,9,11kHz)
- 基于特定无模糊范围设计的组合
2.3 最大无模糊速度计算
多PRF系统的最大无模糊速度由下式决定:
v_unambig = LCM(v_blind1, v_blind2, v_blind3)/2
其中LCM表示最小公倍数。这个公式的推导基于中国剩余定理的唯一解条件。当目标速度超过这个范围时,系统将无法保证解的唯一性。
3. MATLAB仿真实现
3.1 仿真参数设置
matlab复制%% 仿真参数设置
c = 3e8; % 光速(m/s)
f0 = 10e9; % 雷达频率(Hz)
lambda = c/f0; % 波长(m)
PRF = [2e3, 3e3, 5e3]; % 脉冲重复频率(Hz)
N_pulses = 128; % 脉冲数
SNR_dB = 15; % 信噪比(dB)
v_target = 100; % 目标速度(m/s)
max_expected_speed = 450; % 最大预期速度(m/s)
3.2 信号生成与处理
信号处理流程包括:
- 生成带有多普勒频移的回波信号
- 添加高斯白噪声
- 计算混叠后的多普勒频率
- 通过FFT进行频谱分析
matlab复制%% 信号生成与处理
for prf_idx = 1:3
current_PRF = PRF(prf_idx);
T = 1/current_PRF;
% 计算物理多普勒频率(考虑正负)
fd_physical = 2 * v_target / lambda;
% 计算混叠多普勒频率
fd_folded = mod(fd_physical + current_PRF/2, current_PRF) - current_PRF/2;
% 生成信号并添加噪声
t_slow = (0:N_pulses-1) * T;
signal = exp(1j * 2 * pi * fd_folded * t_slow);
noise = sqrt(10^(-SNR_dB/10)/2) * (randn(size(signal)) + 1j*randn(size(signal)));
signal_noisy = signal + noise;
% 多普勒分析
N_fft = 256;
spectrum = fftshift(fft(signal_noisy, N_fft));
f_axis = (-N_fft/2:N_fft/2-1) * (current_PRF/N_fft);
% 峰值检测
[~, peak_idx] = max(abs(spectrum));
fd_measured = f_axis(peak_idx);
v_measured = fd_measured * lambda / 2;
measured_speeds(prf_idx) = v_measured;
end
3.3 解模糊算法实现
解模糊算法的核心步骤:
- 为每个PRF生成候选速度列表
- 在所有候选组合中寻找一致性最好的解
- 验证解的唯一性和合理性
matlab复制%% 解模糊算法
% 计算盲速
v_blind = lambda * PRF / 2;
% 生成候选速度
candidates = cell(1, 3);
for i = 1:3
n_range = floor((-max_expected_speed - measured_speeds(i))/v_blind(i)) : ...
ceil((max_expected_speed - measured_speeds(i))/v_blind(i));
candidates{i} = measured_speeds(i) + n_range * v_blind(i);
