
1. 项目概述与核心价值
最近在团队内部落地了一套基于Arbess和GitLab的Node.js自动化部署方案,整个过程踩了不少坑,也积累了一些实战经验。这套方案最大的优势在于完全私有化部署,零成本实现从代码提交到生产环境部署的全流程自动化。特别适合中小团队在预算有限的情况下搭建自己的CI/CD流水线。
Arbess作为一款新兴的开源CI/CD工具,最吸引我的地方是它的"零配置"理念。相比Jenkins复杂的插件系统和配置项,Arbess通过可视化流水线设计器大幅降低了使用门槛。实测下来,从安装到运行第一个流水线,整个过程不超过30分钟。配合GitLab的代码托管能力,可以快速搭建起一套完整的自动化部署体系。
这个方案特别适合以下场景:
- 需要私有化部署CI/CD工具的中小团队
- Node.js项目的自动化构建与部署
- 多环境(开发/测试/生产)的自动化发布
- 希望降低运维复杂度的前端/全栈团队
2. 环境准备与工具安装
2.1 GitLab服务器搭建
2.1.1 系统环境配置
我选择CentOS 9作为GitLab的宿主系统,主要考虑其长期支持周期和企业级稳定性。在开始安装前,有几个关键的系统配置需要注意:
bash复制# 更新系统并安装基础依赖
sudo yum update -y
sudo yum install -y curl policycoreutils-python-utils openssh-server perl
sudo systemctl enable --now sshd
注意:如果是在云服务器上部署,建议先配置好安全组规则,开放SSH(22)、HTTP(80)、HTTPS(443)端口。生产环境强烈建议使用HTTPS,可以提前准备域名和SSL证书。
2.1.2 GitLab安装细节
官方提供了多种安装方式,我选择RPM包安装,因为这种方式:
- 自动处理所有依赖关系
- 包含完整的服务管理脚本
- 便于后续升级维护
下载特定版本的安装包(这里以17.7.0为例):
bash复制curl -LO https://packages.gitlab.cn/repository/el/8/gitlab-jh-17.7.0-jh.0.el8.x86_64.rpm
安装时需要指定外部访问URL,这个配置后续修改比较麻烦,建议一开始就设置正确:
bash复制export EXTERNAL_URL="http://your-server-ip"
sudo rpm -ivh gitlab-jh-17.7.0-jh.0.el8.x86_64.rpm
安装完成后,有几个关键检查点:
- 服务状态检查:
sudo gitlab-ctl status应该显示所有服务均为"run" - 初始密码获取:
sudo cat /etc/gitlab/initial_root_password查看root用户初始密码 - 防火墙配置:确保80端口开放
sudo firewall-cmd --permanent --add-service=http
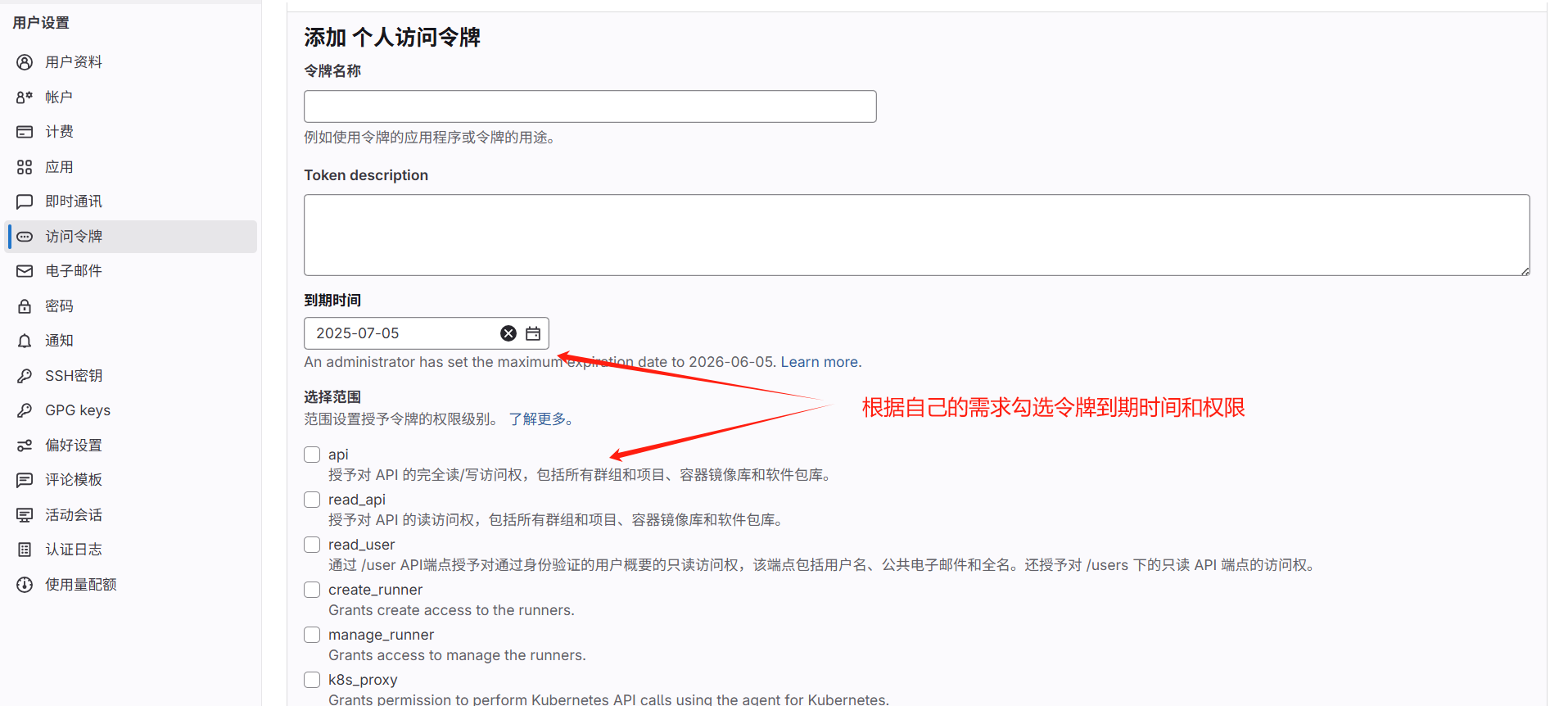
2.1.3 访问令牌创建
为了让Arbess能够访问GitLab仓库,需要创建个人访问令牌。这个步骤有几个注意事项:
-
令牌权限选择:
- api (必须)
- read_repository (必须)
- write_repository (如果需要推送)
-
令牌有效期设置:
- 测试环境可以设置较长有效期
- 生产环境建议设置短有效期并定期轮换
-
令牌安全存储:
- 创建后立即复制保存
- 不要直接写在配置文件中
- 可以考虑使用密码管理工具
2.2 Arbess安装与初始化
2.2.1 系统要求检查
在安装Arbess前,建议检查服务器是否符合以下要求:
- 内存:至少4GB(8GB推荐)
- 磁盘空间:20GB以上
- 操作系统:CentOS 7/8/9
- 网络:稳定的互联网连接(用于下载依赖)
2.2.2 安装过程详解
从官网下载最新RPM包后,安装过程非常简单:
bash复制rpm -ivh tiklab-arbess-x.x.x.rpm
安装完成后,Arbess会自动创建以下目录结构:
code复制/opt/tiklab-arbess/
├── bin/ # 启动脚本
├── conf/ # 配置文件
├── logs/ # 日志文件
└── plugins/ # 插件目录
启动服务的正确姿势:
bash复制cd /opt/tiklab-arbess/bin
./arbess start