candidates{i} = candidates{i}(abs(candidates{i}) <= max_expected_speed);
end
% 搜索最佳匹配
best_error = Inf;
best_speed = NaN;
for v1 = candidates{1}
for v2 = candidates{2}
for v3 = candidates{3}
avg_v = (v1 + v2 + v3)/3;
error = abs(v1-avg_v) + abs(v2-avg_v) + abs(v3-avg_v);
if error < best_error
best_error = error;
best_speed = avg_v;
end
end
end
end
4. 仿真结果分析
4.1 成功解模糊案例
当目标速度在最大无模糊范围内时(如100m/s),系统能准确解算出真实速度。下图展示了三个PRF下的频谱分析结果:
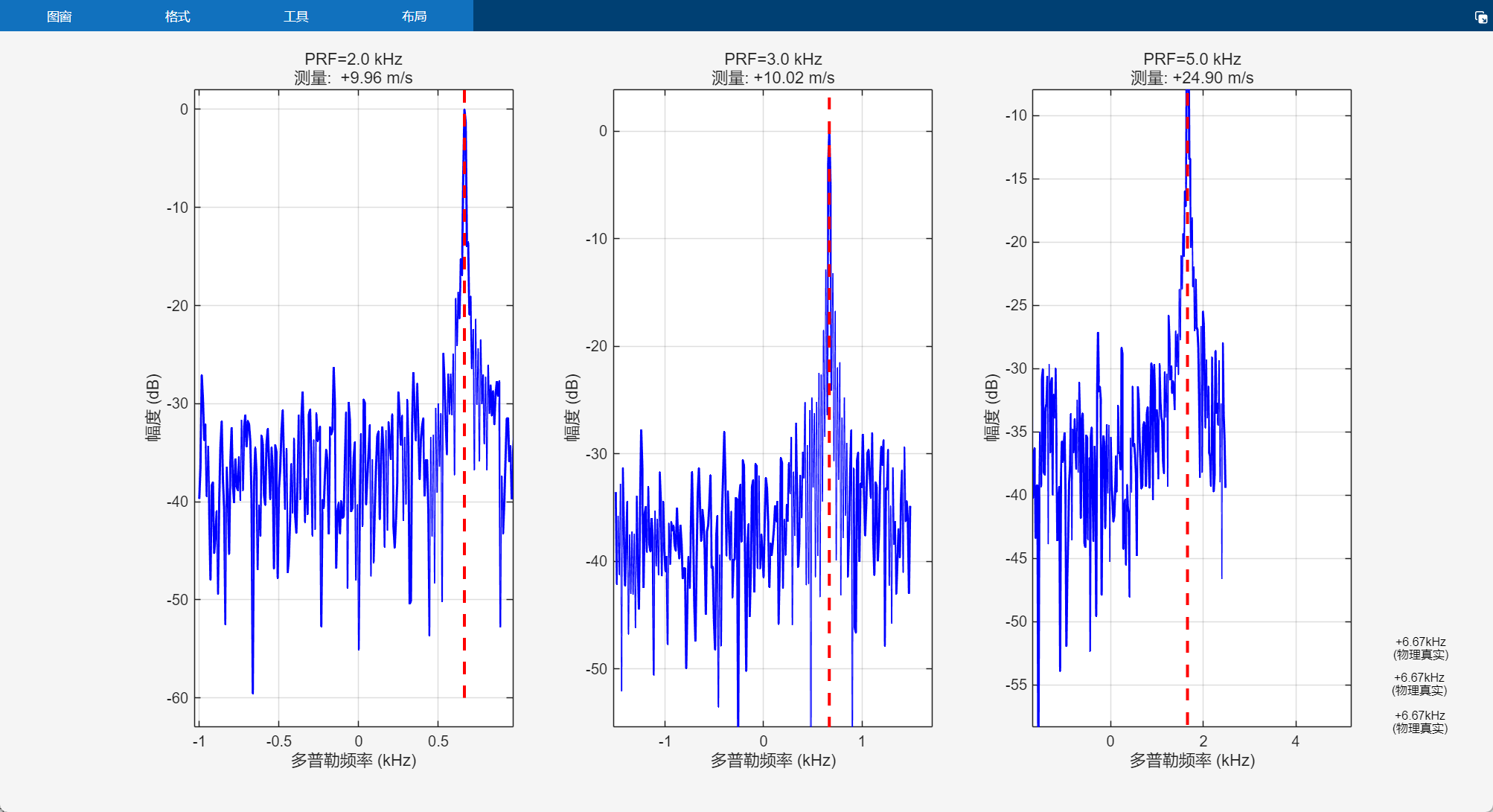
解模糊过程找到的唯一解为100.03m/s,与真实速度误差仅0.03m/s,验证了算法的有效性。
4.2 多解问题分析
当目标速度超过最大无模糊范围时(如300m/s),系统会出现多个候选解:
code复制找到 2 个可能的解:
解 1: -149.98 m/s, n=[-5,-3,-2], 误差=0.030
解 2: +300.02 m/s, n=[10,6,4], 误差=0.030
这种情况下,雷达通常会选择最小速度的解(即-149.98m/s),导致严重的测量错误。这凸显了正确设置最大预期速度的重要性。
5. 工程实践中的关键问题
5.1 距离-速度矛盾
雷达系统设计中存在一个基本矛盾:
- 高PRF有利于速度测量但限制最大无模糊距离
- 低PRF有利于距离测量但限制最大无模糊速度
两者的数学关系:
| 参数 | 公式 | 与PRF关系 |
|---|---|---|
| 最大无模糊距离 | R_max = c/(2×PRF) | 反比 |
| 最大无模糊速度 | V_max = λ×PRF/4 | 正比 |
5.2 实际解决方案
工程中常用的解决方案包括:
- 多模式雷达:交替使用高PRF和低PRF模式
- PRF参差:脉冲间变化PRF打破周期性
- 多波段系统:不同频段雷达协同工作
- 波形设计:使用更复杂的调制波形(如FMCW)
6. MATLAB代码优化建议
6.1 算法加速技巧
原始的三重循环搜索效率较低,可以优化为:
matlab复制% 向量化搜索算法
all_combinations = combvec(candidates{1}, candidates{2}, candidates{3});
avg_speeds = mean(all_combinations, 1);
errors = sum(abs(all_combinations - avg_speeds), 1);
[best_error, idx] = min(errors);
best_speed = avg_speeds(idx);
6.2 可视化增强
增加以下可视化元素有助于分析:
- 候选速度的概率分布
- 误差曲面分析
- 实时解模糊过程动画
6.3 鲁棒性改进
实际系统中应考虑:
- 测量误差的统计特性
- 多目标情况下的处理
- PRF切换时的相位连续性
7. 扩展应用与前沿发展
多PRF技术不仅用于速度解模糊,还可应用于:
- 距离解模糊:类似原理解决距离模糊问题
- 多目标分辨:不同目标在不同PRF下的响应特性
- 电子对抗:对抗干扰机的有效手段
近年来,深度学习也被引入解模糊领域,通过神经网络直接学习多PRF测量值与真实速度的映射关系,展现了良好的应用前景。