常见问题:如果启动失败,可以检查/opt/tiklab-arbess/logs/arbess.log中的错误信息。最常见的问题是端口冲突(默认9200)或内存不足。
2.2.3 初始登录与安全配置
首次访问http://ip:9200 使用默认凭证admin/123456登录后,应该立即:
- 修改管理员密码
- 配置SMTP邮件通知(可选但推荐)
- 设置系统时区
3. 流水线设计与实现
3.1 GitLab源码集成
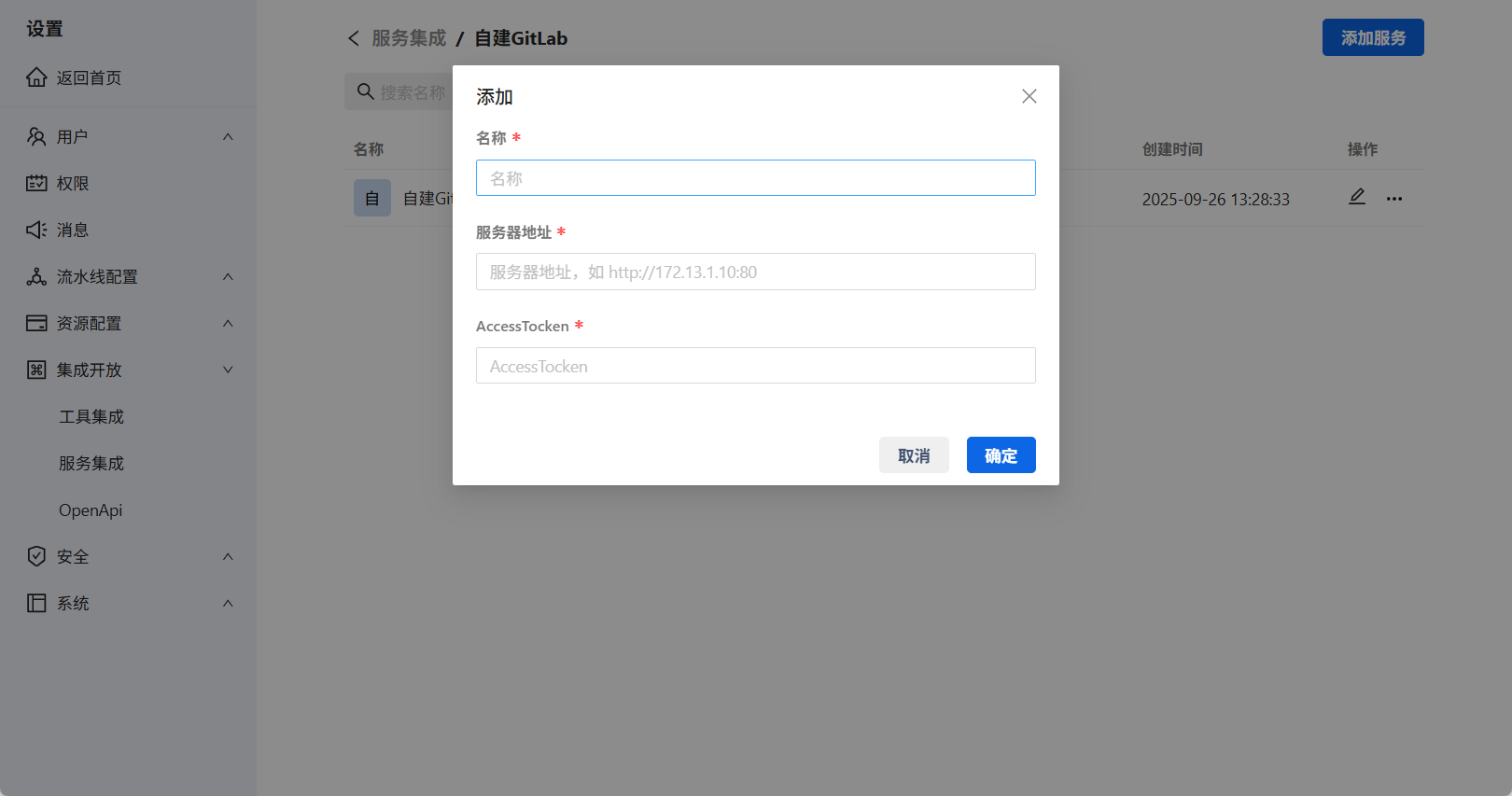
3.1.1 服务集成配置
在系统设置→集成与开放→服务集成页面添加GitLab服务时,有几个关键字段需要注意:
- 服务地址:如果是自建GitLab,确保填写完整的base URL(包括http://或https://)
- Access Token:使用之前创建的GitLab个人访问令牌
- 授权类型:选择"自建Gitlab"
3.1.2 源码任务配置技巧
创建GitLab源码任务时,有几个实用技巧:
- 分支名称可以使用变量,如${GIT_BRANCH},方便多环境部署
- 对于大型仓库,可以启用"浅克隆"加快速度
- 子模块支持需要额外配置.gitmodules文件
markdown复制| 参数 | 推荐配置 | 注意事项 |
|---------------|-----------------------------------|-----------------------------|
| Git版本 | /usr/bin/git | 确保路径正确 |
| 克隆深度 | 1(仅最新提交) | 历史构建可能需要完整历史 |
| 清理工作空间 | 是 | 避免残留文件影响后续构建 |
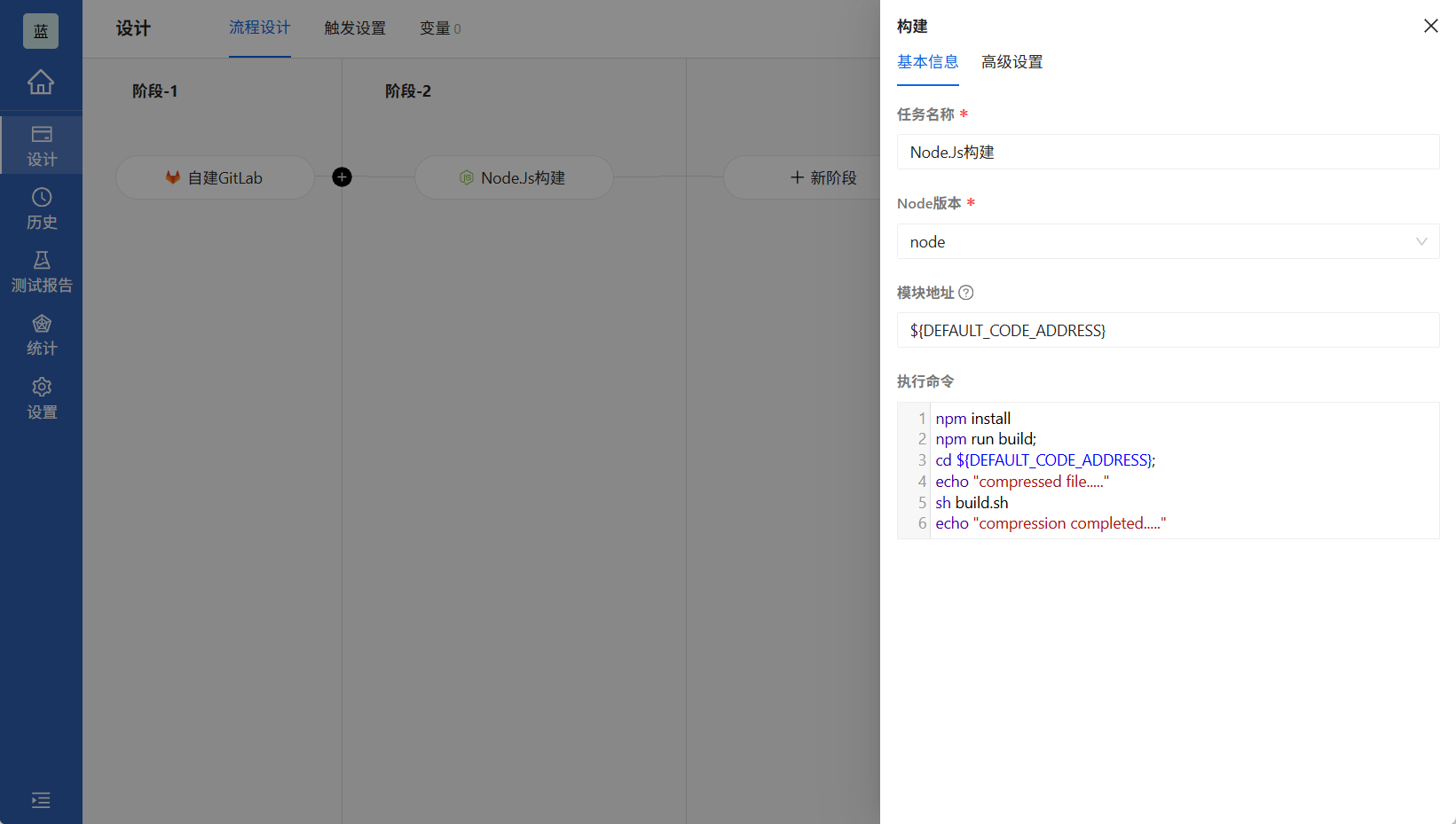
3.2 Node.js构建配置
3.2.1 构建环境准备
在配置Node.js构建任务前,需要确保:
- 目标服务器已安装Node.js(建议使用nvm管理多版本)
- npm或yarn可用
- 构建依赖能够正常下载(网络策略允许)
构建任务的关键配置项:
- Node版本路径:如/usr/local/nvm/versions/node/v16.14.0/bin/node
- 模块地址:通常保持默认$
- 执行命令:根据项目类型可能包括:
bash复制npm install npm run build npm test
3.2.2 构建优化技巧
-
缓存策略:
- 对node_modules启用缓存
- 缓存key可以包含package-lock.json哈希值
-
构建并行化:
- 对大项目可以拆分build和test阶段
- 使用npm-run-all等工具并行执行独立任务
-
环境变量管理:
- 区分development/staging/production环境
- 敏感信息使用Arbess的变量管理功能
3.3 多主机部署策略
3.3.1 主机认证配置
在配置主机部署前,需要确保:
- 目标主机已配置SSH密钥认证
- 部署用户有足够的权限
- 防火墙规则允许相关端口
Arbess支持两种认证方式:
- 密码认证(不推荐)
- SSH密钥认证(推荐)
安全提示:生产环境务必使用SSH密钥认证,并限制部署用户的权限(可以通过sudoers精细控制)
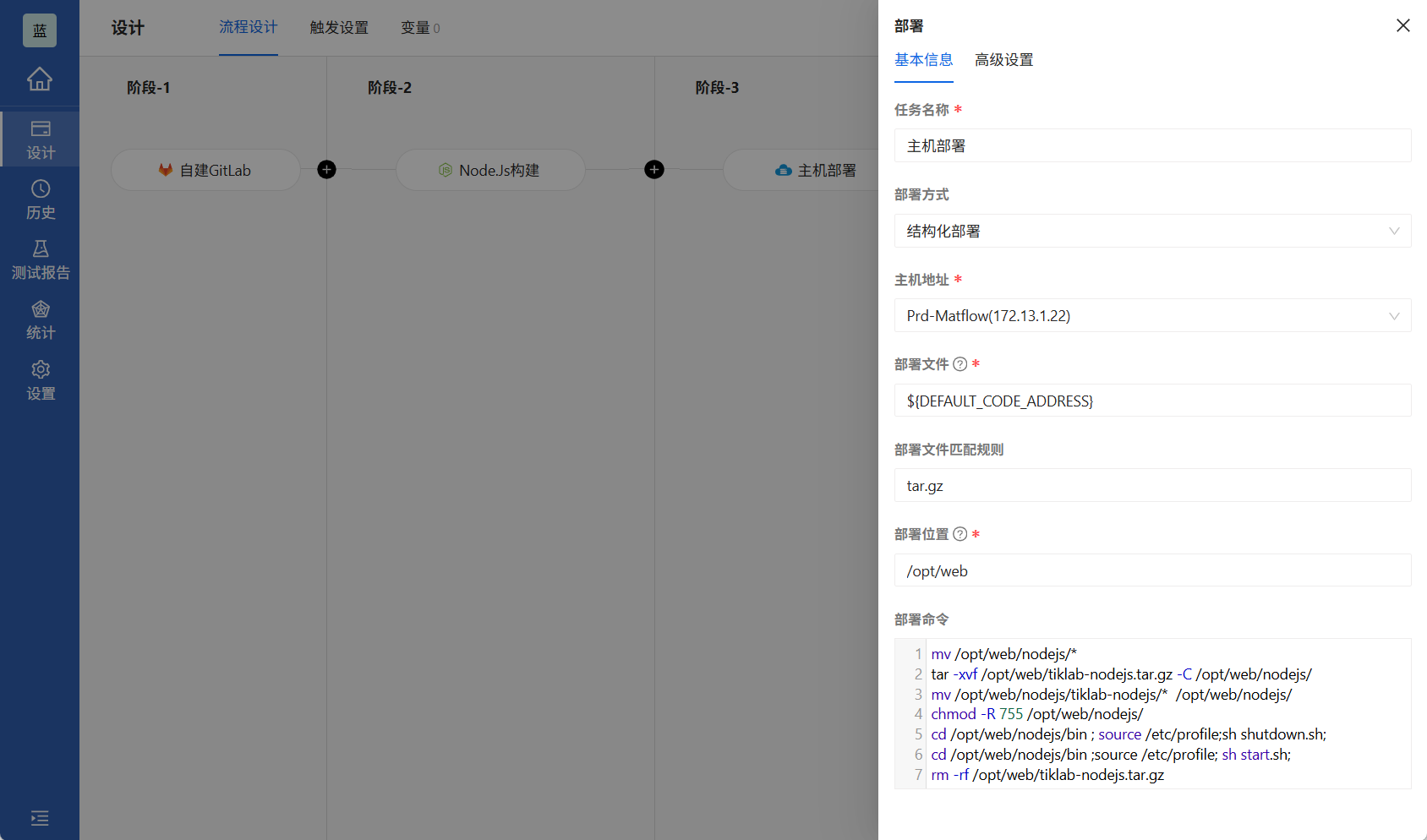
3.3.2 部署任务详解
主机部署任务有几个关键参数需要特别注意:
-
部署文件匹配规则:
- 支持通配符(如dist/*.js)
- 支持正则表达式(如^.*.(js|css)$)
-
部署位置:
- 确保目标目录存在且可写
- 建议使用绝对路径(如/var/www/app)
-
部署命令:
- 可以包含服务重启指令
- 支持多命令(用&&或;连接)
markdown复制| 场景 | 部署文件规则 | 典型部署命令 |
|---------------------|-----------------------|----------------------------------|
| 静态资源部署 | dist/** | rsync -avz dist/ /var/www/html |
| Node.js应用部署 | package.json | npm install && pm2 restart app |
| 配置文件部署 | config/*.json | chmod 600 config/*.json |
4. 流水线运行与优化
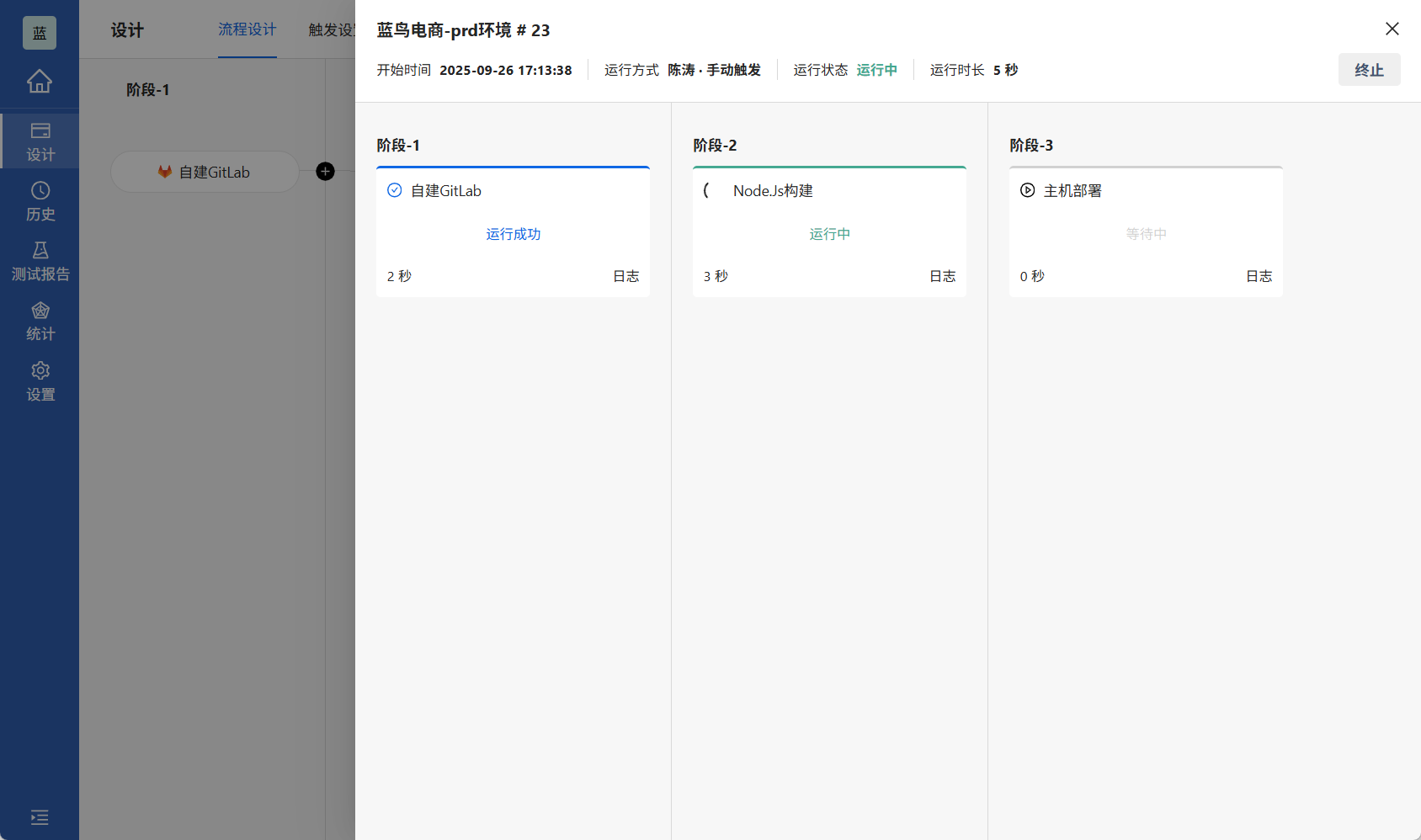
4.1 首次运行与问题排查
4.1.1 常见初运行问题
第一次运行流水线时,可能会遇到以下典型问题:
-
源码拉取失败:
- 检查GitLab令牌权限
- 验证仓库URL是否正确
- 确认分支存在
-
构建失败:
- Node版本不兼容
- 网络问题导致npm install失败
- 构建脚本错误
-
部署失败:
- SSH认证失败
- 目标目录权限不足
- 磁盘空间不足
4.1.2 日志分析技巧
Arbess提供了详细的运行日志,分析时应该:
- 关注错误级别(ERROR > WARN > INFO)
- 检查时间戳确认问题发生时间点
- 使用"详细日志"查看完整上下文
4.2 性能优化实践
4.2.1 构建阶段优化
-
依赖缓存:
bash复制# 在package.json所在目录缓存node_modules if [ -d "node_modules" ]; then echo "Using cached node_modules" else npm install fi -
并行测试:
bash复制npm run test:unit & npm run test:e2e -
增量构建:
bash复制
npm run build -- --watch
4.2.2 部署阶段优化
-
增量部署:
- 使用rsync代替scp
- 只同步变化的文件
-
蓝绿部署:
- 维护两套环境切换
- 通过符号链接快速回滚
-
健康检查:
bash复制# 部署后检查服务是否健康 curl -If http://localhost:3000/health
4.3 高级功能探索
4.3.1 条件触发与审批
-
分支过滤:
- 仅master分支触发生产部署
- feature/*分支只运行测试
-
人工审批:
- 生产部署前需要人工确认
- 结合钉钉/企业微信通知
4.3.2 监控与告警
-
集成Prometheus:
- 暴露构建指标
- 监控流水线健康度
-
失败告警:
- 配置邮件/SMS通知
- 设置失败重试策略
5. 实战经验与避坑指南
在实际部署这套方案的过程中,我总结了以下几个关键经验点:
-
版本一致性很重要:
- 确保开发、构建、生产环境的Node.js版本一致
- 使用.nvmrc或engines字段锁定版本
-
敏感信息管理:
- 不要将凭据硬编码在配置文件中
- 使用Arbess的加密变量功能
- 定期轮换访问令牌
-
资源隔离考虑:
- 生产环境流水线使用独立执行器
- 为不同项目创建独立的GitLab仓库
-
备份策略:
- 定期备份GitLab数据
- 导出Arbess流水线配置
-
文档化:
- 记录所有自定义配置
- 维护部署手册和应急流程
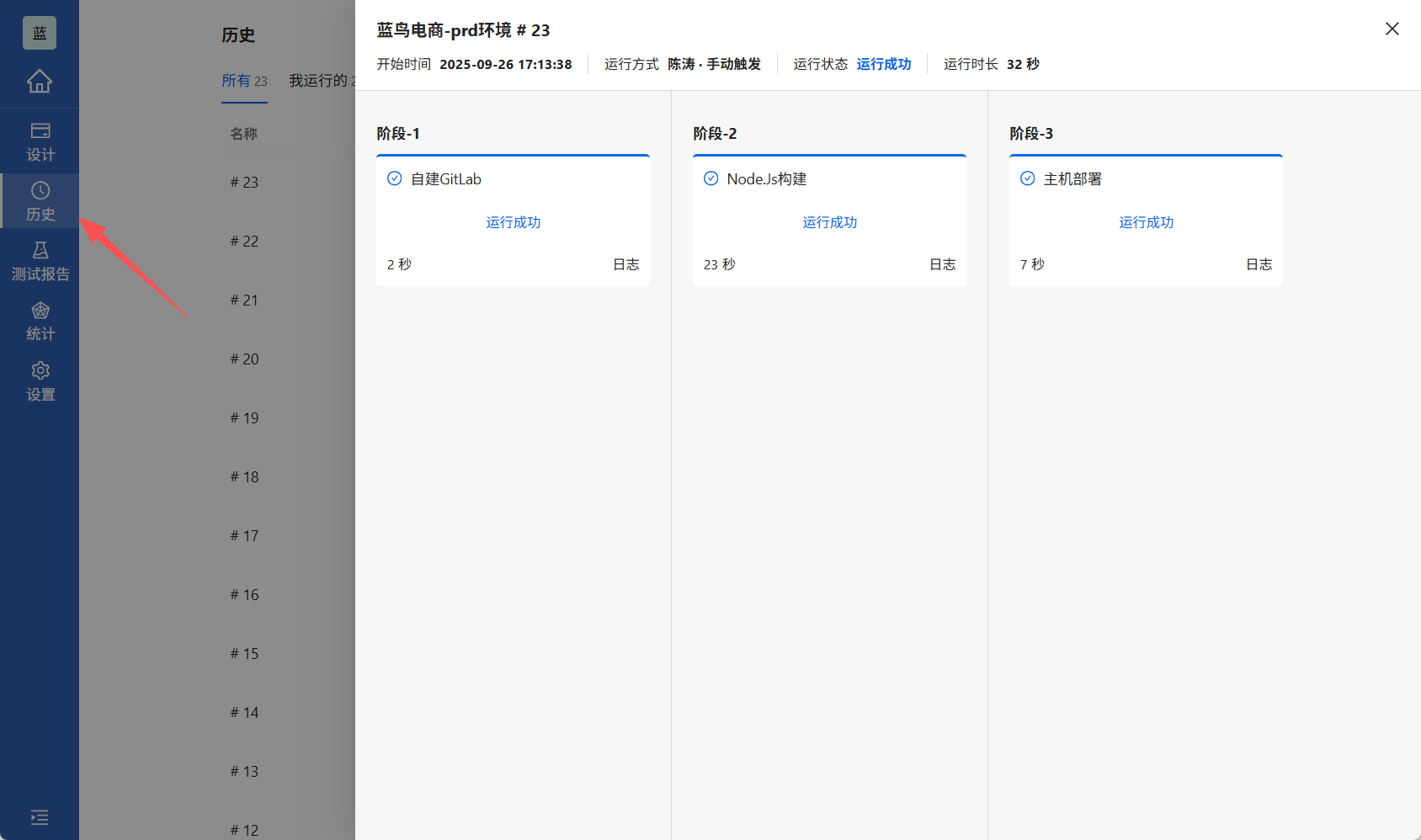
这套方案已经在我们的生产环境稳定运行了6个月,平均部署时间从原来手工部署的15分钟降低到2分钟,部署成功率从85%提升到99.5%。最大的收获不仅是效率提升,更重要的是建立了标准化的发布流程,让团队能够更专注于业务开发而非运维工作。